 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsequentialist Objectives and Catastrophe
Mar 16, 2026Because human preferences are too complex to codify, AIs operate with misspecified objectives. Optimizing such objectives often produces undesirable outcomes; this phenomenon is known as reward hacking. Such outcomes are not necessarily catastrophic. Indeed, most examples of reward hacking in previous literature are benign. And typically, objectives can be modified to resolve the issue. We study the prospect of catastrophic outcomes induced by AIs operating in complex environments. We argue that, when capabilities are sufficiently advanced, pursuing a fixed consequentialist objective tends to result in catastrophic outcomes. We formalize this by establishing conditions that provably lead to such outcomes. Under these conditions, simple or random behavior is safe. Catastrophic risk arises due to extraordinary competence rather than incompetence. With a fixed consequentialist objective, avoiding catastrophe requires constraining AI capabilities. In fact, constraining capabilities the right amount not only averts catastrophe but yields valuable outcomes. Our results apply to any objective produced by modern industrial AI development pipelines.
Granular feedback merits sophisticated aggregation
Jul 16, 2025Human feedback is increasingly used across diverse applications like training AI models, developing recommender systems, and measuring public opinion -- with granular feedback often being preferred over binary feedback for its greater informativeness. While it is easy to accurately estimate a population's distribution of feedback given feedback from a large number of individuals, cost constraints typically necessitate using smaller groups. A simple method to approximate the population distribution is regularized averaging: compute the empirical distribution and regularize it toward a prior. Can we do better? As we will discuss, the answer to this question depends on feedback granularity. Suppose one wants to predict a population's distribution of feedback using feedback from a limited number of individuals. We show that, as feedback granularity increases, one can substantially improve upon predictions of regularized averaging by combining individuals' feedback in ways more sophisticated than regularized averaging. Our empirical analysis using questions on social attitudes confirms this pattern. In particular, with binary feedback, sophistication barely reduces the number of individuals required to attain a fixed level of performance. By contrast, with five-point feedback, sophisticated methods match the performance of regularized averaging with about half as many individuals.
Test-Time Alignment via Hypothesis Reweighting
Dec 11, 2024Large pretrained models often struggle with underspecified tasks -- situations where the training data does not fully define the desired behavior. For example, chatbots must handle diverse and often conflicting user preferences, requiring adaptability to various user needs. We propose a novel framework to address the general challenge of aligning models to test-time user intent, which is rarely fully specified during training. Our approach involves training an efficient ensemble, i.e., a single neural network with multiple prediction heads, each representing a different function consistent with the training data. Our main contribution is HyRe, a simple adaptation technique that dynamically reweights ensemble members at test time using a small set of labeled examples from the target distribution, which can be labeled in advance or actively queried from a larger unlabeled pool. By leveraging recent advances in scalable ensemble training, our method scales to large pretrained models, with computational costs comparable to fine-tuning a single model. We empirically validate HyRe in several underspecified scenarios, including personalization tasks and settings with distribution shifts. Additionally, with just five preference pairs from each target distribution, the same ensemble adapted via HyRe outperforms the prior state-of-the-art 2B-parameter reward model accuracy across 18 evaluation distributions.
Choice between Partial Trajectories
Oct 30, 2024

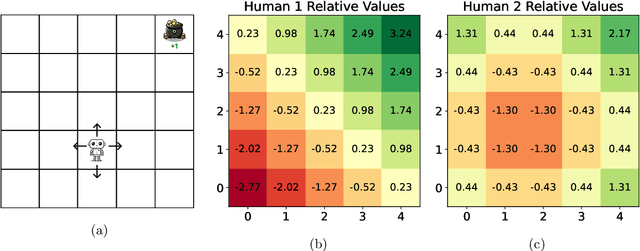

As AI agents generate increasingly sophisticated behaviors, manually encoding human preferences to guide these agents becomes more challenging. To address this, it has been suggested that agents instead learn preferences from human choice data. This approach requires a model of choice behavior that the agent can use to interpret the data. For choices between partial trajectories of states and actions, previous models assume choice probabilities to be determined by the partial return or the cumulative advantage. We consider an alternative model based instead on the bootstrapped return, which adds to the partial return an estimate of the future return. Benefits of the bootstrapped return model stem from its treatment of human beliefs. Unlike partial return, choices based on bootstrapped return reflect human beliefs about the environment. Further, while recovering the reward function from choices based on cumulative advantage requires that those beliefs are correct, doing so from choices based on bootstrapped return does not. To motivate the bootstrapped return model, we formulate axioms and prove an Alignment Theorem. This result formalizes how, for a general class of human preferences, such models are able to disentangle goals from beliefs. This ensures recovery of an aligned reward function when learning from choices based on bootstrapped return. The bootstrapped return model also affords greater robustness to choice behavior. Even when choices are based on partial return, learning via a bootstrapped return model recovers an aligned reward function. The same holds with choices based on the cumulative advantage if the human and the agent both adhere to correct and consistent beliefs about the environment. On the other hand, if choices are based on bootstrapped return, learning via partial return or cumulative advantage models does not generally produce an aligned reward function.
Adaptive Crowdsourcing Via Self-Supervised Learning
Feb 02, 2024Common crowdsourcing systems average estimates of a latent quantity of interest provided by many crowdworkers to produce a group estimate. We develop a new approach -- predict-each-worker -- that leverages self-supervised learning and a novel aggregation scheme. This approach adapts weights assigned to crowdworkers based on estimates they provided for previous quantities. When skills vary across crowdworkers or their estimates correlate, the weighted sum offers a more accurate group estimate than the average. Existing algorithms such as expectation maximization can, at least in principle, produce similarly accurate group estimates. However, their computational requirements become onerous when complex models, such as neural networks, are required to express relationships among crowdworkers. Predict-each-worker accommodates such complexity as well as many other practical challenges. We analyze the efficacy of predict-each-worker through theoretical and computational studies. Among other things, we establish asymptotic optimality as the number of engagements per crowdworker grows.
Maintaining Plasticity via Regenerative Regularization
Aug 23, 2023In continual learning, plasticity refers to the ability of an agent to quickly adapt to new information. Neural networks are known to lose plasticity when processing non-stationary data streams. In this paper, we propose L2 Init, a very simple approach for maintaining plasticity by incorporating in the loss function L2 regularization toward initial parameters. This is very similar to standard L2 regularization (L2), the only difference being that L2 regularizes toward the origin. L2 Init is simple to implement and requires selecting only a single hyper-parameter. The motivation for this method is the same as that of methods that reset neurons or parameter values. Intuitively, when recent losses are insensitive to particular parameters, these parameters drift toward their initial values. This prepares parameters to adapt quickly to new tasks. On simple problems representative of different types of nonstationarity in continual learning, we demonstrate that L2 Init consistently mitigates plasticity loss. We additionally find that our regularization term reduces parameter magnitudes and maintains a high effective feature rank.
Continual Learning as Computationally Constrained Reinforcement Learning
Jul 10, 2023



An agent that efficiently accumulates knowledge to develop increasingly sophisticated skills over a long lifetime could advance the frontier of artificial intelligence capabilities. The design of such agents, which remains a long-standing challenge of artificial intelligence, is addressed by the subject of continual learning. This monograph clarifies and formalizes concepts of continual learning, introducing a framework and set of tools to stimulate further research.
Extending the WILDS Benchmark for Unsupervised Adaptation
Dec 09, 2021

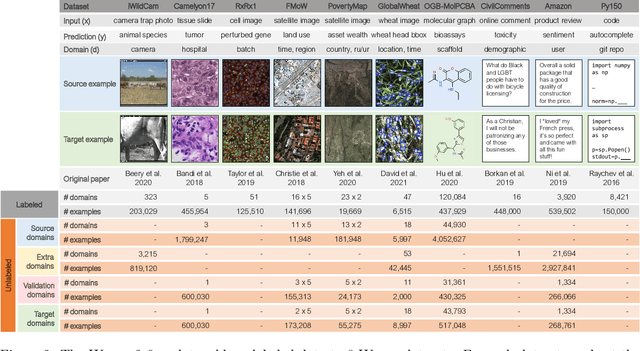
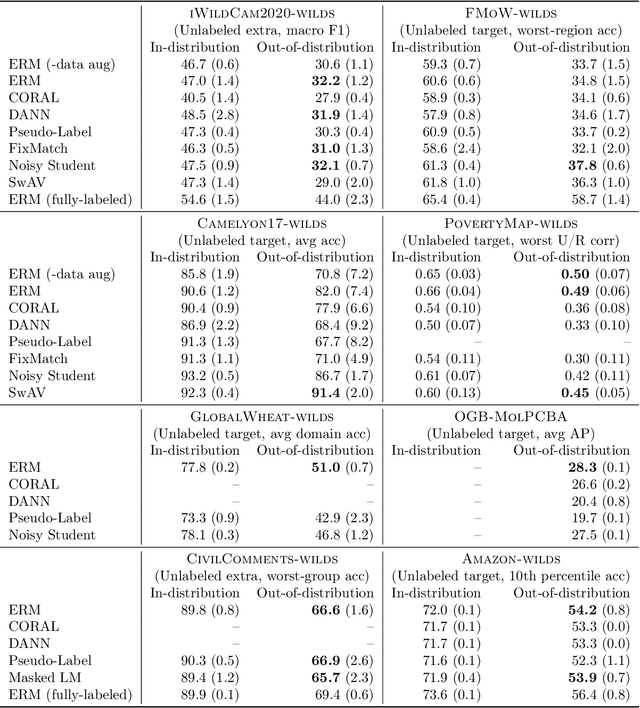
Machine learning systems deployed in the wild are often trained on a source distribution but deployed on a different target distribution. Unlabeled data can be a powerful point of leverage for mitigating these distribution shifts, as it is frequently much more available than labeled data. However, existing distribution shift benchmarks for unlabeled data do not reflect the breadth of scenarios that arise in real-world applications. In this work, we present the WILDS 2.0 update, which extends 8 of the 10 datasets in the WILDS benchmark of distribution shifts to include curated unlabeled data that would be realistically obtainable in deployment. To maintain consistency, the labeled training, validation, and test sets, as well as the evaluation metrics, are exactly the same as in the original WILDS benchmark. These datasets span a wide range of applications (from histology to wildlife conservation), tasks (classification, regression, and detection), and modalities (photos, satellite images, microscope slides, text, molecular graphs). We systematically benchmark state-of-the-art methods that leverage unlabeled data, including domain-invariant, self-training, and self-supervised methods, and show that their success on WILDS 2.0 is limited. To facilitate method development and evaluation, we provide an open-source package that automates data loading and contains all of the model architectures and methods used in this paper. Code and leaderboards are available at https://wilds.stanford.edu.
WILDS: A Benchmark of in-the-Wild Distribution Shifts
Dec 14, 2020
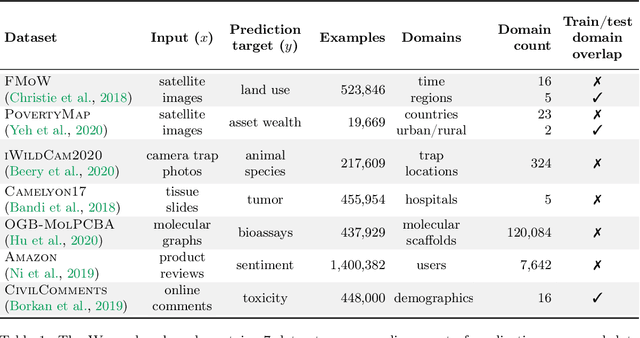

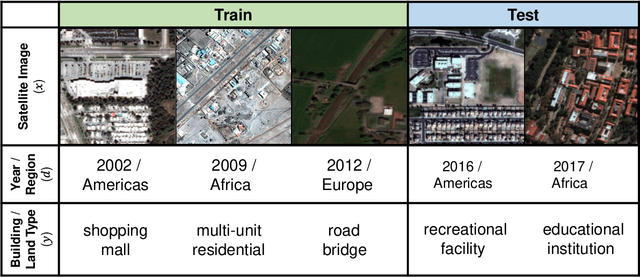
Distribution shifts can cause significant degradation in a broad range of machine learning (ML) systems deployed in the wild. However, many widely-used datasets in the ML community today were not designed for evaluating distribution shifts. These datasets typically have training and test sets drawn from the same distribution, and prior work on retrofitting them with distribution shifts has generally relied on artificial shifts that need not represent the kinds of shifts encountered in the wild. In this paper, we present WILDS, a benchmark of in-the-wild distribution shifts spanning diverse data modalities and applications, from tumor identification to wildlife monitoring to poverty mapping. WILDS builds on top of recent data collection efforts by domain experts in these applications and provides a unified collection of datasets with evaluation metrics and train/test splits that are representative of real-world distribution shifts. These datasets reflect distribution shifts arising from training and testing on different hospitals, cameras, countries, time periods, demographics, molecular scaffolds, etc., all of which cause substantial performance drops in our baseline models. Finally, we survey other applications that would be promising additions to the benchmark but for which we did not manage to find appropriate datasets; we discuss their associated challenges and detail datasets and shifts where we did not see an appreciable performance drop. By unifying datasets from a variety of application areas and making them accessible to the ML community, we hope to encourage the development of general-purpose methods that are anchored to real-world distribution shifts and that work well across different applications and problem settings. Data loaders, default models, and leaderboards are available at https://wilds.stanford.edu.
Adaptive Risk Minimization: A Meta-Learning Approach for Tackling Group Shift
Jul 06, 2020
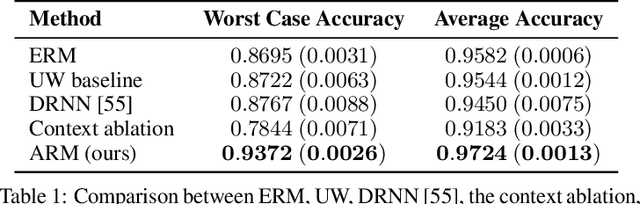
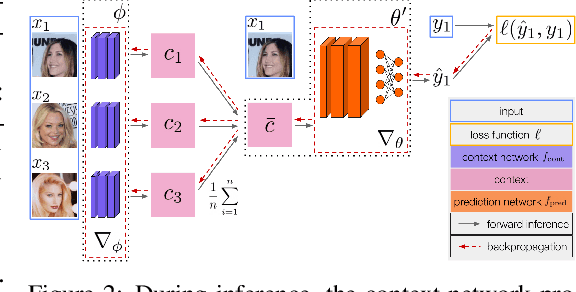
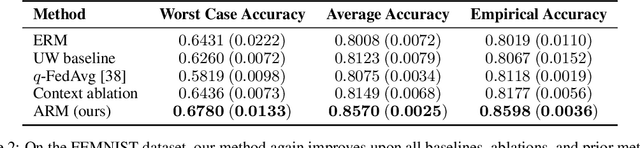
A fundamental assumption of most machine learning algorithms is that the training and test data are drawn from the same underlying distribution. However, this assumption is violated in almost all practical applications: machine learning systems are regularly tested on data that are structurally different from the training set, either due to temporal correlations, particular end users, or other factors. In this work, we consider the setting where test examples are not drawn from the training distribution. Prior work has approached this problem by attempting to be robust to all possible test time distributions, which may degrade average performance, or by "peeking" at the test examples during training, which is not always feasible. In contrast, we propose to learn models that are adaptable, such that they can adapt to distribution shift at test time using a batch of unlabeled test data points. We acquire such models by learning to adapt to training batches sampled according to different sub-distributions, which simulate structural distribution shifts that may occur at test time. We introduce the problem of adaptive risk minimization (ARM), a formalization of this setting that lends itself to meta-learning methods. Compared to a variety of methods under the paradigms of empirical risk minimization and robust optimization, our approach provides substantial empirical gains on image classification problems in the presence of distribution shift.