 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSide-Tuning: Network Adaptation via Additive Side Networks
Dec 31, 2019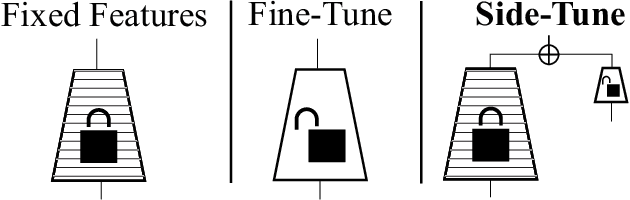

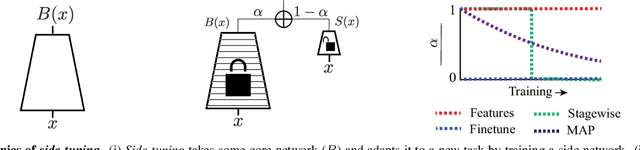
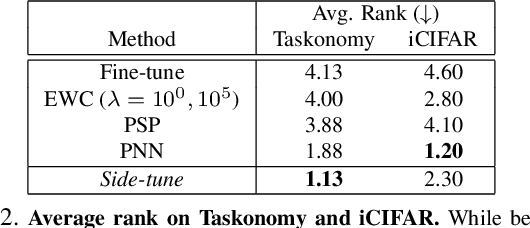
When training a neural network for a desired task, one may prefer to adapt a pre-trained network rather than start with a randomly initialized one -- due to lacking enough training data, performing lifelong learning where the system has to learn a new task while being previously trained for other tasks, or wishing to encode priors in the network via preset weights. The most commonly employed approaches for network adaptation are fine-tuning and using the pre-trained network as a fixed feature extractor, among others. In this paper, we propose a straightforward alternative: Side-Tuning. Side-tuning adapts a pre-trained network by training a lightweight "side" network that is fused with the (unchanged) pre-trained network using summation. This simple method works as well as or better than existing solutions while it resolves some of the basic issues with fine-tuning, fixed features, and several other common baselines. In particular, side-tuning is less prone to overfitting when little training data is available, yields better results than using a fixed feature extractor, and does not suffer from catastrophic forgetting in lifelong learning. We demonstrate the performance of side-tuning under a diverse set of scenarios, including lifelong learning (iCIFAR, Taskonomy), reinforcement learning, imitation learning (visual navigation in Habitat), NLP question-answering (SQuAD v2), and single-task transfer learning (Taskonomy), with consistently promising results.
Modular Architecture for StarCraft II with Deep Reinforcement Learning
Nov 08, 2018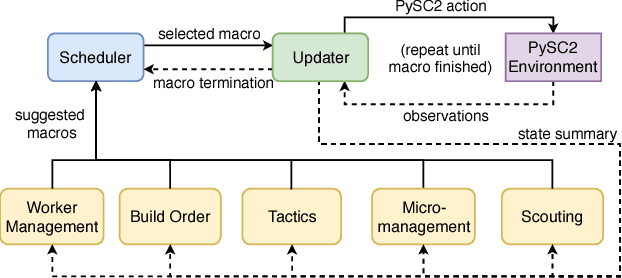

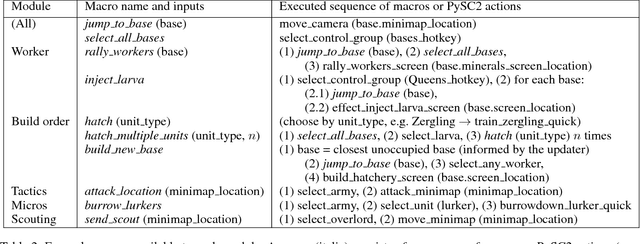
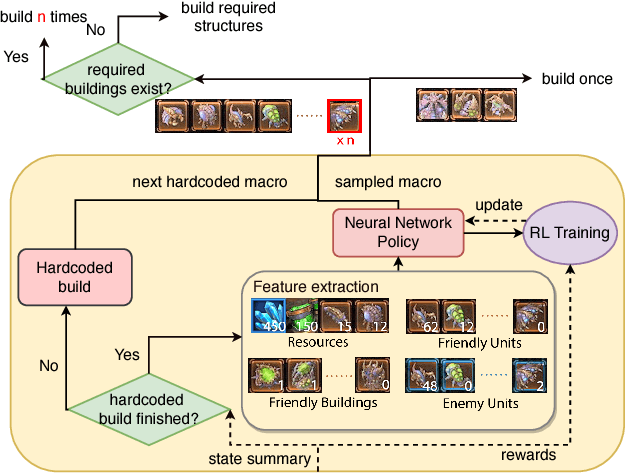
We present a novel modular architecture for StarCraft II AI. The architecture splits responsibilities between multiple modules that each control one aspect of the game, such as build-order selection or tactics. A centralized scheduler reviews macros suggested by all modules and decides their order of execution. An updater keeps track of environment changes and instantiates macros into series of executable actions. Modules in this framework can be optimized independently or jointly via human design, planning, or reinforcement learning. We apply deep reinforcement learning techniques to training two out of six modules of a modular agent with self-play, achieving 94% or 87% win rates against the "Harder" (level 5) built-in Blizzard bot in Zerg vs. Zerg matches, with or without fog-of-war.