 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Medical Representation Learning Through High-Quality Data
Mar 18, 2025Despite the growing scale of medical Vision-Language datasets, the impact of dataset quality on model performance remains under-explored. We introduce Open-PMC, a high-quality medical dataset from PubMed Central, containing 2.2 million image-text pairs, enriched with image modality annotations, subfigures, and summarized in-text references. Notably, the in-text references provide richer medical context, extending beyond the abstract information typically found in captions. Through extensive experiments, we benchmark Open-PMC against larger datasets across retrieval and zero-shot classification tasks. Our results show that dataset quality-not just size-drives significant performance gains. We complement our benchmark with an in-depth analysis of feature representation. Our findings highlight the crucial role of data curation quality in advancing multimodal medical AI. We release Open-PMC, along with the trained models and our codebase.
A Shared Encoder Approach to Multimodal Representation Learning
Mar 03, 2025Multimodal representation learning has demonstrated remarkable potential in enabling models to process and integrate diverse data modalities, such as text and images, for improved understanding and performance. While the medical domain can benefit significantly from this paradigm, the scarcity of paired multimodal data and reliance on proprietary or pretrained encoders pose significant challenges. In this work, we present a shared encoder framework for multimodal representation learning tailored to the medical domain. Our approach employs a single set of encoder parameters shared across modalities, augmented with learnable modality features. Empirical results demonstrate that our shared encoder idea achieves superior performance compared to separate modality-specific encoders, demonstrating improved generalization in data-constrained settings. Notably, the performance gains are more pronounced with fewer training examples, underscoring the efficiency of our shared encoder framework for real-world medical applications with limited data. Our code and experiment setup are available at https://github.com/VectorInstitute/shared_encoder.
ViLBias: A Framework for Bias Detection using Linguistic and Visual Cues
Dec 22, 2024



The integration of Large Language Models (LLMs) and Vision-Language Models (VLMs) opens new avenues for addressing complex challenges in multimodal content analysis, particularly in biased news detection. This study introduces ViLBias, a framework that leverages state of the art LLMs and VLMs to detect linguistic and visual biases in news content, addressing the limitations of traditional text-only approaches. Our contributions include a novel dataset pairing textual content with accompanying visuals from diverse news sources and a hybrid annotation framework, combining LLM-based annotations with human review to enhance quality while reducing costs and improving scalability. We evaluate the efficacy of LLMs and VLMs in identifying biases, revealing their strengths in detecting subtle framing and text-visual inconsistencies. Empirical analysis demonstrates that incorporating visual cues alongside text enhances bias detection accuracy by 3 to 5 %, showcasing the complementary strengths of LLMs in generative reasoning and Small Language Models (SLMs) in classification. This study offers a comprehensive exploration of LLMs and VLMs as tools for detecting multimodal biases in news content, highlighting both their potential and limitations. Our research paves the way for more robust, scalable, and nuanced approaches to media bias detection, contributing to the broader field of natural language processing and multimodal analysis. (The data and code will be made available for research purposes).
Benchmarking Vision-Language Contrastive Methods for Medical Representation Learning
Jun 11, 2024



We perform a comprehensive benchmarking of contrastive frameworks for learning multimodal representations in the medical domain. Through this study, we aim to answer the following research questions: (i) How transferable are general-domain representations to the medical domain? (ii) Is multimodal contrastive training sufficient, or does it benefit from unimodal training as well? (iii) What is the impact of feature granularity on the effectiveness of multimodal medical representation learning? To answer these questions, we investigate eight contrastive learning approaches under identical training setups, and train them on 2.8 million image-text pairs from four datasets, and evaluate them on 25 downstream tasks, including classification (zero-shot and linear probing), image-to-text and text-to-image retrieval, and visual question-answering. Our findings suggest a positive answer to the first question, a negative answer to the second question, and the benefit of learning fine-grained features. Finally, we make our code publicly available.
Global Wheat Challenge 2020: Analysis of the competition design and winning models
May 13, 2021
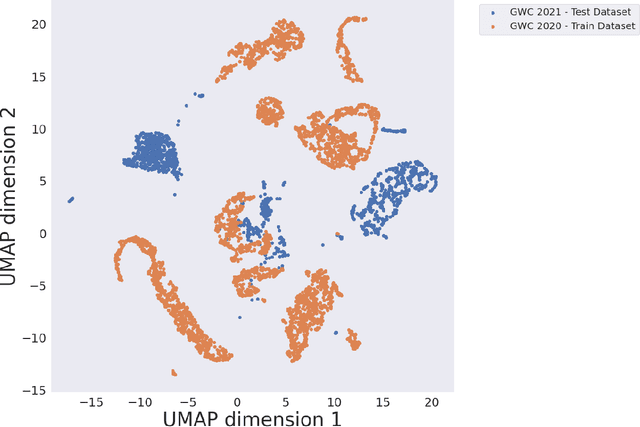

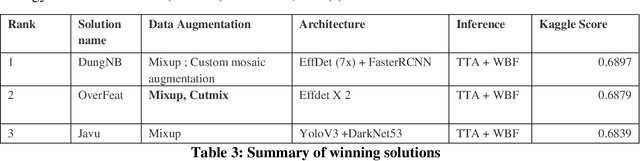
Data competitions have become a popular approach to crowdsource new data analysis methods for general and specialized data science problems. In plant phenotyping, data competitions have a rich history, and new outdoor field datasets have potential for new data competitions. We developed the Global Wheat Challenge as a generalization competition to see if solutions for wheat head detection from field images would work in different regions around the world. In this paper, we analyze the winning challenge solutions in terms of their robustness and the relative importance of model and data augmentation design decisions. We found that the design of the competition influence the selection of winning solutions and provide recommendations for future competitions in an attempt to garner more robust winning solutions.