 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Self-labeling and Potts Relaxations for Weakly-Supervised Segmentation
Jul 02, 2025We consider weakly supervised segmentation where only a fraction of pixels have ground truth labels (scribbles) and focus on a self-labeling approach optimizing relaxations of the standard unsupervised CRF/Potts loss on unlabeled pixels. While WSSS methods can directly optimize such losses via gradient descent, prior work suggests that higher-order optimization can improve network training by introducing hidden pseudo-labels and powerful CRF sub-problem solvers, e.g. graph cut. However, previously used hard pseudo-labels can not represent class uncertainty or errors, which motivates soft self-labeling. We derive a principled auxiliary loss and systematically evaluate standard and new CRF relaxations (convex and non-convex), neighborhood systems, and terms connecting network predictions with soft pseudo-labels. We also propose a general continuous sub-problem solver. Using only standard architectures, soft self-labeling consistently improves scribble-based training and outperforms significantly more complex specialized WSSS systems. It can outperform full pixel-precise supervision. Our general ideas apply to other weakly-supervised problems/systems.
Occlusion-Ordered Semantic Instance Segmentation
Apr 18, 2025



Standard semantic instance segmentation provides useful, but inherently 2D information from a single image. To enable 3D analysis, one usually integrates absolute monocular depth estimation with instance segmentation. However, monocular depth is a difficult task. Instead, we leverage a simpler single-image task, occlusion-based relative depth ordering, providing coarser but useful 3D information. We show that relative depth ordering works more reliably from occlusions than from absolute depth. We propose to solve the joint task of relative depth ordering and segmentation of instances based on occlusions. We call this task Occlusion-Ordered Semantic Instance Segmentation (OOSIS). We develop an approach to OOSIS that extracts instances and their occlusion order simultaneously from oriented occlusion boundaries and semantic segmentation. Unlike popular detect-and-segment framework for instance segmentation, combining occlusion ordering with instance segmentation allows a simple and clean formulation of OOSIS as a labeling problem. As a part of our solution for OOSIS, we develop a novel oriented occlusion boundaries approach that significantly outperforms prior work. We also develop a new joint OOSIS metric based both on instance mask accuracy and correctness of their occlusion order. We achieve better performance than strong baselines on KINS and COCOA datasets.
Approximate Size Targets Are Sufficient for Accurate Semantic Segmentation
Mar 10, 2025This paper demonstrates a surprising result for segmentation with image-level targets: extending binary class tags to approximate relative object-size distributions allows off-the-shelf architectures to solve the segmentation problem. A straightforward zero-avoiding KL-divergence loss for average predictions produces segmentation accuracy comparable to the standard pixel-precise supervision with full ground truth masks. In contrast, current results based on class tags typically require complex non-reproducible architectural modifications and specialized multi-stage training procedures. Our ideas are validated on PASCAL VOC using our new human annotations of approximate object sizes. We also show the results on COCO and medical data using synthetically corrupted size targets. All standard networks demonstrate robustness to the size targets' errors. For some classes, the validation accuracy is significantly better than the pixel-level supervision; the latter is not robust to errors in the masks. Our work provides new ideas and insights on image-level supervision in segmentation and may encourage other simple general solutions to the problem.
Collision Cross-entropy and EM Algorithm for Self-labeled Classification
Mar 16, 2023We propose "collision cross-entropy" as a robust alternative to the Shannon's cross-entropy in the context of self-labeled classification with posterior models. Assuming unlabeled data, self-labeling works by estimating latent pseudo-labels, categorical distributions y, that optimize some discriminative clustering criteria, e.g. "decisiveness" and "fairness". All existing self-labeled losses incorporate Shannon's cross-entropy term targeting the model prediction, softmax, at the estimated distribution y. In fact, softmax is trained to mimic the uncertainty in y exactly. Instead, we propose the negative log-likelihood of "collision" to maximize the probability of equality between two random variables represented by distributions softmax and y. We show that our loss satisfies some properties of a generalized cross-entropy. Interestingly, it agrees with the Shannon's cross-entropy for one-hot pseudo-labels y, but the training from softer labels weakens. For example, if y is a uniform distribution at some data point, it has zero contribution to the training. Our self-labeling loss combining collision cross entropy with basic clustering criteria is convex w.r.t. pseudo-labels, but non-trivial to optimize over the probability simplex. We derive a practical EM algorithm optimizing pseudo-labels y significantly faster than generic methods, e.g. the projectile gradient descent. The collision cross-entropy consistently improves the results on multiple self-labeled clustering examples using different DNNs.
Revisiting Discriminative Entropy Clustering and its relation to K-means
Jan 26, 2023



Maximization of mutual information between the model's input and output is formally related to "decisiveness" and "fairness" of the softmax predictions, motivating such unsupervised entropy-based losses for discriminative neural networks. Recent self-labeling methods based on such losses represent the state of the art in deep clustering. However, some important properties of entropy clustering are not well-known, or even misunderstood. For example, we provide a counterexample to prior claims about equivalence to variance clustering (K-means) and point out technical mistakes in such theories. We discuss the fundamental differences between these discriminative and generative clustering approaches. Moreover, we show the susceptibility of standard entropy clustering to narrow margins and motivate an explicit margin maximization term. We also propose an improved self-labeling loss; it is robust to pseudo-labeling errors and enforces stronger fairness. We develop an EM algorithm for our loss that is significantly faster than the standard alternatives. Our results improve the state-of-the-art on standard benchmarks.
Robust Trust Region for Weakly Supervised Segmentation
Apr 05, 2021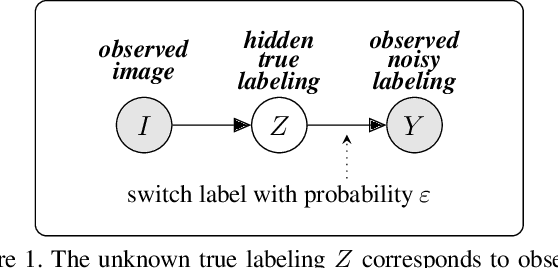
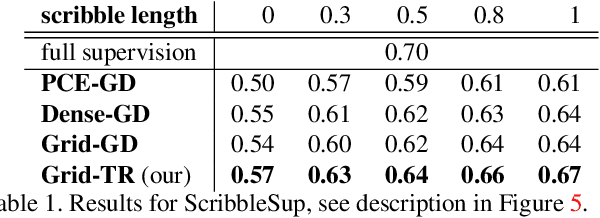
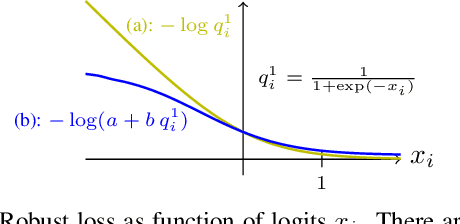
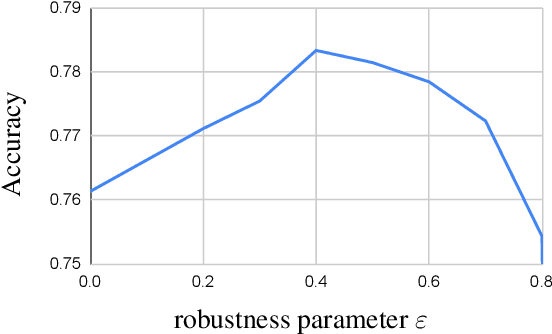
Acquisition of training data for the standard semantic segmentation is expensive if requiring that each pixel is labeled. Yet, current methods significantly deteriorate in weakly supervised settings, e.g. where a fraction of pixels is labeled or when only image-level tags are available. It has been shown that regularized losses - originally developed for unsupervised low-level segmentation and representing geometric priors on pixel labels - can considerably improve the quality of weakly supervised training. However, many common priors require optimization stronger than gradient descent. Thus, such regularizers have limited applicability in deep learning. We propose a new robust trust region approach for regularized losses improving the state-of-the-art results. Our approach can be seen as a higher-order generalization of the classic chain rule. It allows neural network optimization to use strong low-level solvers for the corresponding regularizers, including discrete ones.
Confluent Vessel Trees with Accurate Bifurcations
Mar 26, 2021
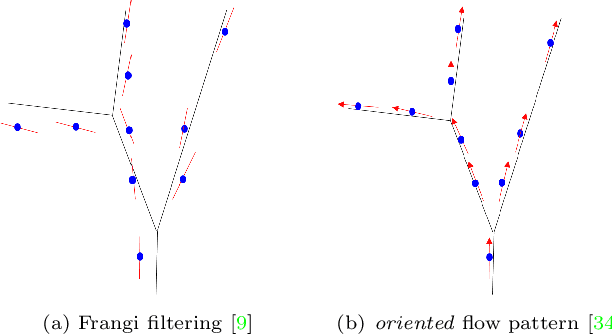
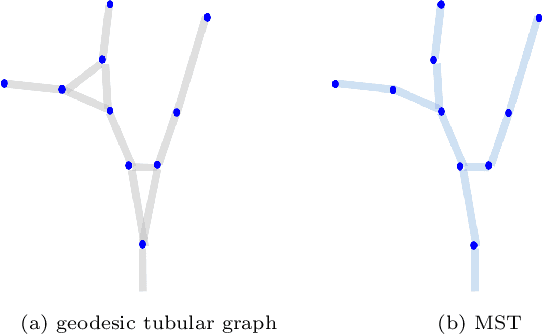

We are interested in unsupervised reconstruction of complex near-capillary vasculature with thousands of bifurcations where supervision and learning are infeasible. Unsupervised methods can use many structural constraints, e.g. topology, geometry, physics. Common techniques use variants of MST on geodesic tubular graphs minimizing symmetric pairwise costs, i.e. distances. We show limitations of such standard undirected tubular graphs producing typical errors at bifurcations where flow "directedness" is critical. We introduce a new general concept of confluence for continuous oriented curves forming vessel trees and show how to enforce it on discrete tubular graphs. While confluence is a high-order property, we present an efficient practical algorithm for reconstructing confluent vessel trees using minimum arborescence on a directed graph enforcing confluence via simple flow-extrapolating arc construction. Empirical tests on large near-capillary sub-voxel vasculature volumes demonstrate significantly improved reconstruction accuracy at bifurcations. Our code has also been made publicly available.
RePose: Learning Deep Kinematic Priors for Fast Human Pose Estimation
Feb 10, 2020
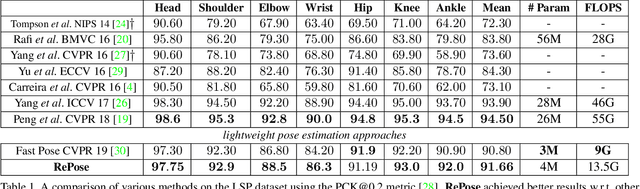
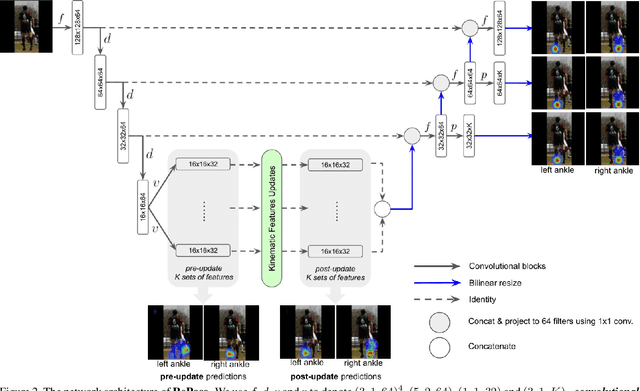
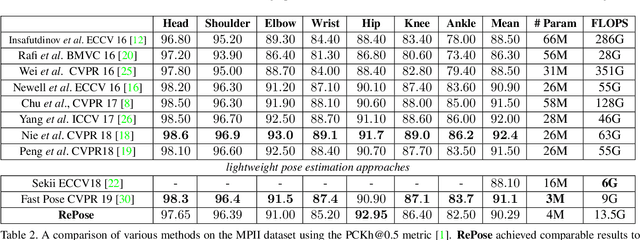
We propose a novel efficient and lightweight model for human pose estimation from a single image. Our model is designed to achieve competitive results at a fraction of the number of parameters and computational cost of various state-of-the-art methods. To this end, we explicitly incorporate part-based structural and geometric priors in a hierarchical prediction framework. At the coarsest resolution, and in a manner similar to classical part-based approaches, we leverage the kinematic structure of the human body to propagate convolutional feature updates between the keypoints or body parts. Unlike classical approaches, we adopt end-to-end training to learn this geometric prior through feature updates from data. We then propagate the feature representation at the coarsest resolution up the hierarchy to refine the predicted pose in a coarse-to-fine fashion. The final network effectively models the geometric prior and intuition within a lightweight deep neural network, yielding state-of-the-art results for a model of this size on two standard datasets, Leeds Sports Pose and MPII Human Pose.
Image Segmentation Using Deep Learning: A Survey
Jan 18, 2020
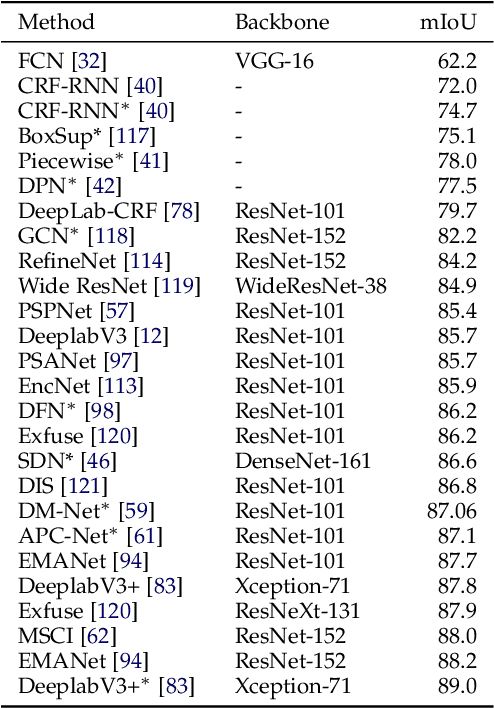
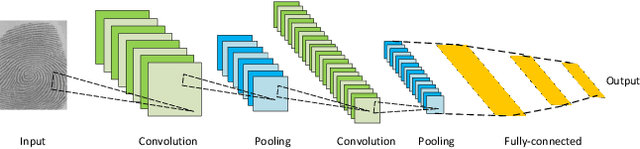
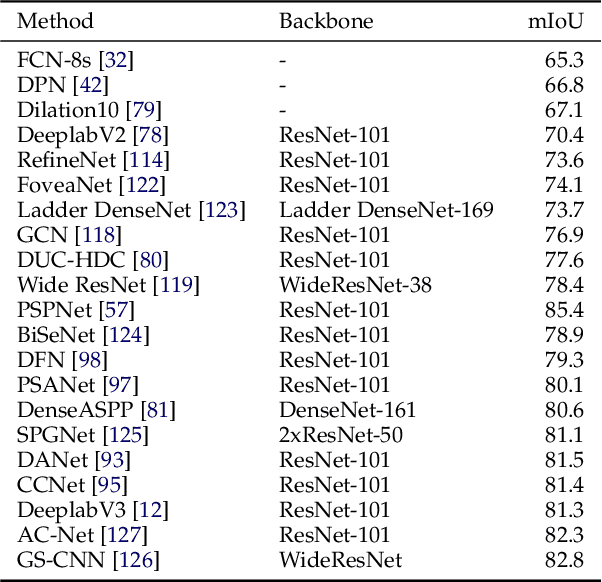
Image segmentation is a key topic in image processing and computer vision with applications such as scene understanding, medical image analysis, robotic perception, video surveillance, augmented reality, and image compression, among many others. Various algorithms for image segmentation have been developed in the literature. Recently, due to the success of deep learning models in a wide range of vision applications, there has been a substantial amount of works aimed at developing image segmentation approaches using deep learning models. In this survey, we provide a comprehensive review of the literature at the time of this writing, covering a broad spectrum of pioneering works for semantic and instance-level segmentation, including fully convolutional pixel-labeling networks, encoder-decoder architectures, multi-scale and pyramid based approaches, recurrent networks, visual attention models, and generative models in adversarial settings. We investigate the similarity, strengths and challenges of these deep learning models, examine the most widely used datasets, report performances, and discuss promising future research directions in this area.
Efficient Segmentation: Learning Downsampling Near Semantic Boundaries
Jul 16, 2019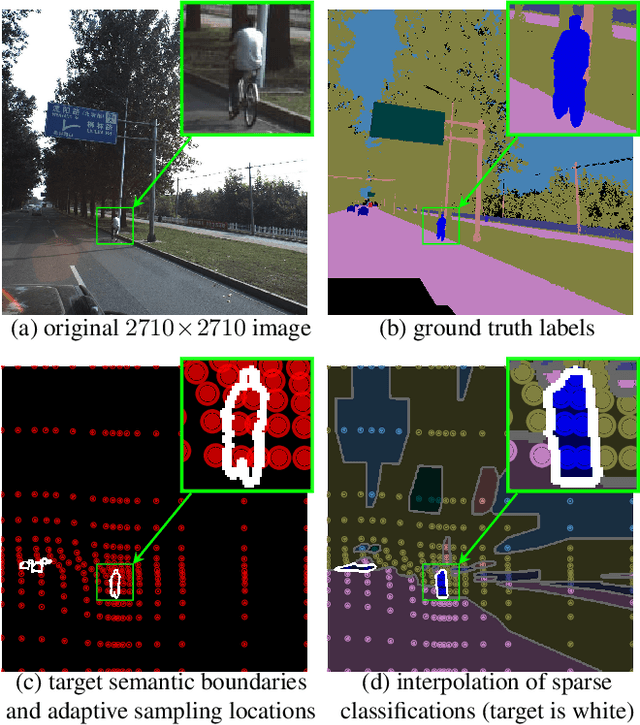
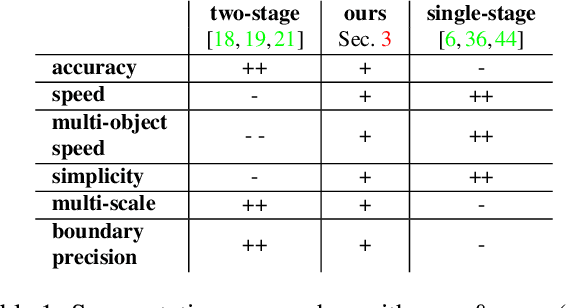
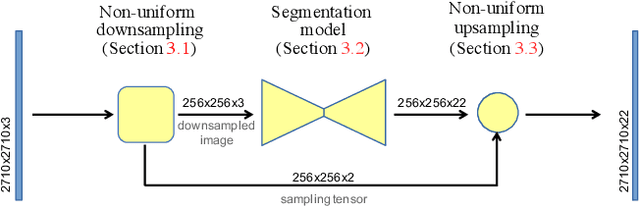
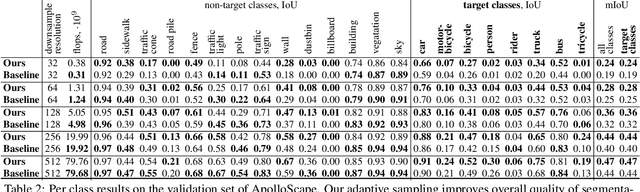
Many automated processes such as auto-piloting rely on a good semantic segmentation as a critical component. To speed up performance, it is common to downsample the input frame. However, this comes at the cost of missed small objects and reduced accuracy at semantic boundaries. To address this problem, we propose a new content-adaptive downsampling technique that learns to favor sampling locations near semantic boundaries of target classes. Cost-performance analysis shows that our method consistently outperforms the uniform sampling improving balance between accuracy and computational efficiency. Our adaptive sampling gives segmentation with better quality of boundaries and more reliable support for smaller-size objects.