 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuasi-Direct Drive for Low-Cost Compliant Robotic Manipulation
Apr 11, 2019
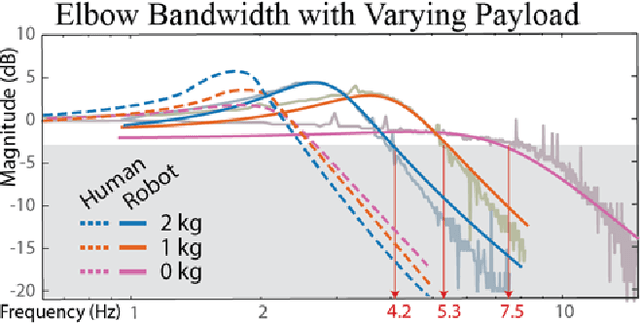


Robots must cost less and be force-controlled to enable widespread, safe deployment in unconstrained human environments. We propose Quasi-Direct Drive actuation as a capable paradigm for robotic force-controlled manipulation in human environments at low-cost. Our prototype - Blue - is a human scale 7 Degree of Freedom arm with 2kg payload. Blue can cost less than $5000. We show that Blue has dynamic properties that meet or exceed the needs of human operators: the robot has a nominal position-control bandwidth of 7.5Hz and repeatability within 4mm. We demonstrate a Virtual Reality based interface that can be used as a method for telepresence and collecting robot training demonstrations. Manufacturability, scaling, and potential use-cases for the Blue system are also addressed. Videos and additional information can be found online at berkeleyopenarms.github.io
Deep Imitation Learning for Complex Manipulation Tasks from Virtual Reality Teleoperation
Mar 06, 2018



Imitation learning is a powerful paradigm for robot skill acquisition. However, obtaining demonstrations suitable for learning a policy that maps from raw pixels to actions can be challenging. In this paper we describe how consumer-grade Virtual Reality headsets and hand tracking hardware can be used to naturally teleoperate robots to perform complex tasks. We also describe how imitation learning can learn deep neural network policies (mapping from pixels to actions) that can acquire the demonstrated skills. Our experiments showcase the effectiveness of our approach for learning visuomotor skills.
Probabilistically Safe Policy Transfer
May 15, 2017
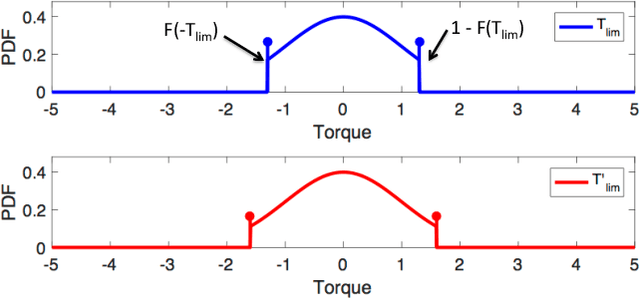
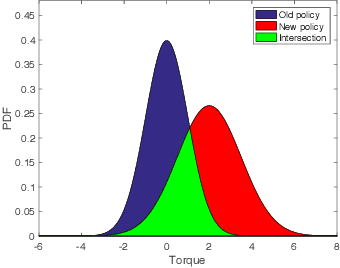
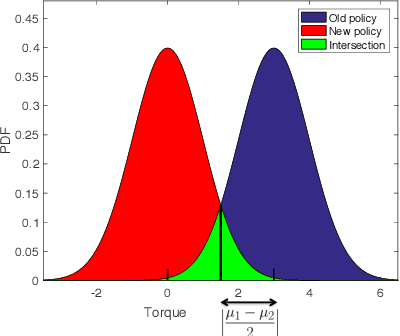
Although learning-based methods have great potential for robotics, one concern is that a robot that updates its parameters might cause large amounts of damage before it learns the optimal policy. We formalize the idea of safe learning in a probabilistic sense by defining an optimization problem: we desire to maximize the expected return while keeping the expected damage below a given safety limit. We study this optimization for the case of a robot manipulator with safety-based torque limits. We would like to ensure that the damage constraint is maintained at every step of the optimization and not just at convergence. To achieve this aim, we introduce a novel method which predicts how modifying the torque limit, as well as how updating the policy parameters, might affect the robot's safety. We show through a number of experiments that our approach allows the robot to improve its performance while ensuring that the expected damage constraint is not violated during the learning process.
Learning Deep Neural Network Policies with Continuous Memory States
Sep 23, 2015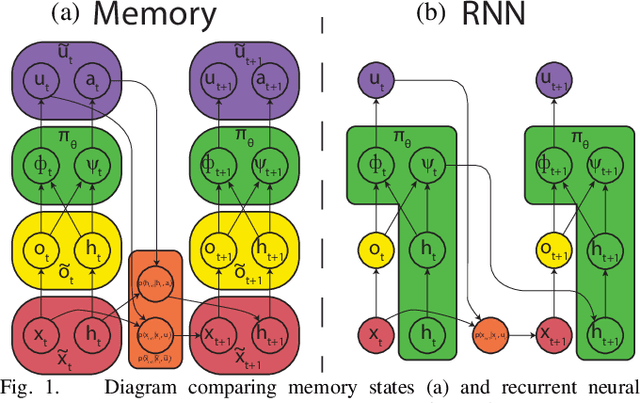
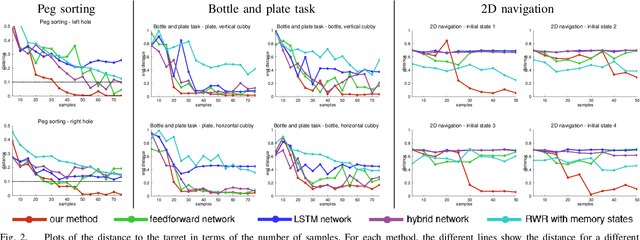

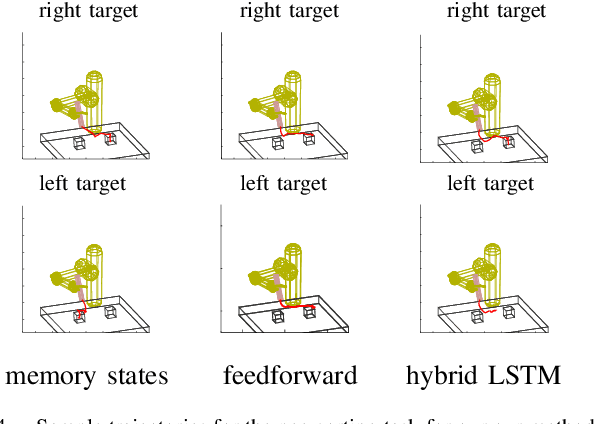
Policy learning for partially observed control tasks requires policies that can remember salient information from past observations. In this paper, we present a method for learning policies with internal memory for high-dimensional, continuous systems, such as robotic manipulators. Our approach consists of augmenting the state and action space of the system with continuous-valued memory states that the policy can read from and write to. Learning general-purpose policies with this type of memory representation directly is difficult, because the policy must automatically figure out the most salient information to memorize at each time step. We show that, by decomposing this policy search problem into a trajectory optimization phase and a supervised learning phase through a method called guided policy search, we can acquire policies with effective memorization and recall strategies. Intuitively, the trajectory optimization phase chooses the values of the memory states that will make it easier for the policy to produce the right action in future states, while the supervised learning phase encourages the policy to use memorization actions to produce those memory states. We evaluate our method on tasks involving continuous control in manipulation and navigation settings, and show that our method can learn complex policies that successfully complete a range of tasks that require memory.