 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOcclusion-Ordered Semantic Instance Segmentation
Apr 18, 2025



Standard semantic instance segmentation provides useful, but inherently 2D information from a single image. To enable 3D analysis, one usually integrates absolute monocular depth estimation with instance segmentation. However, monocular depth is a difficult task. Instead, we leverage a simpler single-image task, occlusion-based relative depth ordering, providing coarser but useful 3D information. We show that relative depth ordering works more reliably from occlusions than from absolute depth. We propose to solve the joint task of relative depth ordering and segmentation of instances based on occlusions. We call this task Occlusion-Ordered Semantic Instance Segmentation (OOSIS). We develop an approach to OOSIS that extracts instances and their occlusion order simultaneously from oriented occlusion boundaries and semantic segmentation. Unlike popular detect-and-segment framework for instance segmentation, combining occlusion ordering with instance segmentation allows a simple and clean formulation of OOSIS as a labeling problem. As a part of our solution for OOSIS, we develop a novel oriented occlusion boundaries approach that significantly outperforms prior work. We also develop a new joint OOSIS metric based both on instance mask accuracy and correctness of their occlusion order. We achieve better performance than strong baselines on KINS and COCOA datasets.
Towards Semantic Interpretation of Thoracic Disease and COVID-19 Diagnosis Models
Apr 04, 2021
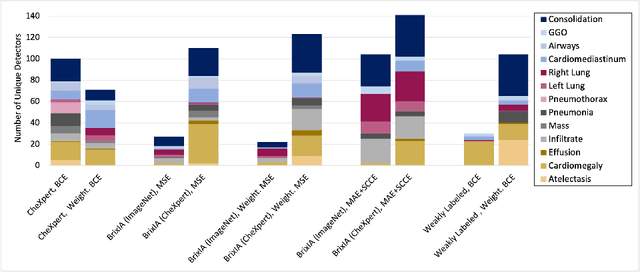
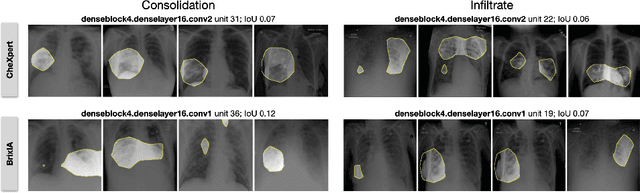

Convolutional neural networks are showing promise in the automatic diagnosis of thoracic pathologies on chest x-rays. Their black-box nature has sparked many recent works to explain the prediction via input feature attribution methods (aka saliency methods). However, input feature attribution methods merely identify the importance of input regions for the prediction and lack semantic interpretation of model behavior. In this work, we first identify the semantics associated with internal units (feature maps) of the network. We proceed to investigate the following questions; Does a regression model that is only trained with COVID-19 severity scores implicitly learn visual patterns associated with thoracic pathologies? Does a network that is trained on weakly labeled data (e.g. healthy, unhealthy) implicitly learn pathologies? Moreover, we investigate the effect of pretraining and data imbalance on the interpretability of learned features. In addition to the analysis, we propose semantic attribution to semantically explain each prediction. We present our findings using publicly available chest pathologies (CheXpert, NIH ChestX-ray8) and COVID-19 datasets (BrixIA, and COVID-19 chest X-ray segmentation dataset). The Code is publicly available.
Neural Response Interpretation through the Lens of Critical Pathways
Mar 31, 2021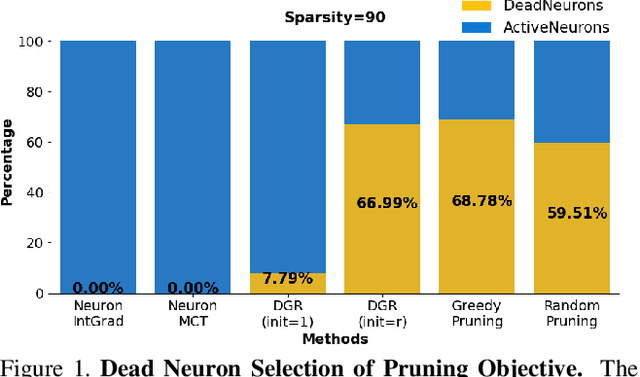
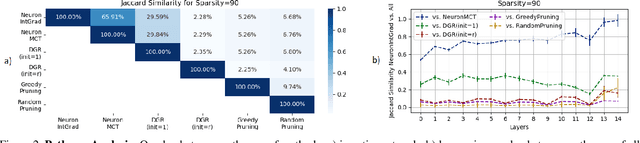
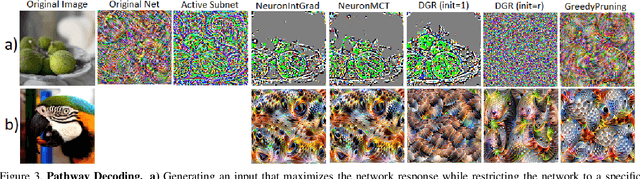

Is critical input information encoded in specific sparse pathways within the neural network? In this work, we discuss the problem of identifying these critical pathways and subsequently leverage them for interpreting the network's response to an input. The pruning objective -- selecting the smallest group of neurons for which the response remains equivalent to the original network -- has been previously proposed for identifying critical pathways. We demonstrate that sparse pathways derived from pruning do not necessarily encode critical input information. To ensure sparse pathways include critical fragments of the encoded input information, we propose pathway selection via neurons' contribution to the response. We proceed to explain how critical pathways can reveal critical input features. We prove that pathways selected via neuron contribution are locally linear (in an L2-ball), a property that we use for proposing a feature attribution method: "pathway gradient". We validate our interpretation method using mainstream evaluation experiments. The validation of pathway gradient interpretation method further confirms that selected pathways using neuron contributions correspond to critical input features. The code is publicly available.
Rethinking Positive Aggregation and Propagation of Gradients in Gradient-based Saliency Methods
Dec 01, 2020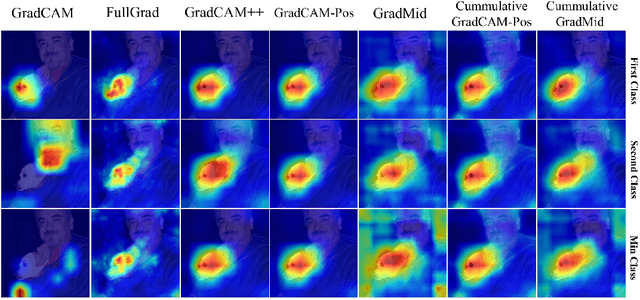
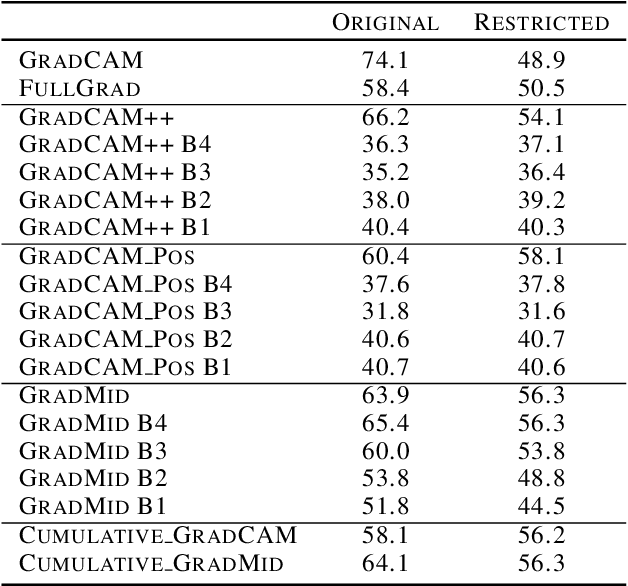
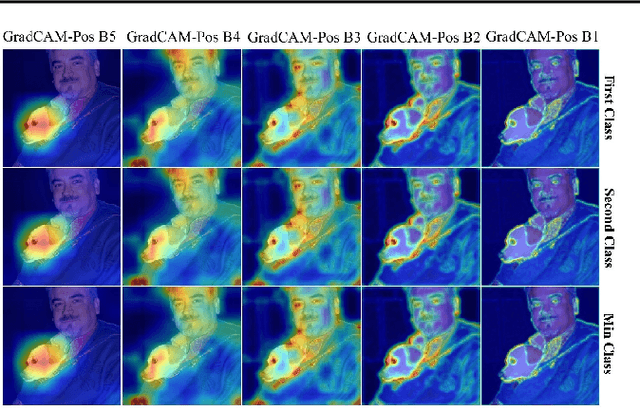

Saliency methods interpret the prediction of a neural network by showing the importance of input elements for that prediction. A popular family of saliency methods utilize gradient information. In this work, we empirically show that two approaches for handling the gradient information, namely positive aggregation, and positive propagation, break these methods. Though these methods reflect visually salient information in the input, they do not explain the model prediction anymore as the generated saliency maps are insensitive to the predicted output and are insensitive to model parameter randomization. Specifically for methods that aggregate the gradients of a chosen layer such as GradCAM++ and FullGrad, exclusively aggregating positive gradients is detrimental. We further support this by proposing several variants of aggregation methods with positive handling of gradient information. For methods that backpropagate gradient information such as LRP, RectGrad, and Guided Backpropagation, we show the destructive effect of exclusively propagating positive gradient information.
Multiresolution Knowledge Distillation for Anomaly Detection
Nov 22, 2020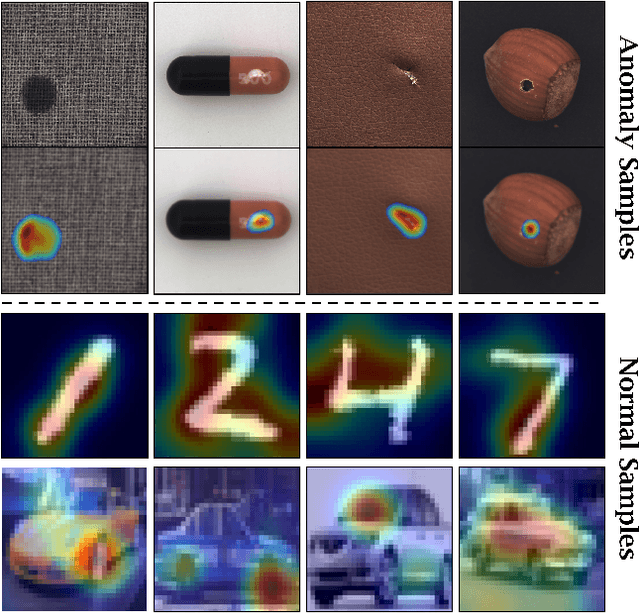
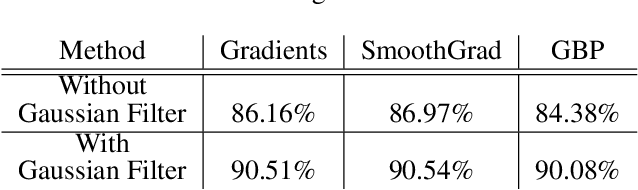
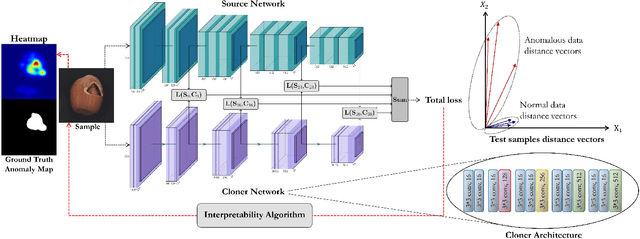
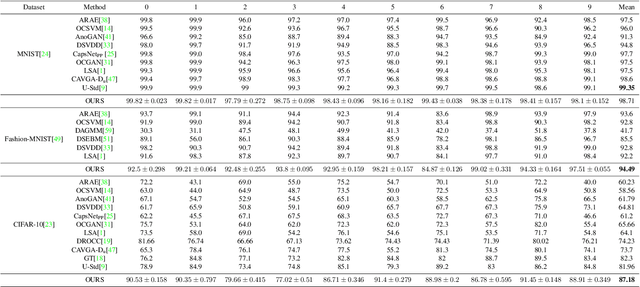
Unsupervised representation learning has proved to be a critical component of anomaly detection/localization in images. The challenges to learn such a representation are two-fold. Firstly, the sample size is not often large enough to learn a rich generalizable representation through conventional techniques. Secondly, while only normal samples are available at training, the learned features should be discriminative of normal and anomalous samples. Here, we propose to use the "distillation" of features at various layers of an expert network, pre-trained on ImageNet, into a simpler cloner network to tackle both issues. We detect and localize anomalies using the discrepancy between the expert and cloner networks' intermediate activation values given the input data. We show that considering multiple intermediate hints in distillation leads to better exploiting the expert's knowledge and more distinctive discrepancy compared to solely utilizing the last layer activation values. Notably, previous methods either fail in precise anomaly localization or need expensive region-based training. In contrast, with no need for any special or intensive training procedure, we incorporate interpretability algorithms in our novel framework for the localization of anomalous regions. Despite the striking contrast between some test datasets and ImageNet, we achieve competitive or significantly superior results compared to the SOTA methods on MNIST, F-MNIST, CIFAR-10, MVTecAD, Retinal-OCT, and two Medical datasets on both anomaly detection and localization.
Explaining Neural Networks via Perturbing Important Learned Features
Nov 25, 2019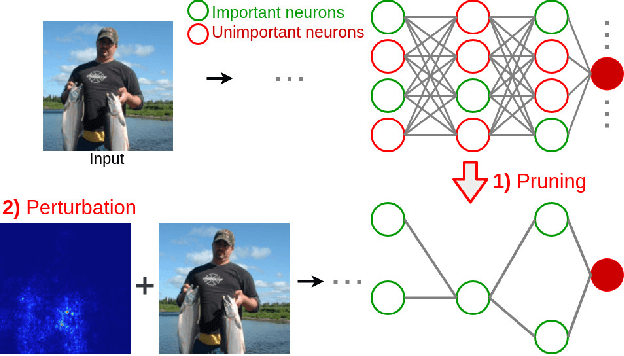
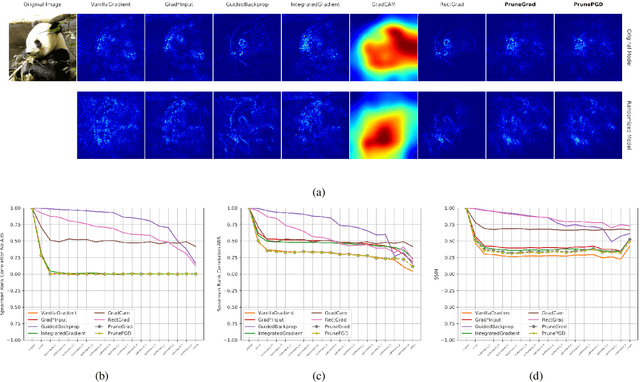
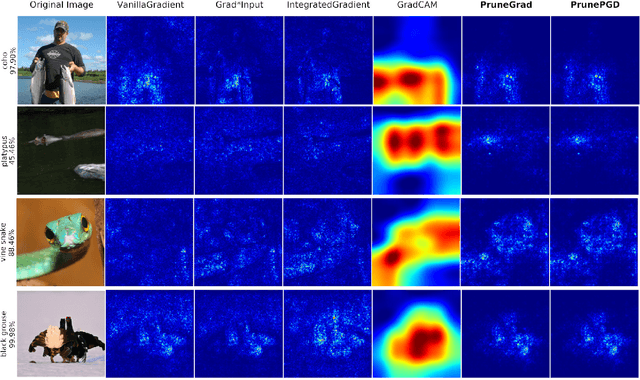
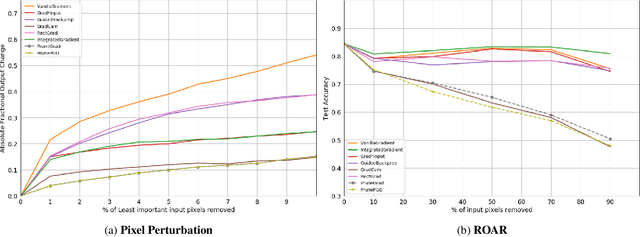
Attributing the output of a neural network to the contribution of given input elements is one way of shedding light on the black box nature of neural networks. We propose a novel input feature attribution method that finds an input perturbation that maximally changes the output neuron by exclusively perturbing important hidden neurons (i.e. learned features) on the path to output neuron. Given an input, this is achieved by 1) pruning unimportant neurons, and subsequently 2) finding a local input perturbation that maximizes the output in the pruned network. Since our method considers the importance of hidden neurons (high-level features), it inherently considers interdependencies between multiple input elements, which is vital for input feature attribution. We propose PruneGrad, an efficient gradient-based solution for the pruning and perturbation steps of our method. The efficacy of our method is evaluated by quantitatively benchmarking against other attribution methods using 1) sanity checks, 2) pixel perturbation, and 3) Remove and Retrain (ROAR). Our results show that while most of the existing attribution methods are prone to fail or get mediocre results in at least one benchmark, our proposed method achieves state of the art results in all three benchmarks. The results are further supported by comparative visual evaluation.