 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
MEMO: Test Time Robustness via Adaptation and Augmentation
Oct 18, 2021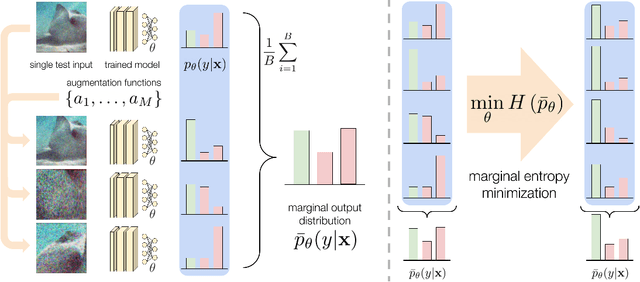



While deep neural networks can attain good accuracy on in-distribution test points, many applications require robustness even in the face of unexpected perturbations in the input, changes in the domain, or other sources of distribution shift. We study the problem of test time robustification, i.e., using the test input to improve model robustness. Recent prior works have proposed methods for test time adaptation, however, they each introduce additional assumptions, such as access to multiple test points, that prevent widespread adoption. In this work, we aim to study and devise methods that make no assumptions about the model training process and are broadly applicable at test time. We propose a simple approach that can be used in any test setting where the model is probabilistic and adaptable: when presented with a test example, perform different data augmentations on the data point, and then adapt (all of) the model parameters by minimizing the entropy of the model's average, or marginal, output distribution across the augmentations. Intuitively, this objective encourages the model to make the same prediction across different augmentations, thus enforcing the invariances encoded in these augmentations, while also maintaining confidence in its predictions. In our experiments, we demonstrate that this approach consistently improves robust ResNet and vision transformer models, achieving accuracy gains of 1-8% over standard model evaluation and also generally outperforming prior augmentation and adaptation strategies. We achieve state-of-the-art results for test shifts caused by image corruptions (ImageNet-C), renditions of common objects (ImageNet-R), and, among ResNet-50 models, adversarially chosen natural examples (ImageNet-A).
WILDS: A Benchmark of in-the-Wild Distribution Shifts
Dec 14, 2020
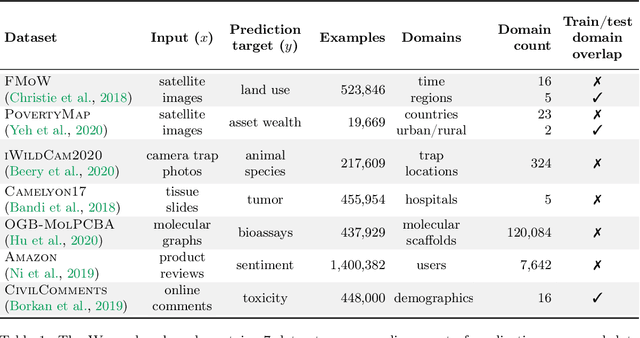

Distribution shifts can cause significant degradation in a broad range of machine learning (ML) systems deployed in the wild. However, many widely-used datasets in the ML community today were not designed for evaluating distribution shifts. These datasets typically have training and test sets drawn from the same distribution, and prior work on retrofitting them with distribution shifts has generally relied on artificial shifts that need not represent the kinds of shifts encountered in the wild. In this paper, we present WILDS, a benchmark of in-the-wild distribution shifts spanning diverse data modalities and applications, from tumor identification to wildlife monitoring to poverty mapping. WILDS builds on top of recent data collection efforts by domain experts in these applications and provides a unified collection of datasets with evaluation metrics and train/test splits that are representative of real-world distribution shifts. These datasets reflect distribution shifts arising from training and testing on different hospitals, cameras, countries, time periods, demographics, molecular scaffolds, etc., all of which cause substantial performance drops in our baseline models. Finally, we survey other applications that would be promising additions to the benchmark but for which we did not manage to find appropriate datasets; we discuss their associated challenges and detail datasets and shifts where we did not see an appreciable performance drop. By unifying datasets from a variety of application areas and making them accessible to the ML community, we hope to encourage the development of general-purpose methods that are anchored to real-world distribution shifts and that work well across different applications and problem settings. Data loaders, default models, and leaderboards are available at https://wilds.stanford.edu.
Adaptive Risk Minimization: A Meta-Learning Approach for Tackling Group Shift
Jul 06, 2020
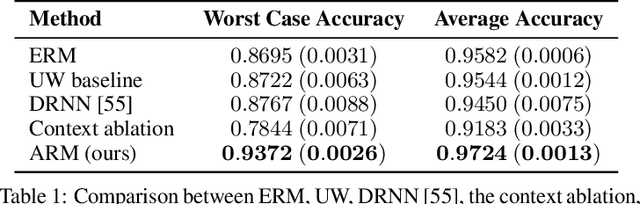
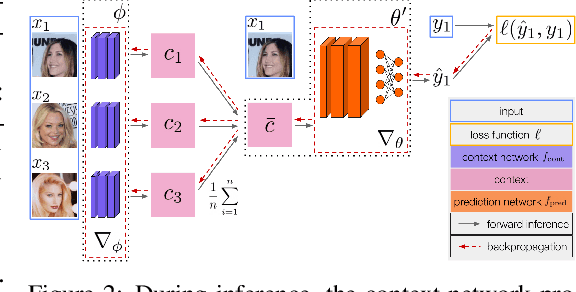
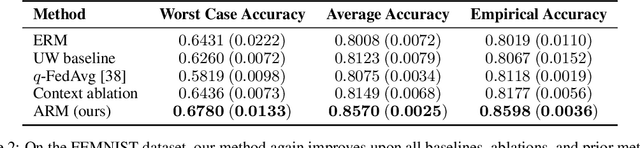
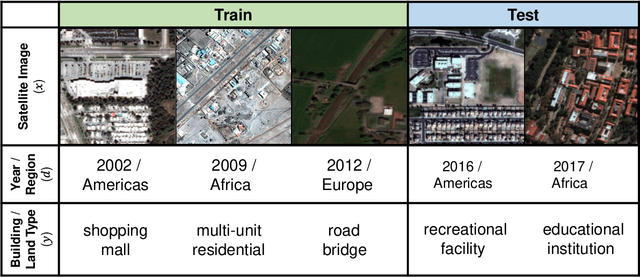
A fundamental assumption of most machine learning algorithms is that the training and test data are drawn from the same underlying distribution. However, this assumption is violated in almost all practical applications: machine learning systems are regularly tested on data that are structurally different from the training set, either due to temporal correlations, particular end users, or other factors. In this work, we consider the setting where test examples are not drawn from the training distribution. Prior work has approached this problem by attempting to be robust to all possible test time distributions, which may degrade average performance, or by "peeking" at the test examples during training, which is not always feasible. In contrast, we propose to learn models that are adaptable, such that they can adapt to distribution shift at test time using a batch of unlabeled test data points. We acquire such models by learning to adapt to training batches sampled according to different sub-distributions, which simulate structural distribution shifts that may occur at test time. We introduce the problem of adaptive risk minimization (ARM), a formalization of this setting that lends itself to meta-learning methods. Compared to a variety of methods under the paradigms of empirical risk minimization and robust optimization, our approach provides substantial empirical gains on image classification problems in the presence of distribution shift.
AVID: Learning Multi-Stage Tasks via Pixel-Level Translation of Human Videos
Dec 10, 2019



Robotic reinforcement learning (RL) holds the promise of enabling robots to learn complex behaviors through experience. However, realizing this promise requires not only effective and scalable RL algorithms, but also mechanisms to reduce human burden in terms of defining the task and resetting the environment. In this paper, we study how these challenges can be alleviated with an automated robotic learning framework, in which multi-stage tasks are defined simply by providing videos of a human demonstrator and then learned autonomously by the robot from raw image observations. A central challenge in imitating human videos is the difference in morphology between the human and robot, which typically requires manual correspondence. We instead take an automated approach and perform pixel-level image translation via CycleGAN to convert the human demonstration into a video of a robot, which can then be used to construct a reward function for a model-based RL algorithm. The robot then learns the task one stage at a time, automatically learning how to reset each stage to retry it multiple times without human-provided resets. This makes the learning process largely automatic, from intuitive task specification via a video to automated training with minimal human intervention. We demonstrate that our approach is capable of learning complex tasks, such as operating a coffee machine, directly from raw image observations, requiring only 20 minutes to provide human demonstrations and about 180 minutes of robot interaction with the environment. A supplementary video depicting the experimental setup, learning process, and our method's final performance is available from https://sites.google.com/view/icra20avid
When to Trust Your Model: Model-Based Policy Optimization
Jun 19, 2019

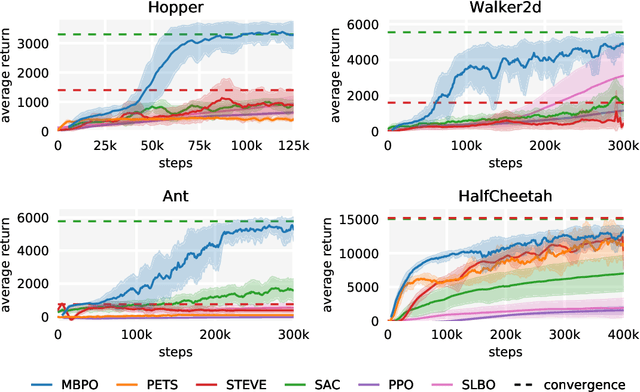

Designing effective model-based reinforcement learning algorithms is difficult because the ease of data generation must be weighed against the bias of model-generated data. In this paper, we study the role of model usage in policy optimization both theoretically and empirically. We first formulate and analyze a model-based reinforcement learning algorithm with a guarantee of monotonic improvement at each step. In practice, this analysis is overly pessimistic and suggests that real off-policy data is always preferable to model-generated on-policy data, but we show that an empirical estimate of model generalization can be incorporated into such analysis to justify model usage. Motivated by this analysis, we then demonstrate that a simple procedure of using short model-generated rollouts branched from real data has the benefits of more complicated model-based algorithms without the usual pitfalls. In particular, this approach surpasses the sample efficiency of prior model-based methods, matches the asymptotic performance of the best model-free algorithms, and scales to horizons that cause other model-based methods to fail entirely.
SOLAR: Deep Structured Representations for Model-Based Reinforcement Learning
Feb 20, 2019
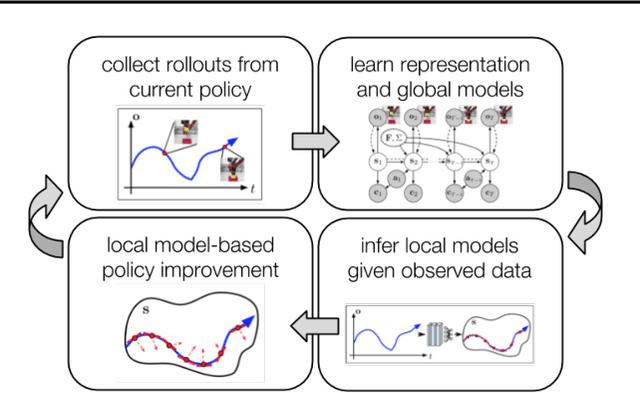
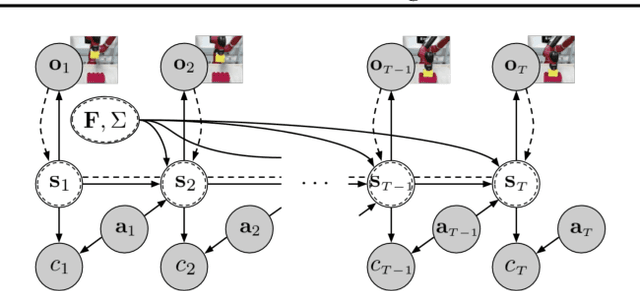

Model-based reinforcement learning (RL) has proven to be a data efficient approach for learning control tasks but is difficult to utilize in domains with complex observations such as images. In this paper, we present a method for learning representations that are suitable for iterative model-based policy improvement, in that these representations are optimized for inferring simple dynamics and cost models given data from the current policy. This enables a model-based RL method based on the linear-quadratic regulator (LQR) to be used for systems with image observations. We evaluate our approach on a suite of robotics tasks, including manipulation tasks on a real Sawyer robot arm directly from images, and we find that our method results in better final performance than other model-based RL methods while being significantly more efficient than model-free RL. Videos of our results are available at https://sites.google.com/view/icml19solar
Combining Model-Based and Model-Free Updates for Trajectory-Centric Reinforcement Learning
Jun 18, 2017
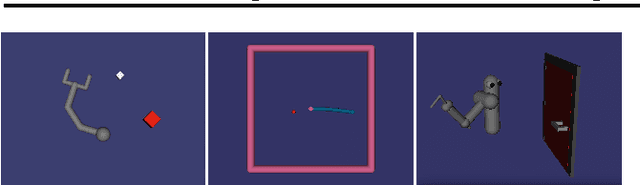
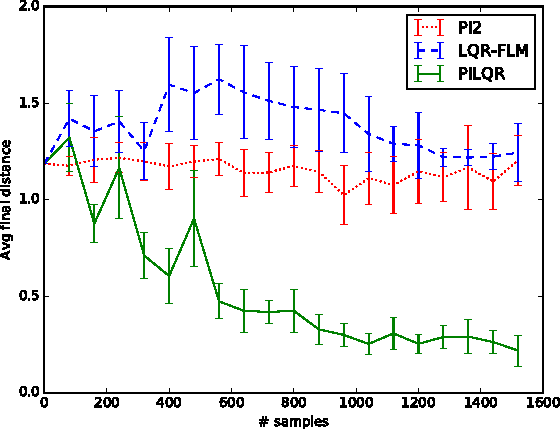
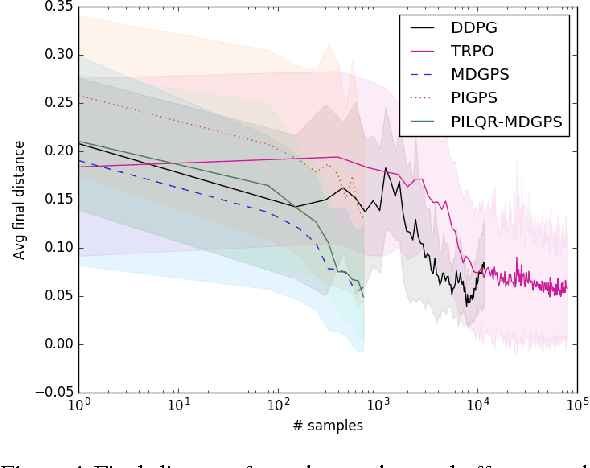
Reinforcement learning (RL) algorithms for real-world robotic applications need a data-efficient learning process and the ability to handle complex, unknown dynamical systems. These requirements are handled well by model-based and model-free RL approaches, respectively. In this work, we aim to combine the advantages of these two types of methods in a principled manner. By focusing on time-varying linear-Gaussian policies, we enable a model-based algorithm based on the linear quadratic regulator (LQR) that can be integrated into the model-free framework of path integral policy improvement (PI2). We can further combine our method with guided policy search (GPS) to train arbitrary parameterized policies such as deep neural networks. Our simulation and real-world experiments demonstrate that this method can solve challenging manipulation tasks with comparable or better performance than model-free methods while maintaining the sample efficiency of model-based methods. A video presenting our results is available at https://sites.google.com/site/icml17pilqr
Deep Reinforcement Learning for Tensegrity Robot Locomotion
Mar 08, 2017

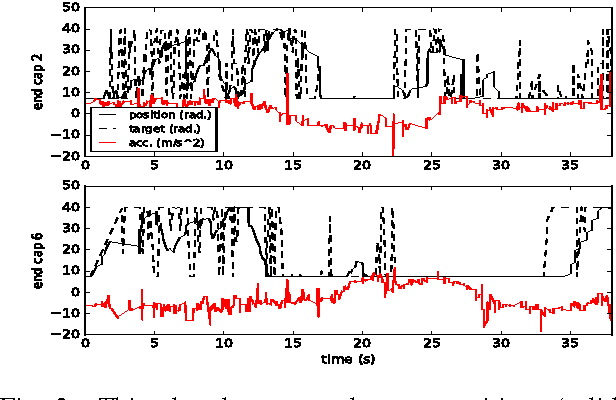
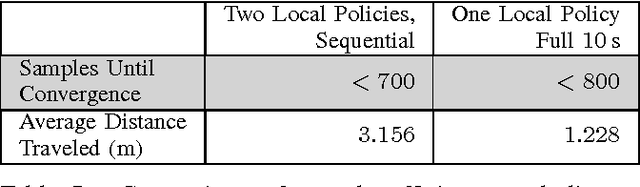
Tensegrity robots, composed of rigid rods connected by elastic cables, have a number of unique properties that make them appealing for use as planetary exploration rovers. However, control of tensegrity robots remains a difficult problem due to their unusual structures and complex dynamics. In this work, we show how locomotion gaits can be learned automatically using a novel extension of mirror descent guided policy search (MDGPS) applied to periodic locomotion movements, and we demonstrate the effectiveness of our approach on tensegrity robot locomotion. We evaluate our method with real-world and simulated experiments on the SUPERball tensegrity robot, showing that the learned policies generalize to changes in system parameters, unreliable sensor measurements, and variation in environmental conditions, including varied terrains and a range of different gravities. Our experiments demonstrate that our method not only learns fast, power-efficient feedback policies for rolling gaits, but that these policies can succeed with only the limited onboard sensing provided by SUPERball's accelerometers. We compare the learned feedback policies to learned open-loop policies and hand-engineered controllers, and demonstrate that the learned policy enables the first continuous, reliable locomotion gait for the real SUPERball robot. Our code and other supplementary materials are available from http://rll.berkeley.edu/drl_tensegrity