 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeSeek: Temporal Reliability of Agentic Forecasters
Apr 05, 2026We introduce TimeSeek, a benchmark for studying how the reliability of agentic LLM forecasters changes over a prediction market's lifecycle. We evaluate 10 frontier models on 150 CFTC-regulated Kalshi binary markets at five temporal checkpoints, with and without web search, for 15,000 forecasts total. Models are most competitive early in a market's life and on high-uncertainty markets, but much less competitive near resolution and on strong-consensus markets. Web search improves pooled Brier Skill Score (BSS) for every model overall, yet hurts in 12% of model-checkpoint pairs, indicating that retrieval is helpful on average but not uniformly so. Simple two-model ensembles reduce error without surpassing the market overall. These descriptive results motivate time-aware evaluation and selective-deference policies rather than a single market snapshot or a uniform tool-use setting.
Joint Attention for Multi-Agent Coordination and Social Learning
Apr 15, 2021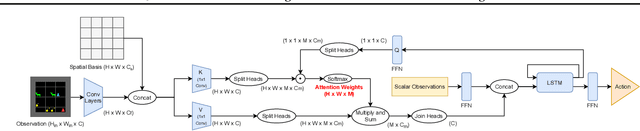
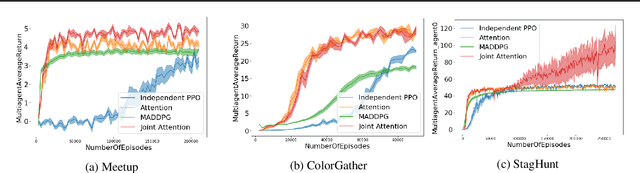
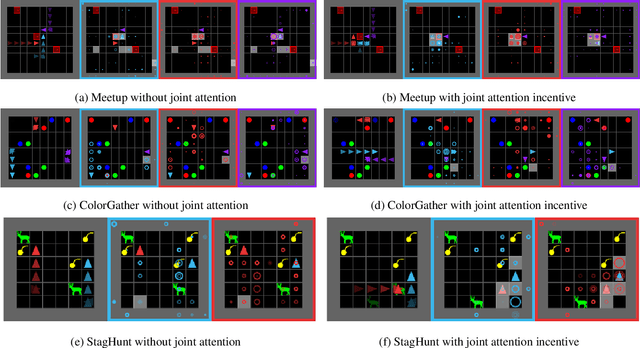
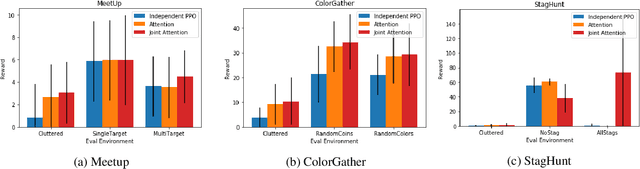
Joint attention - the ability to purposefully coordinate attention with another agent, and mutually attend to the same thing -- is a critical component of human social cognition. In this paper, we ask whether joint attention can be useful as a mechanism for improving multi-agent coordination and social learning. We first develop deep reinforcement learning (RL) agents with a recurrent visual attention architecture. We then train agents to minimize the difference between the attention weights that they apply to the environment at each timestep, and the attention of other agents. Our results show that this joint attention incentive improves agents' ability to solve difficult coordination tasks, by reducing the exponential cost of exploring the joint multi-agent action space. Joint attention leads to higher performance than a competitive centralized critic baseline across multiple environments. Further, we show that joint attention enhances agents' ability to learn from experts present in their environment, even when completing hard exploration tasks that do not require coordination. Taken together, these findings suggest that joint attention may be a useful inductive bias for multi-agent learning.
Language Modeling for Formal Mathematics
Jun 10, 2020
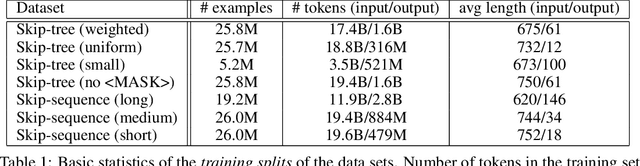
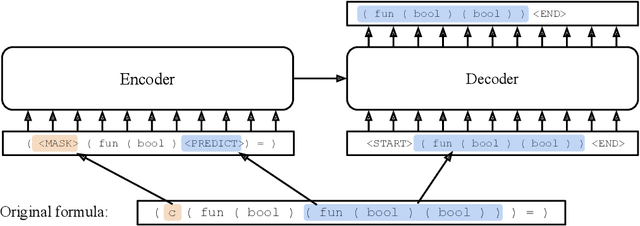
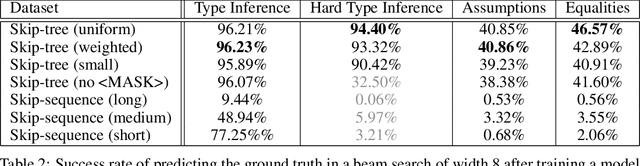
We examine whether language modeling applied to mathematical formulas enables logical reasoning. We suggest several logical reasoning tasks that can be used to evaluate language models trained on formal mathematical statements, such as type inference, suggesting missing assumptions and completing equalities. To train language models for formal mathematics, we propose a novel skip-tree task, which outperforms standard language modeling tasks on our reasoning benchmarks. We also analyze the models' ability to formulate new conjectures by measuring how often the predictions that do not fit the ground truth or any training data turn out to be true and useful statements.
Cooperation without Coordination: Hierarchical Predictive Planning for Decentralized Multiagent Navigation
Mar 15, 2020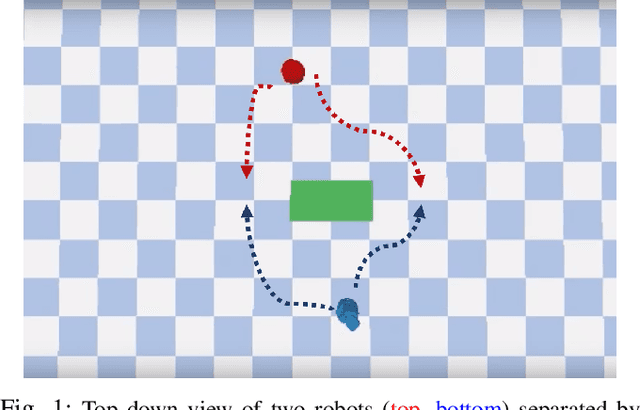
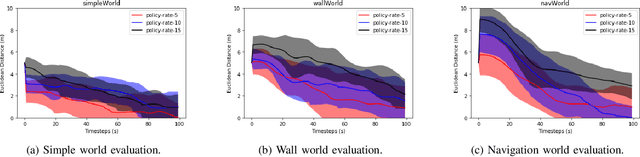
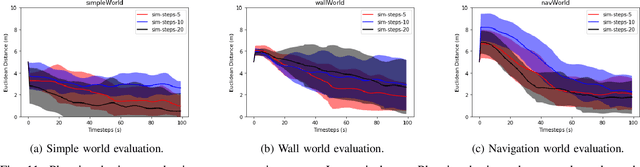
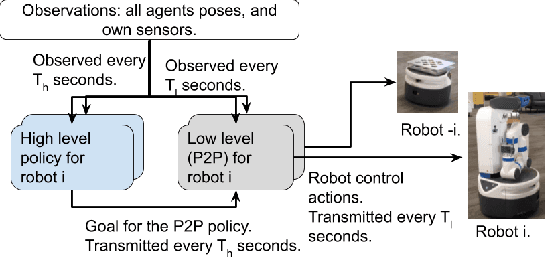
Decentralized multiagent planning raises many challenges, such as adaption to changing environments inexplicable by the agent's own behavior, coordination from noisy sensor inputs like lidar, cooperation without knowing other agents' intents. To address these challenges, we present hierarchical predictive planning (HPP) for decentralized multiagent navigation tasks. HPP learns prediction models for itself and other teammates, and uses the prediction models to propose and evaluate navigation goals that complete the cooperative task without explicit coordination. To learn the prediction models, HPP observes other agents' behavior and learns to maps own sensors to predicted locations of other agents. HPP then uses the cross-entropy method to iteratively propose, evaluate, and improve navigation goals, under assumption that all agents in the team share a common objective. HPP removes the need for a centralized operator (i.e. robots determine their own actions without coordinating their beliefs or plans) and can be trained and easily transferred to real world environments. The results show that HPP generalizes to new environments including real-world robot team. It is also 33x more sample efficient and performs better in complex environments compared to a baseline. The video and website for this paper can be found at https://youtu.be/-LqgfksqNH8 and https://sites.google.com/view/multiagent-hpp.
Mathematical Reasoning in Latent Space
Sep 26, 2019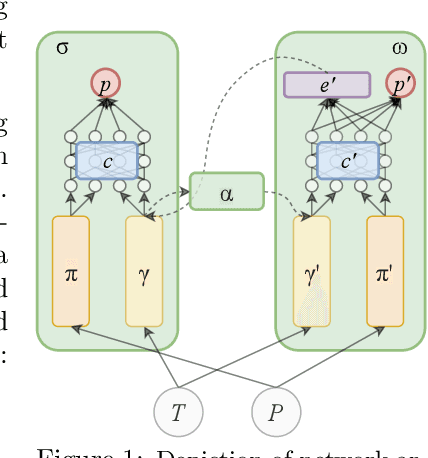
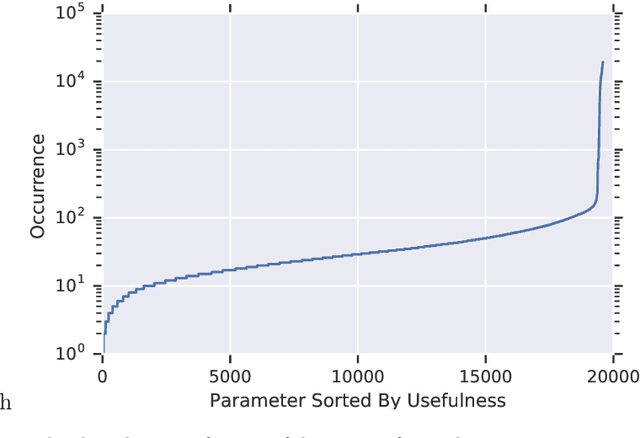
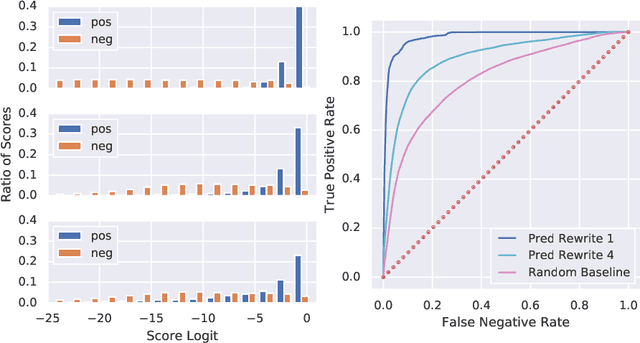
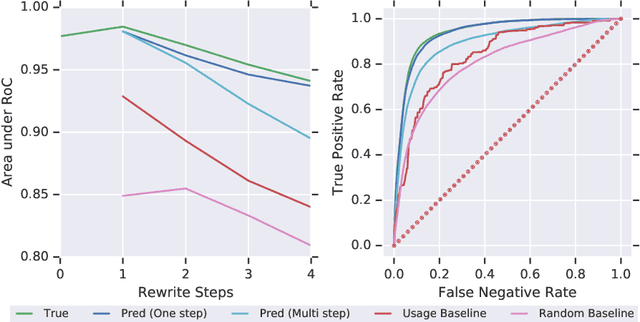
We design and conduct a simple experiment to study whether neural networks can perform several steps of approximate reasoning in a fixed dimensional latent space. The set of rewrites (i.e. transformations) that can be successfully performed on a statement represents essential semantic features of the statement. We can compress this information by embedding the formula in a vector space, such that the vector associated with a statement can be used to predict whether a statement can be rewritten by other theorems. Predicting the embedding of a formula generated by some rewrite rule is naturally viewed as approximate reasoning in the latent space. In order to measure the effectiveness of this reasoning, we perform approximate deduction sequences in the latent space and use the resulting embedding to inform the semantic features of the corresponding formal statement (which is obtained by performing the corresponding rewrite sequence using real formulas). Our experiments show that graph neural networks can make non-trivial predictions about the rewrite-success of statements, even when they propagate predicted latent representations for several steps. Since our corpus of mathematical formulas includes a wide variety of mathematical disciplines, this experiment is a strong indicator for the feasibility of deduction in latent space in general.
Modular Architecture for StarCraft II with Deep Reinforcement Learning
Nov 08, 2018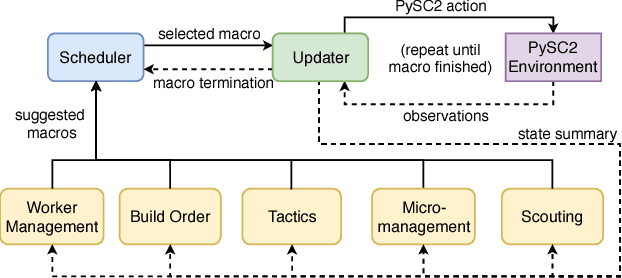

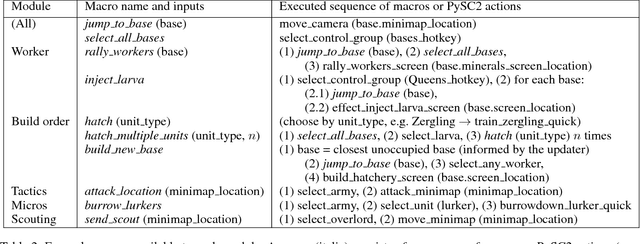
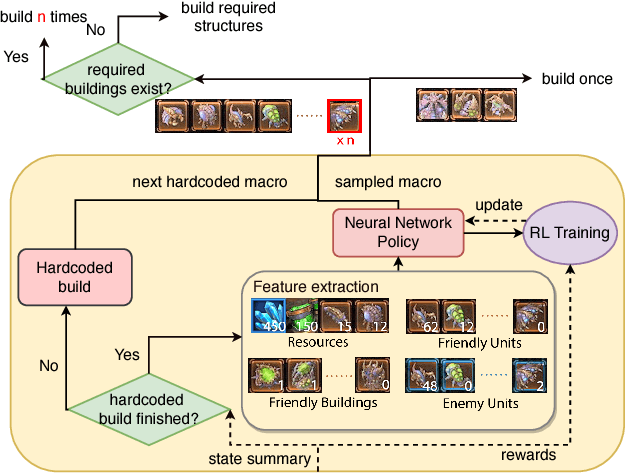
We present a novel modular architecture for StarCraft II AI. The architecture splits responsibilities between multiple modules that each control one aspect of the game, such as build-order selection or tactics. A centralized scheduler reviews macros suggested by all modules and decides their order of execution. An updater keeps track of environment changes and instantiates macros into series of executable actions. Modules in this framework can be optimized independently or jointly via human design, planning, or reinforcement learning. We apply deep reinforcement learning techniques to training two out of six modules of a modular agent with self-play, achieving 94% or 87% win rates against the "Harder" (level 5) built-in Blizzard bot in Zerg vs. Zerg matches, with or without fog-of-war.
ProMP: Proximal Meta-Policy Search
Oct 17, 2018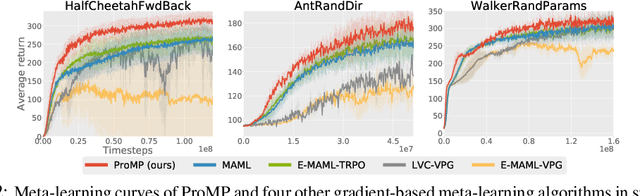
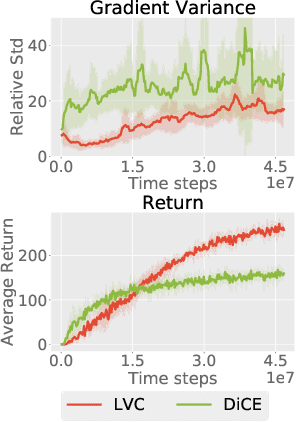
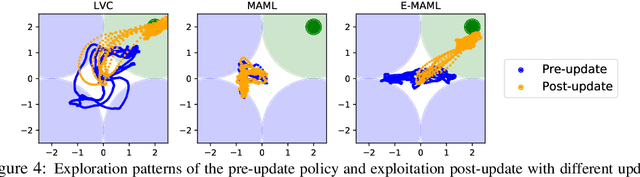
Credit assignment in Meta-reinforcement learning (Meta-RL) is still poorly understood. Existing methods either neglect credit assignment to pre-adaptation behavior or implement it naively. This leads to poor sample-efficiency during meta-training as well as ineffective task identification strategies. This paper provides a theoretical analysis of credit assignment in gradient-based Meta-RL. Building on the gained insights we develop a novel meta-learning algorithm that overcomes both the issue of poor credit assignment and previous difficulties in estimating meta-policy gradients. By controlling the statistical distance of both pre-adaptation and adapted policies during meta-policy search, the proposed algorithm endows efficient and stable meta-learning. Our approach leads to superior pre-adaptation policy behavior and consistently outperforms previous Meta-RL algorithms in sample-efficiency, wall-clock time, and asymptotic performance.
Deep Imitation Learning for Complex Manipulation Tasks from Virtual Reality Teleoperation
Mar 06, 2018



Imitation learning is a powerful paradigm for robot skill acquisition. However, obtaining demonstrations suitable for learning a policy that maps from raw pixels to actions can be challenging. In this paper we describe how consumer-grade Virtual Reality headsets and hand tracking hardware can be used to naturally teleoperate robots to perform complex tasks. We also describe how imitation learning can learn deep neural network policies (mapping from pixels to actions) that can acquire the demonstrated skills. Our experiments showcase the effectiveness of our approach for learning visuomotor skills.