 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEHRMamba: Towards Generalizable and Scalable Foundation Models for Electronic Health Records
Paper and Code
May 23, 2024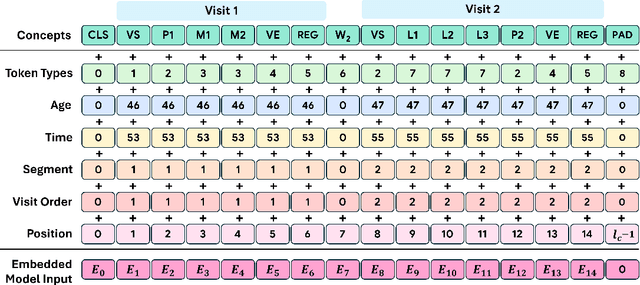
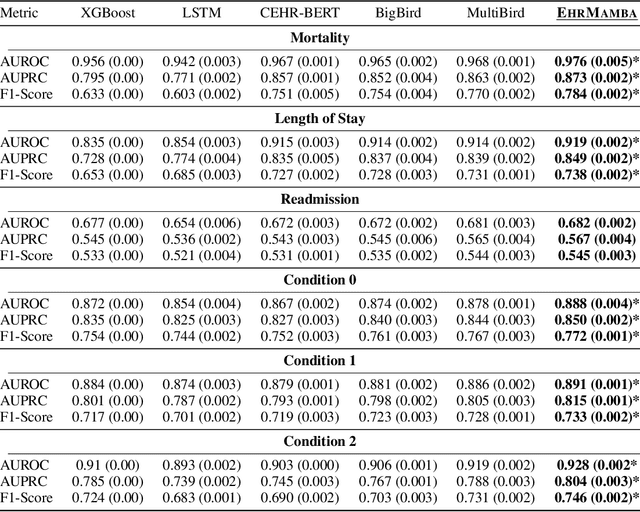
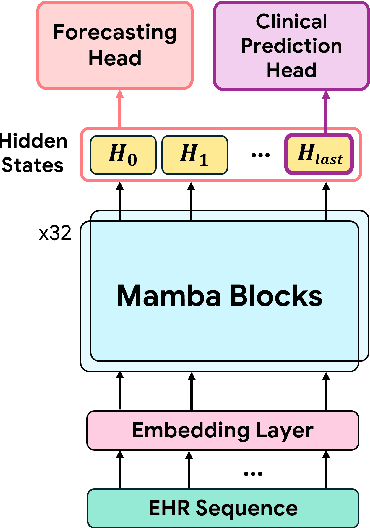
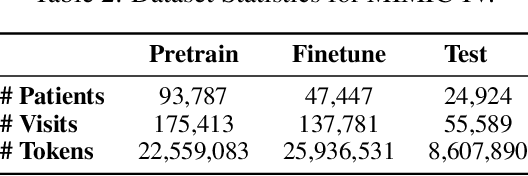
Transformers have significantly advanced the modeling of Electronic Health Records (EHR), yet their deployment in real-world healthcare is limited by several key challenges. Firstly, the quadratic computational cost and insufficient context length of these models pose significant obstacles for hospitals in processing the extensive medical histories typical in EHR data. Additionally, existing models employ separate finetuning for each clinical task, complicating maintenance in healthcare environments. Moreover, these models focus exclusively on either clinical prediction or EHR forecasting, lacking the flexibility to perform well across both. To overcome these limitations, we introduce EHRMamba, a robust foundation model built on the Mamba architecture. EHRMamba can process sequences up to four times longer than previous models due to its linear computational cost. We also introduce a novel approach to Multitask Prompted Finetuning (MTF) for EHR data, which enables EHRMamba to simultaneously learn multiple clinical tasks in a single finetuning phase, significantly enhancing deployment and cross-task generalization. Furthermore, our model leverages the HL7 FHIR data standard to simplify integration into existing hospital systems. Alongside EHRMamba, we open-source Odyssey, a toolkit designed to support the development and deployment of EHR foundation models, with an emphasis on data standardization and interpretability. Our evaluations on the MIMIC-IV dataset demonstrate that EHRMamba advances state-of-the-art performance across 6 major clinical tasks and excels in EHR forecasting, marking a significant leap forward in the field.