 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergent Functions, Divergent Forms
May 27, 2025We introduce LOKI, a compute-efficient framework for co-designing morphologies and control policies that generalize across unseen tasks. Inspired by biological adaptation -- where animals quickly adjust to morphological changes -- our method overcomes the inefficiencies of traditional evolutionary and quality-diversity algorithms. We propose learning convergent functions: shared control policies trained across clusters of morphologically similar designs in a learned latent space, drastically reducing the training cost per design. Simultaneously, we promote divergent forms by replacing mutation with dynamic local search, enabling broader exploration and preventing premature convergence. The policy reuse allows us to explore 780$\times$ more designs using 78% fewer simulation steps and 40% less compute per design. Local competition paired with a broader search results in a diverse set of high-performing final morphologies. Using the UNIMAL design space and a flat-terrain locomotion task, LOKI discovers a rich variety of designs -- ranging from quadrupeds to crabs, bipedals, and spinners -- far more diverse than those produced by prior work. These morphologies also transfer better to unseen downstream tasks in agility, stability, and manipulation domains (e.g., 2$\times$ higher reward on bump and push box incline tasks). Overall, our approach produces designs that are both diverse and adaptable, with substantially greater sample efficiency than existing co-design methods. (Project website: https://loki-codesign.github.io/)
PointArena: Probing Multimodal Grounding Through Language-Guided Pointing
May 15, 2025Pointing serves as a fundamental and intuitive mechanism for grounding language within visual contexts, with applications spanning robotics, assistive technologies, and interactive AI systems. While recent multimodal models have started to support pointing capabilities, existing benchmarks typically focus only on referential object localization tasks. We introduce PointArena, a comprehensive platform for evaluating multimodal pointing across diverse reasoning scenarios. PointArena comprises three components: (1) Point-Bench, a curated dataset containing approximately 1,000 pointing tasks across five reasoning categories; (2) Point-Battle, an interactive, web-based arena facilitating blind, pairwise model comparisons, which has already gathered over 4,500 anonymized votes; and (3) Point-Act, a real-world robotic manipulation system allowing users to directly evaluate multimodal model pointing capabilities in practical settings. We conducted extensive evaluations of both state-of-the-art open-source and proprietary multimodal models. Results indicate that Molmo-72B consistently outperforms other models, though proprietary models increasingly demonstrate comparable performance. Additionally, we find that supervised training specifically targeting pointing tasks significantly enhances model performance. Across our multi-stage evaluation pipeline, we also observe strong correlations, underscoring the critical role of precise pointing capabilities in enabling multimodal models to effectively bridge abstract reasoning with concrete, real-world actions. Project page: https://pointarena.github.io/
The One RING: a Robotic Indoor Navigation Generalist
Dec 18, 2024



Modern robots vary significantly in shape, size, and sensor configurations used to perceive and interact with their environments. However, most navigation policies are embodiment-specific; a policy learned using one robot's configuration does not typically gracefully generalize to another. Even small changes in the body size or camera viewpoint may cause failures. With the recent surge in custom hardware developments, it is necessary to learn a single policy that can be transferred to other embodiments, eliminating the need to (re)train for each specific robot. In this paper, we introduce RING (Robotic Indoor Navigation Generalist), an embodiment-agnostic policy, trained solely in simulation with diverse randomly initialized embodiments at scale. Specifically, we augment the AI2-THOR simulator with the ability to instantiate robot embodiments with controllable configurations, varying across body size, rotation pivot point, and camera configurations. In the visual object-goal navigation task, RING achieves robust performance on real unseen robot platforms (Stretch RE-1, LoCoBot, Unitree's Go1), achieving an average of 72.1% and 78.9% success rate across 5 embodiments in simulation and 4 robot platforms in the real world. (project website: https://one-ring-policy.allen.ai/)
Selective Visual Representations Improve Convergence and Generalization for Embodied AI
Nov 07, 2023



Embodied AI models often employ off the shelf vision backbones like CLIP to encode their visual observations. Although such general purpose representations encode rich syntactic and semantic information about the scene, much of this information is often irrelevant to the specific task at hand. This introduces noise within the learning process and distracts the agent's focus from task-relevant visual cues. Inspired by selective attention in humans-the process through which people filter their perception based on their experiences, knowledge, and the task at hand-we introduce a parameter-efficient approach to filter visual stimuli for embodied AI. Our approach induces a task-conditioned bottleneck using a small learnable codebook module. This codebook is trained jointly to optimize task reward and acts as a task-conditioned selective filter over the visual observation. Our experiments showcase state-of-the-art performance for object goal navigation and object displacement across 5 benchmarks, ProcTHOR, ArchitecTHOR, RoboTHOR, AI2-iTHOR, and ManipulaTHOR. The filtered representations produced by the codebook are also able generalize better and converge faster when adapted to other simulation environments such as Habitat. Our qualitative analyses show that agents explore their environments more effectively and their representations retain task-relevant information like target object recognition while ignoring superfluous information about other objects. Code and pretrained models are available at our project website: https://embodied-codebook.github.io.
Omnidata: A Scalable Pipeline for Making Multi-Task Mid-Level Vision Datasets from 3D Scans
Oct 11, 2021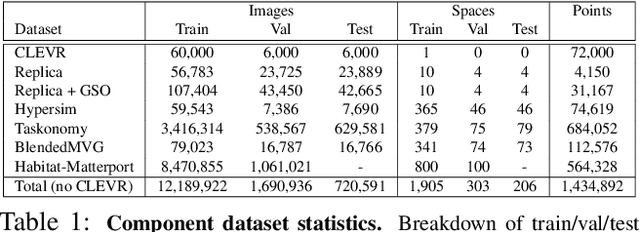
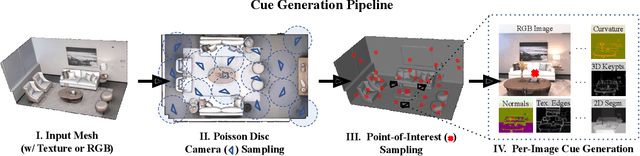
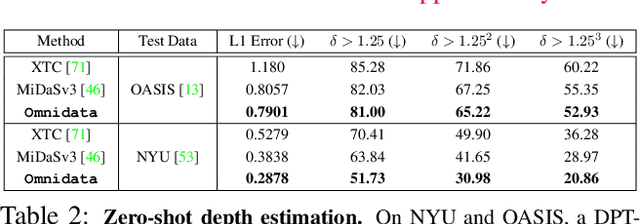

This paper introduces a pipeline to parametrically sample and render multi-task vision datasets from comprehensive 3D scans from the real world. Changing the sampling parameters allows one to "steer" the generated datasets to emphasize specific information. In addition to enabling interesting lines of research, we show the tooling and generated data suffice to train robust vision models. Common architectures trained on a generated starter dataset reached state-of-the-art performance on multiple common vision tasks and benchmarks, despite having seen no benchmark or non-pipeline data. The depth estimation network outperforms MiDaS and the surface normal estimation network is the first to achieve human-level performance for in-the-wild surface normal estimation -- at least according to one metric on the OASIS benchmark. The Dockerized pipeline with CLI, the (mostly python) code, PyTorch dataloaders for the generated data, the generated starter dataset, download scripts and other utilities are available through our project website, https://omnidata.vision.
Puzzle-AE: Novelty Detection in Images through Solving Puzzles
Aug 29, 2020
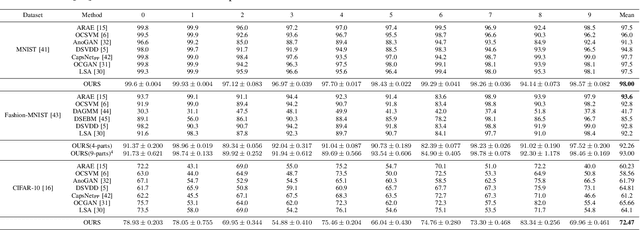


Autoencoder (AE) has proved to be an effective framework for novelty detection. However, they do not typically show promising results on other kinds of real-world datasets, which are exhibiting high intra-class variations, such as CIFAR-10. AEs are not generally able to learn a latent space that solely captures common features of the normal class, resulting in both high false positive and false negative rates due to modeling features that are irrelevant to the normal class. Recently, self-supervised learning has shown great promise in representation learning. To this end, we propose a new AE framework that is trained based on solving puzzles on randomly permuted image patches. Based on this framework, we achieve competitive or superior results compared to SOTA anomaly detection methods on various toy and real-world datasets. Unlike many competitors in this field, the proposed framework is stable, has real-time performance, more general and agnostic to choices of the model hyper-parameters, can work effectively under small sample size settings, and does not require unprincipled early stopping.