 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocate 3D: Real-World Object Localization via Self-Supervised Learning in 3D
Apr 19, 2025We present LOCATE 3D, a model for localizing objects in 3D scenes from referring expressions like "the small coffee table between the sofa and the lamp." LOCATE 3D sets a new state-of-the-art on standard referential grounding benchmarks and showcases robust generalization capabilities. Notably, LOCATE 3D operates directly on sensor observation streams (posed RGB-D frames), enabling real-world deployment on robots and AR devices. Key to our approach is 3D-JEPA, a novel self-supervised learning (SSL) algorithm applicable to sensor point clouds. It takes as input a 3D pointcloud featurized using 2D foundation models (CLIP, DINO). Subsequently, masked prediction in latent space is employed as a pretext task to aid the self-supervised learning of contextualized pointcloud features. Once trained, the 3D-JEPA encoder is finetuned alongside a language-conditioned decoder to jointly predict 3D masks and bounding boxes. Additionally, we introduce LOCATE 3D DATASET, a new dataset for 3D referential grounding, spanning multiple capture setups with over 130K annotations. This enables a systematic study of generalization capabilities as well as a stronger model.
Unifying 2D and 3D Vision-Language Understanding
Mar 13, 2025Progress in 3D vision-language learning has been hindered by the scarcity of large-scale 3D datasets. We introduce UniVLG, a unified architecture for 2D and 3D vision-language understanding that bridges the gap between existing 2D-centric models and the rich 3D sensory data available in embodied systems. Our approach initializes most model weights from pre-trained 2D models and trains on both 2D and 3D vision-language data. We propose a novel language-conditioned mask decoder shared across 2D and 3D modalities to ground objects effectively in both RGB and RGB-D images, outperforming box-based approaches. To further reduce the domain gap between 2D and 3D, we incorporate 2D-to-3D lifting strategies, enabling UniVLG to utilize 2D data to enhance 3D performance. With these innovations, our model achieves state-of-the-art performance across multiple 3D vision-language grounding tasks, demonstrating the potential of transferring advances from 2D vision-language learning to the data-constrained 3D domain. Furthermore, co-training on both 2D and 3D data enhances performance across modalities without sacrificing 2D capabilities. By removing the reliance on 3D mesh reconstruction and ground-truth object proposals, UniVLG sets a new standard for realistic, embodied-aligned evaluation. Code and additional visualizations are available at $\href{https://univlg.github.io}{univlg.github.io}$.
LIFT-GS: Cross-Scene Render-Supervised Distillation for 3D Language Grounding
Feb 27, 2025Our approach to training 3D vision-language understanding models is to train a feedforward model that makes predictions in 3D, but never requires 3D labels and is supervised only in 2D, using 2D losses and differentiable rendering. The approach is new for vision-language understanding. By treating the reconstruction as a ``latent variable'', we can render the outputs without placing unnecessary constraints on the network architecture (e.g. can be used with decoder-only models). For training, only need images and camera pose, and 2D labels. We show that we can even remove the need for 2D labels by using pseudo-labels from pretrained 2D models. We demonstrate this to pretrain a network, and we finetune it for 3D vision-language understanding tasks. We show this approach outperforms baselines/sota for 3D vision-language grounding, and also outperforms other 3D pretraining techniques. Project page: https://liftgs.github.io.
Fast3R: Towards 3D Reconstruction of 1000+ Images in One Forward Pass
Jan 23, 2025Multi-view 3D reconstruction remains a core challenge in computer vision, particularly in applications requiring accurate and scalable representations across diverse perspectives. Current leading methods such as DUSt3R employ a fundamentally pairwise approach, processing images in pairs and necessitating costly global alignment procedures to reconstruct from multiple views. In this work, we propose Fast 3D Reconstruction (Fast3R), a novel multi-view generalization to DUSt3R that achieves efficient and scalable 3D reconstruction by processing many views in parallel. Fast3R's Transformer-based architecture forwards N images in a single forward pass, bypassing the need for iterative alignment. Through extensive experiments on camera pose estimation and 3D reconstruction, Fast3R demonstrates state-of-the-art performance, with significant improvements in inference speed and reduced error accumulation. These results establish Fast3R as a robust alternative for multi-view applications, offering enhanced scalability without compromising reconstruction accuracy.
Omnidata: A Scalable Pipeline for Making Multi-Task Mid-Level Vision Datasets from 3D Scans
Oct 11, 2021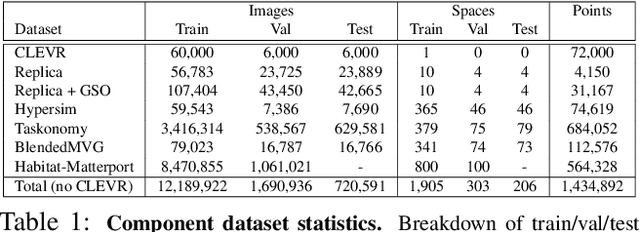
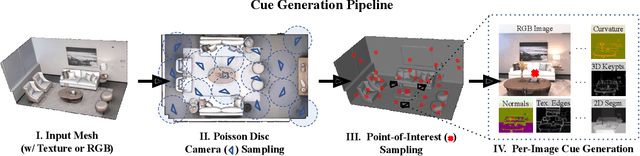
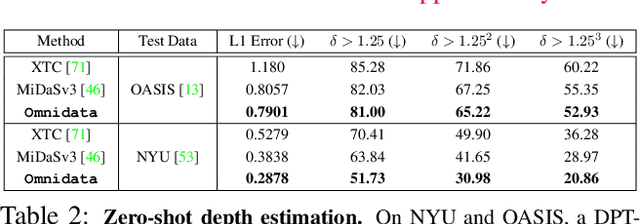

This paper introduces a pipeline to parametrically sample and render multi-task vision datasets from comprehensive 3D scans from the real world. Changing the sampling parameters allows one to "steer" the generated datasets to emphasize specific information. In addition to enabling interesting lines of research, we show the tooling and generated data suffice to train robust vision models. Common architectures trained on a generated starter dataset reached state-of-the-art performance on multiple common vision tasks and benchmarks, despite having seen no benchmark or non-pipeline data. The depth estimation network outperforms MiDaS and the surface normal estimation network is the first to achieve human-level performance for in-the-wild surface normal estimation -- at least according to one metric on the OASIS benchmark. The Dockerized pipeline with CLI, the (mostly python) code, PyTorch dataloaders for the generated data, the generated starter dataset, download scripts and other utilities are available through our project website, https://omnidata.vision.
Robust Policies via Mid-Level Visual Representations: An Experimental Study in Manipulation and Navigation
Nov 13, 2020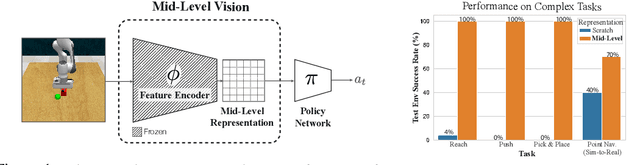
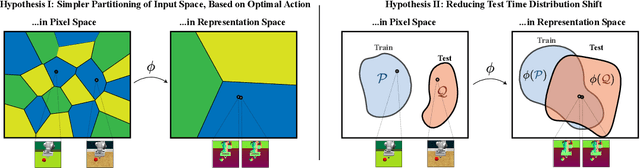
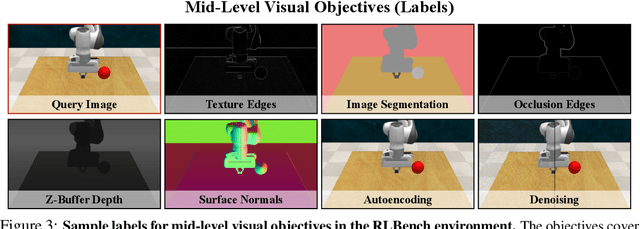
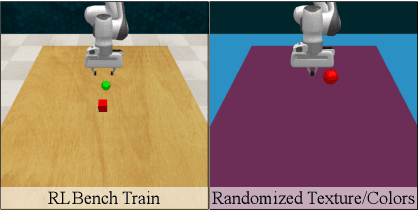
Vision-based robotics often separates the control loop into one module for perception and a separate module for control. It is possible to train the whole system end-to-end (e.g. with deep RL), but doing it "from scratch" comes with a high sample complexity cost and the final result is often brittle, failing unexpectedly if the test environment differs from that of training. We study the effects of using mid-level visual representations (features learned asynchronously for traditional computer vision objectives), as a generic and easy-to-decode perceptual state in an end-to-end RL framework. Mid-level representations encode invariances about the world, and we show that they aid generalization, improve sample complexity, and lead to a higher final performance. Compared to other approaches for incorporating invariances, such as domain randomization, asynchronously trained mid-level representations scale better: both to harder problems and to larger domain shifts. In practice, this means that mid-level representations could be used to successfully train policies for tasks where domain randomization and learning-from-scratch failed. We report results on both manipulation and navigation tasks, and for navigation include zero-shot sim-to-real experiments on real robots.
Robust Learning Through Cross-Task Consistency
Jun 07, 2020
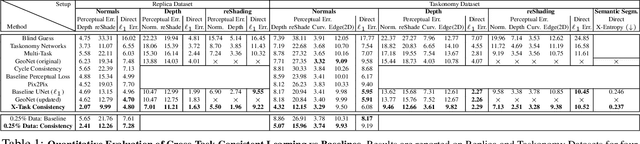
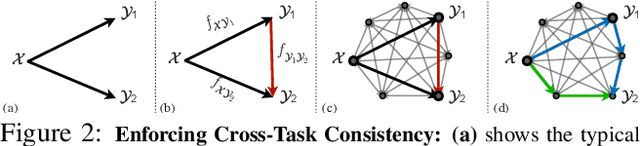
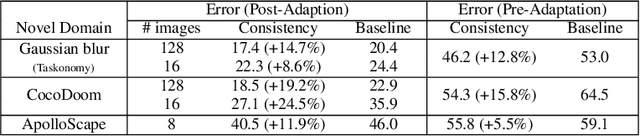
Visual perception entails solving a wide set of tasks, e.g., object detection, depth estimation, etc. The predictions made for multiple tasks from the same image are not independent, and therefore, are expected to be consistent. We propose a broadly applicable and fully computational method for augmenting learning with Cross-Task Consistency. The proposed formulation is based on inference-path invariance over a graph of arbitrary tasks. We observe that learning with cross-task consistency leads to more accurate predictions and better generalization to out-of-distribution inputs. This framework also leads to an informative unsupervised quantity, called Consistency Energy, based on measuring the intrinsic consistency of the system. Consistency Energy correlates well with the supervised error (r=0.67), thus it can be employed as an unsupervised confidence metric as well as for detection of out-of-distribution inputs (ROC-AUC=0.95). The evaluations are performed on multiple datasets, including Taskonomy, Replica, CocoDoom, and ApolloScape, and they benchmark cross-task consistency versus various baselines including conventional multi-task learning, cycle consistency, and analytical consistency.
Side-Tuning: Network Adaptation via Additive Side Networks
Dec 31, 2019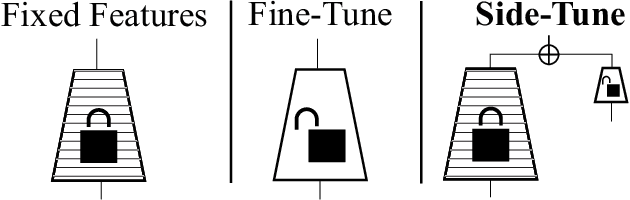

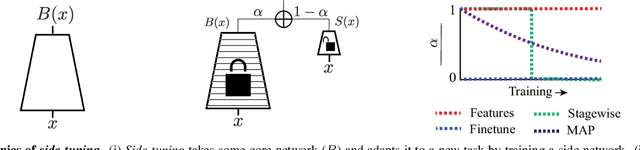
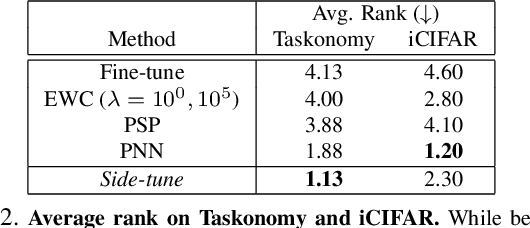
When training a neural network for a desired task, one may prefer to adapt a pre-trained network rather than start with a randomly initialized one -- due to lacking enough training data, performing lifelong learning where the system has to learn a new task while being previously trained for other tasks, or wishing to encode priors in the network via preset weights. The most commonly employed approaches for network adaptation are fine-tuning and using the pre-trained network as a fixed feature extractor, among others. In this paper, we propose a straightforward alternative: Side-Tuning. Side-tuning adapts a pre-trained network by training a lightweight "side" network that is fused with the (unchanged) pre-trained network using summation. This simple method works as well as or better than existing solutions while it resolves some of the basic issues with fine-tuning, fixed features, and several other common baselines. In particular, side-tuning is less prone to overfitting when little training data is available, yields better results than using a fixed feature extractor, and does not suffer from catastrophic forgetting in lifelong learning. We demonstrate the performance of side-tuning under a diverse set of scenarios, including lifelong learning (iCIFAR, Taskonomy), reinforcement learning, imitation learning (visual navigation in Habitat), NLP question-answering (SQuAD v2), and single-task transfer learning (Taskonomy), with consistently promising results.
Learning to Navigate Using Mid-Level Visual Priors
Dec 23, 2019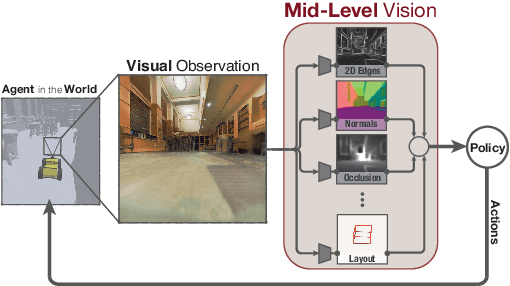
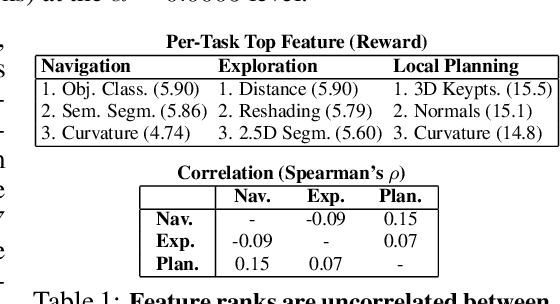
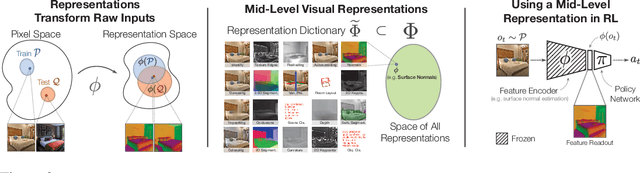

How much does having visual priors about the world (e.g. the fact that the world is 3D) assist in learning to perform downstream motor tasks (e.g. navigating a complex environment)? What are the consequences of not utilizing such visual priors in learning? We study these questions by integrating a generic perceptual skill set (a distance estimator, an edge detector, etc.) within a reinforcement learning framework (see Fig. 1). This skill set ("mid-level vision") provides the policy with a more processed state of the world compared to raw images. Our large-scale study demonstrates that using mid-level vision results in policies that learn faster, generalize better, and achieve higher final performance, when compared to learning from scratch and/or using state-of-the-art visual and non-visual representation learning methods. We show that conventional computer vision objectives are particularly effective in this regard and can be conveniently integrated into reinforcement learning frameworks. Finally, we found that no single visual representation was universally useful for all downstream tasks, hence we computationally derive a task-agnostic set of representations optimized to support arbitrary downstream tasks.
Mid-Level Visual Representations Improve Generalization and Sample Efficiency for Learning Active Tasks
Dec 31, 2018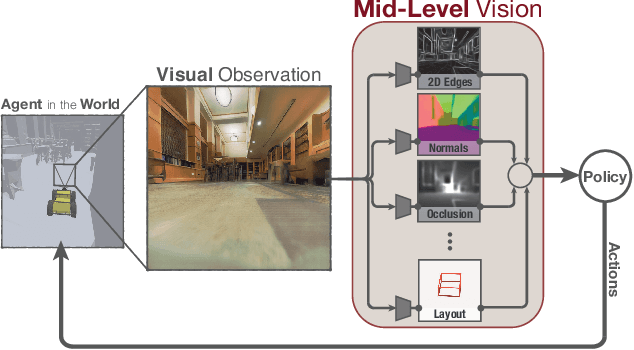
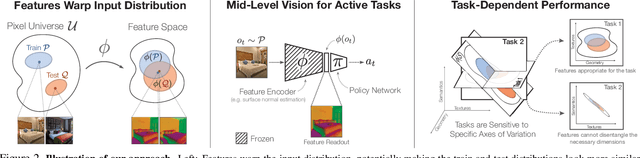
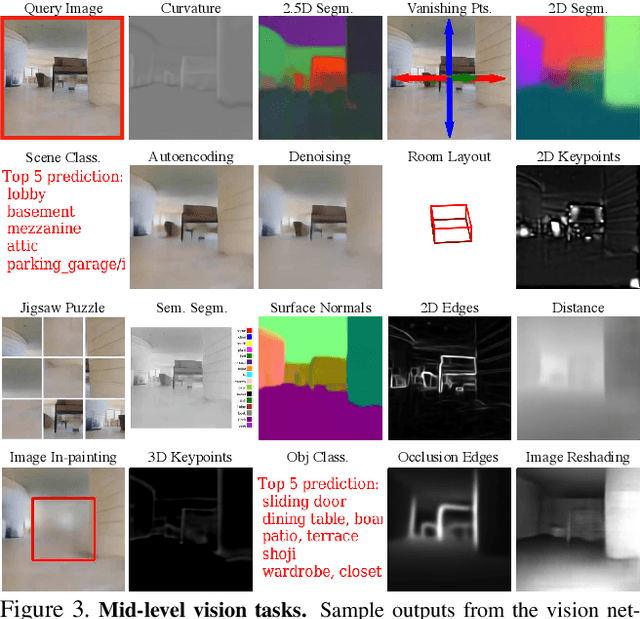
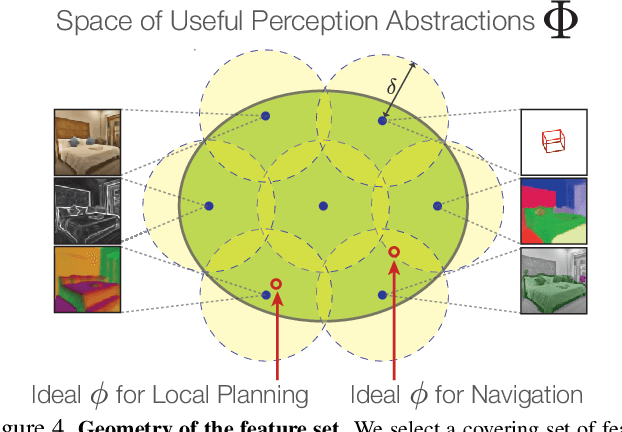
One of the ultimate promises of computer vision is to help robotic agents perform active tasks, like delivering packages or doing household chores. However, the conventional approach to solving "vision" is to define a set of offline recognition problems (e.g. object detection) and solve those first. This approach faces a challenge from the recent rise of Deep Reinforcement Learning frameworks that learn active tasks from scratch using images as input. This poses a set of fundamental questions: what is the role of computer vision if everything can be learned from scratch? Could intermediate vision tasks actually be useful for performing arbitrary downstream active tasks? We show that proper use of mid-level perception confers significant advantages over training from scratch. We implement a perception module as a set of mid-level visual representations and demonstrate that learning active tasks with mid-level features is significantly more sample-efficient than scratch and able to generalize in situations where the from-scratch approach fails. However, we show that realizing these gains requires careful selection of the particular mid-level features for each downstream task. Finally, we put forth a simple and efficient perception module based on the results of our study, which can be adopted as a rather generic perception module for active frameworks.