 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSide-Tuning: Network Adaptation via Additive Side Networks
Paper and Code
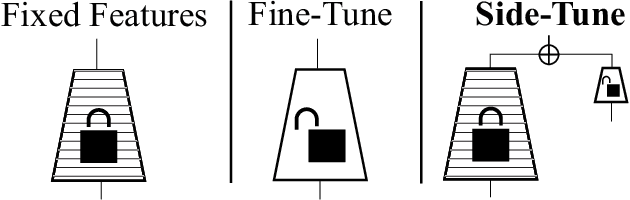

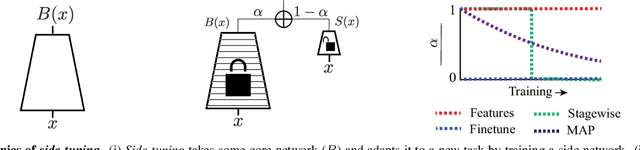
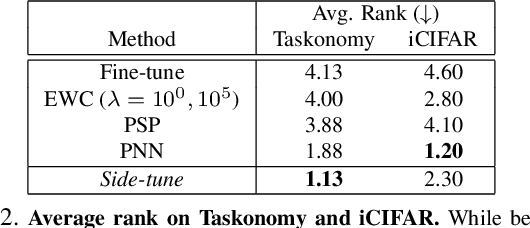
When training a neural network for a desired task, one may prefer to adapt a pre-trained network rather than start with a randomly initialized one -- due to lacking enough training data, performing lifelong learning where the system has to learn a new task while being previously trained for other tasks, or wishing to encode priors in the network via preset weights. The most commonly employed approaches for network adaptation are fine-tuning and using the pre-trained network as a fixed feature extractor, among others. In this paper, we propose a straightforward alternative: Side-Tuning. Side-tuning adapts a pre-trained network by training a lightweight "side" network that is fused with the (unchanged) pre-trained network using summation. This simple method works as well as or better than existing solutions while it resolves some of the basic issues with fine-tuning, fixed features, and several other common baselines. In particular, side-tuning is less prone to overfitting when little training data is available, yields better results than using a fixed feature extractor, and does not suffer from catastrophic forgetting in lifelong learning. We demonstrate the performance of side-tuning under a diverse set of scenarios, including lifelong learning (iCIFAR, Taskonomy), reinforcement learning, imitation learning (visual navigation in Habitat), NLP question-answering (SQuAD v2), and single-task transfer learning (Taskonomy), with consistently promising results.