 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational quantization for state space models
Apr 17, 2024



Forecasting tasks using large datasets gathering thousands of heterogeneous time series is a crucial statistical problem in numerous sectors. The main challenge is to model a rich variety of time series, leverage any available external signals and provide sharp predictions with statistical guarantees. In this work, we propose a new forecasting model that combines discrete state space hidden Markov models with recent neural network architectures and training procedures inspired by vector quantized variational autoencoders. We introduce a variational discrete posterior distribution of the latent states given the observations and a two-stage training procedure to alternatively train the parameters of the latent states and of the emission distributions. By learning a collection of emission laws and temporarily activating them depending on the hidden process dynamics, the proposed method allows to explore large datasets and leverage available external signals. We assess the performance of the proposed method using several datasets and show that it outperforms other state-of-the-art solutions.
HERMES: Hybrid Error-corrector Model with inclusion of External Signals for nonstationary fashion time series
Feb 15, 2022
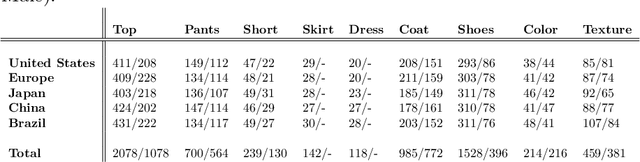


Developing models and algorithms to draw causal inference for time series is a long standing statistical problem. It is crucial for many applications, in particular for fashion or retail industries, to make optimal inventory decisions and avoid massive wastes. By tracking thousands of fashion trends on social media with state-of-the-art computer vision approaches, we propose a new model for fashion time series forecasting. Our contribution is twofold. We first provide publicly the first fashion dataset gathering 10000 weekly fashion time series. As influence dynamics are the key of emerging trend detection, we associate with each time series an external weak signal representing behaviors of influencers. Secondly, to leverage such a complex and rich dataset, we propose a new hybrid forecasting model. Our approach combines per-time-series parametric models with seasonal components and a global recurrent neural network to include sporadic external signals. This hybrid model provides state-of-the-art results on the proposed fashion dataset, on the weekly time series of the M4 competition, and illustrates the benefit of the contribution of external weak signals.
Extending the WILDS Benchmark for Unsupervised Adaptation
Dec 09, 2021

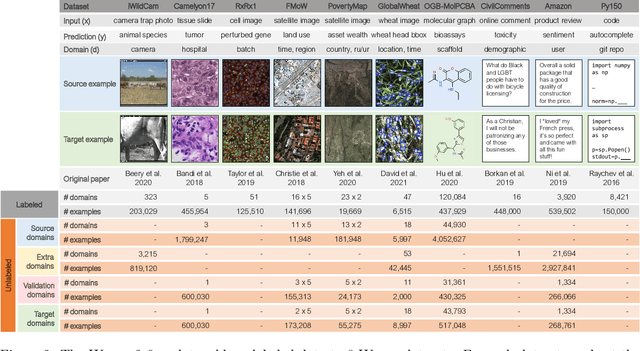
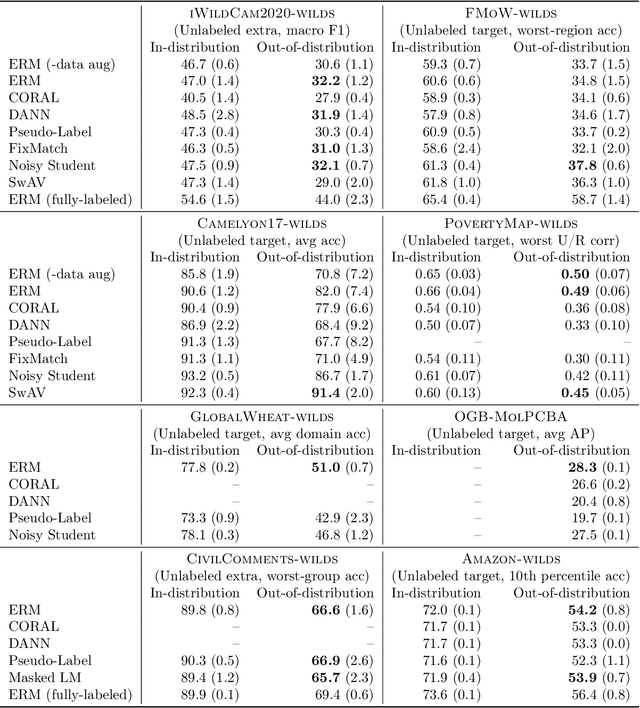
Machine learning systems deployed in the wild are often trained on a source distribution but deployed on a different target distribution. Unlabeled data can be a powerful point of leverage for mitigating these distribution shifts, as it is frequently much more available than labeled data. However, existing distribution shift benchmarks for unlabeled data do not reflect the breadth of scenarios that arise in real-world applications. In this work, we present the WILDS 2.0 update, which extends 8 of the 10 datasets in the WILDS benchmark of distribution shifts to include curated unlabeled data that would be realistically obtainable in deployment. To maintain consistency, the labeled training, validation, and test sets, as well as the evaluation metrics, are exactly the same as in the original WILDS benchmark. These datasets span a wide range of applications (from histology to wildlife conservation), tasks (classification, regression, and detection), and modalities (photos, satellite images, microscope slides, text, molecular graphs). We systematically benchmark state-of-the-art methods that leverage unlabeled data, including domain-invariant, self-training, and self-supervised methods, and show that their success on WILDS 2.0 is limited. To facilitate method development and evaluation, we provide an open-source package that automates data loading and contains all of the model architectures and methods used in this paper. Code and leaderboards are available at https://wilds.stanford.edu.
Global Wheat Head Dataset 2021: more diversity to improve the benchmarking of wheat head localization methods
Jun 03, 2021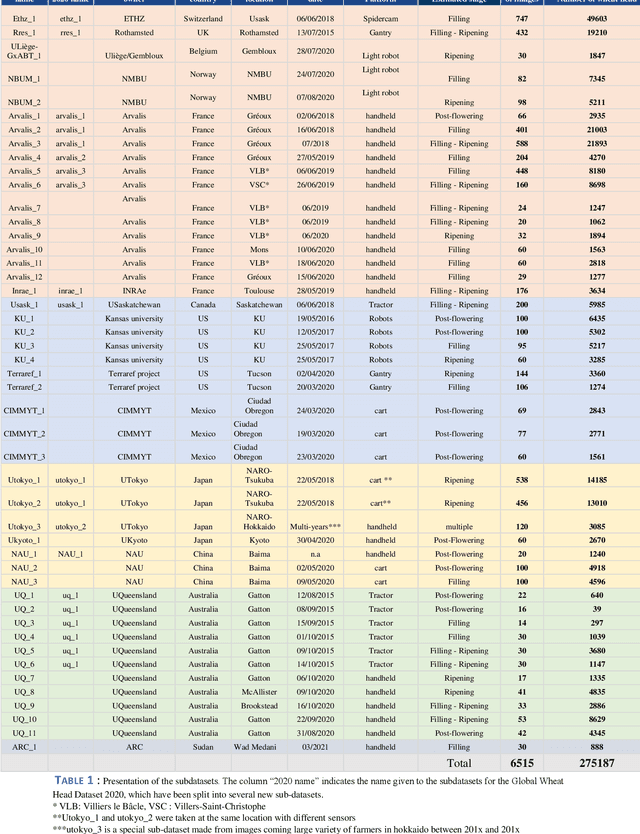
The Global Wheat Head Detection (GWHD) dataset was created in 2020 and has assembled 193,634 labelled wheat heads from 4,700 RGB images acquired from various acquisition platforms and 7 countries/institutions. With an associated competition hosted in Kaggle, GWHD has successfully attracted attention from both the computer vision and agricultural science communities. From this first experience in 2020, a few avenues for improvements have been identified, especially from the perspective of data size, head diversity and label reliability. To address these issues, the 2020 dataset has been reexamined, relabeled, and augmented by adding 1,722 images from 5 additional countries, allowing for 81,553 additional wheat heads to be added. We now release a new version of the Global Wheat Head Detection (GWHD) dataset in 2021, which is bigger, more diverse, and less noisy than the 2020 version. The GWHD 2021 is now publicly available at http://www.global-wheat.com/ and a new data challenge has been organized on AIcrowd to make use of this updated dataset.
Global Wheat Challenge 2020: Analysis of the competition design and winning models
May 13, 2021
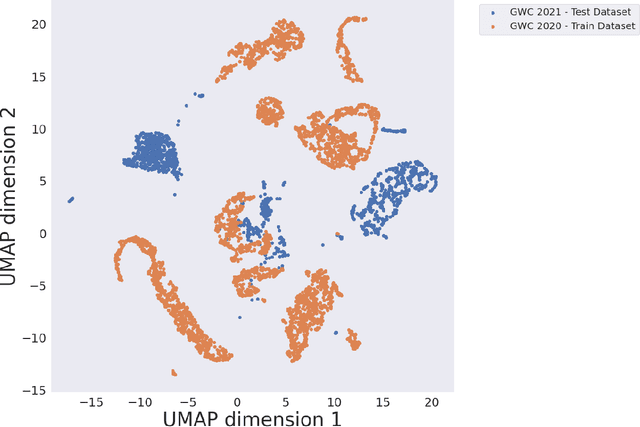

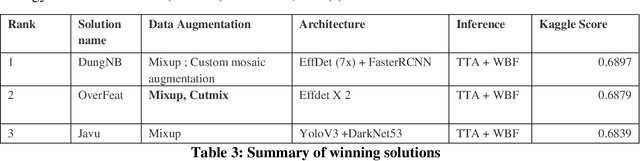
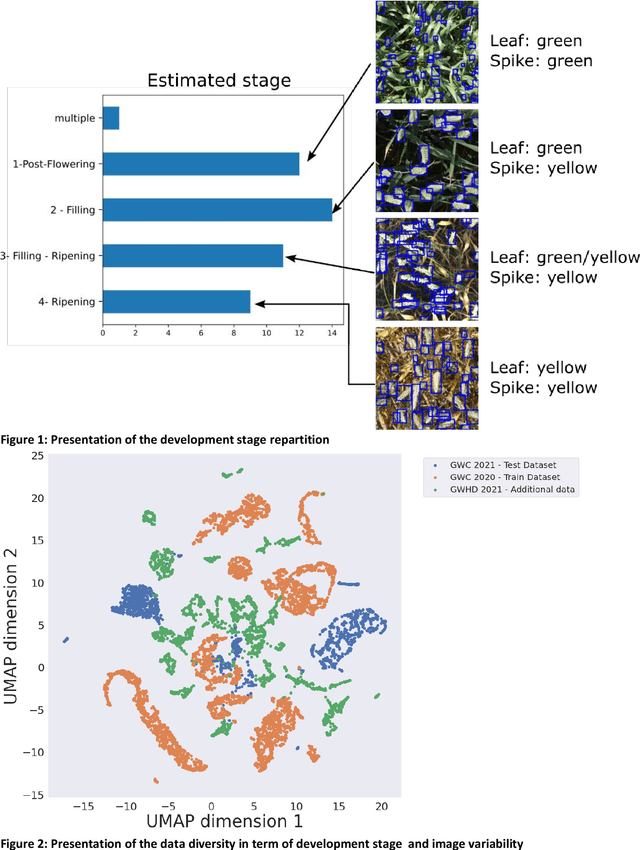
Data competitions have become a popular approach to crowdsource new data analysis methods for general and specialized data science problems. In plant phenotyping, data competitions have a rich history, and new outdoor field datasets have potential for new data competitions. We developed the Global Wheat Challenge as a generalization competition to see if solutions for wheat head detection from field images would work in different regions around the world. In this paper, we analyze the winning challenge solutions in terms of their robustness and the relative importance of model and data augmentation design decisions. We found that the design of the competition influence the selection of winning solutions and provide recommendations for future competitions in an attempt to garner more robust winning solutions.