 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBarcodeBERT: Transformers for Biodiversity Analysis
Nov 04, 2023



Understanding biodiversity is a global challenge, in which DNA barcodes - short snippets of DNA that cluster by species - play a pivotal role. In particular, invertebrates, a highly diverse and under-explored group, pose unique taxonomic complexities. We explore machine learning approaches, comparing supervised CNNs, fine-tuned foundation models, and a DNA barcode-specific masking strategy across datasets of varying complexity. While simpler datasets and tasks favor supervised CNNs or fine-tuned transformers, challenging species-level identification demands a paradigm shift towards self-supervised pretraining. We propose BarcodeBERT, the first self-supervised method for general biodiversity analysis, leveraging a 1.5 M invertebrate DNA barcode reference library. This work highlights how dataset specifics and coverage impact model selection, and underscores the role of self-supervised pretraining in achieving high-accuracy DNA barcode-based identification at the species and genus level. Indeed, without the fine-tuning step, BarcodeBERT pretrained on a large DNA barcode dataset outperforms DNABERT and DNABERT-2 on multiple downstream classification tasks. The code repository is available at https://github.com/Kari-Genomics-Lab/BarcodeBERT
Multiresolution Knowledge Distillation for Anomaly Detection
Nov 22, 2020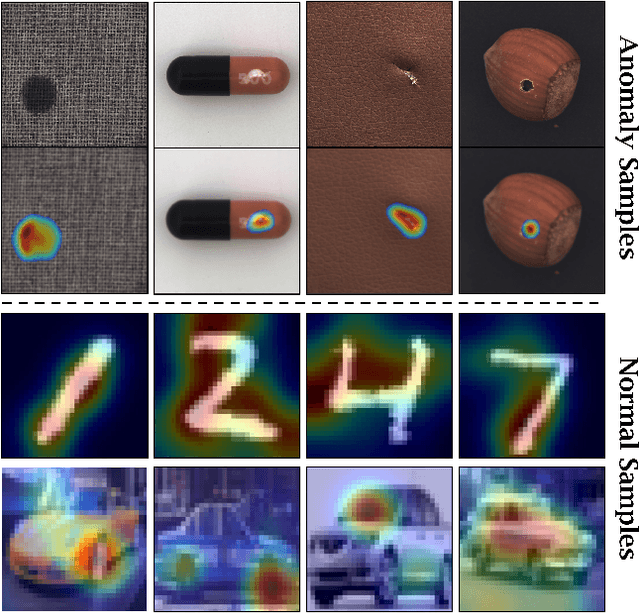
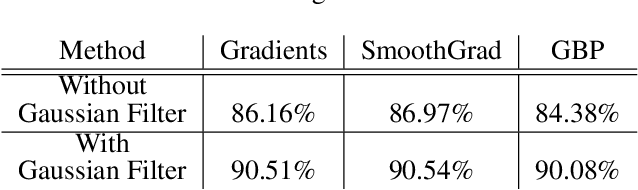
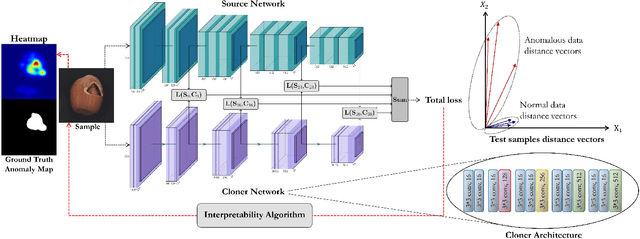
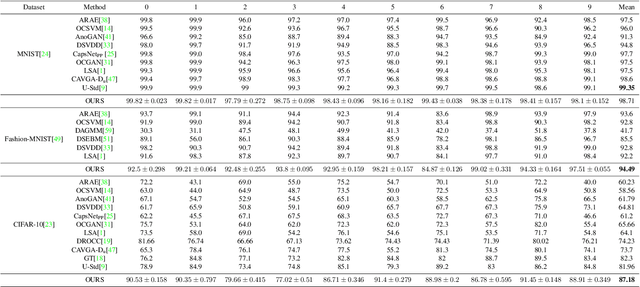
Unsupervised representation learning has proved to be a critical component of anomaly detection/localization in images. The challenges to learn such a representation are two-fold. Firstly, the sample size is not often large enough to learn a rich generalizable representation through conventional techniques. Secondly, while only normal samples are available at training, the learned features should be discriminative of normal and anomalous samples. Here, we propose to use the "distillation" of features at various layers of an expert network, pre-trained on ImageNet, into a simpler cloner network to tackle both issues. We detect and localize anomalies using the discrepancy between the expert and cloner networks' intermediate activation values given the input data. We show that considering multiple intermediate hints in distillation leads to better exploiting the expert's knowledge and more distinctive discrepancy compared to solely utilizing the last layer activation values. Notably, previous methods either fail in precise anomaly localization or need expensive region-based training. In contrast, with no need for any special or intensive training procedure, we incorporate interpretability algorithms in our novel framework for the localization of anomalous regions. Despite the striking contrast between some test datasets and ImageNet, we achieve competitive or significantly superior results compared to the SOTA methods on MNIST, F-MNIST, CIFAR-10, MVTecAD, Retinal-OCT, and two Medical datasets on both anomaly detection and localization.
Puzzle-AE: Novelty Detection in Images through Solving Puzzles
Aug 29, 2020


Autoencoder (AE) has proved to be an effective framework for novelty detection. However, they do not typically show promising results on other kinds of real-world datasets, which are exhibiting high intra-class variations, such as CIFAR-10. AEs are not generally able to learn a latent space that solely captures common features of the normal class, resulting in both high false positive and false negative rates due to modeling features that are irrelevant to the normal class. Recently, self-supervised learning has shown great promise in representation learning. To this end, we propose a new AE framework that is trained based on solving puzzles on randomly permuted image patches. Based on this framework, we achieve competitive or superior results compared to SOTA anomaly detection methods on various toy and real-world datasets. Unlike many competitors in this field, the proposed framework is stable, has real-time performance, more general and agnostic to choices of the model hyper-parameters, can work effectively under small sample size settings, and does not require unprincipled early stopping.