 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Gaussian Splatting as Markov Chain Monte Carlo
Apr 15, 2024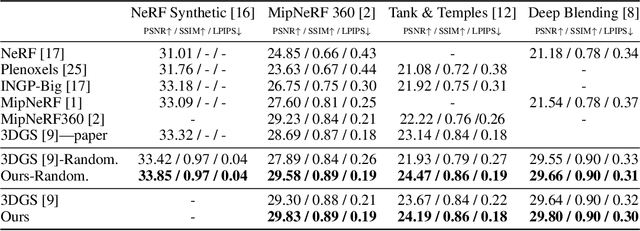


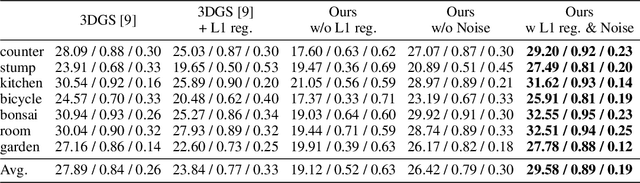
While 3D Gaussian Splatting has recently become popular for neural rendering, current methods rely on carefully engineered cloning and splitting strategies for placing Gaussians, which does not always generalize and may lead to poor-quality renderings. In addition, for real-world scenes, they rely on a good initial point cloud to perform well. In this work, we rethink 3D Gaussians as random samples drawn from an underlying probability distribution describing the physical representation of the scene -- in other words, Markov Chain Monte Carlo (MCMC) samples. Under this view, we show that the 3D Gaussian updates are strikingly similar to a Stochastic Langevin Gradient Descent (SGLD) update. As with MCMC, samples are nothing but past visit locations, adding new Gaussians under our framework can simply be realized without heuristics as placing Gaussians at existing Gaussian locations. To encourage using fewer Gaussians for efficiency, we introduce an L1-regularizer on the Gaussians. On various standard evaluation scenes, we show that our method provides improved rendering quality, easy control over the number of Gaussians, and robustness to initialization.
Unsupervised Keypoints from Pretrained Diffusion Models
Dec 05, 2023



Unsupervised learning of keypoints and landmarks has seen significant progress with the help of modern neural network architectures, but performance is yet to match the supervised counterpart, making their practicability questionable. We leverage the emergent knowledge within text-to-image diffusion models, towards more robust unsupervised keypoints. Our core idea is to find text embeddings that would cause the generative model to consistently attend to compact regions in images (i.e. keypoints). To do so, we simply optimize the text embedding such that the cross-attention maps within the denoising network are localized as Gaussians with small standard deviations. We validate our performance on multiple datasets: the CelebA, CUB-200-2011, Tai-Chi-HD, DeepFashion, and Human3.6m datasets. We achieve significantly improved accuracy, sometimes even outperforming supervised ones, particularly for data that is non-aligned and less curated. Our code is publicly available and can be found through our project page: https://ubc-vision.github.io/StableKeypoints/
Accelerating Neural Field Training via Soft Mining
Nov 29, 2023We present an approach to accelerate Neural Field training by efficiently selecting sampling locations. While Neural Fields have recently become popular, it is often trained by uniformly sampling the training domain, or through handcrafted heuristics. We show that improved convergence and final training quality can be achieved by a soft mining technique based on importance sampling: rather than either considering or ignoring a pixel completely, we weigh the corresponding loss by a scalar. To implement our idea we use Langevin Monte-Carlo sampling. We show that by doing so, regions with higher error are being selected more frequently, leading to more than 2x improvement in convergence speed. The code and related resources for this study are publicly available at https://ubc-vision.github.io/nf-soft-mining/.
Unsupervised Semantic Correspondence Using Stable Diffusion
May 24, 2023Text-to-image diffusion models are now capable of generating images that are often indistinguishable from real images. To generate such images, these models must understand the semantics of the objects they are asked to generate. In this work we show that, without any training, one can leverage this semantic knowledge within diffusion models to find semantic correspondences -- locations in multiple images that have the same semantic meaning. Specifically, given an image, we optimize the prompt embeddings of these models for maximum attention on the regions of interest. These optimized embeddings capture semantic information about the location, which can then be transferred to another image. By doing so we obtain results on par with the strongly supervised state of the art on the PF-Willow dataset and significantly outperform (20.9% relative for the SPair-71k dataset) any existing weakly or unsupervised method on PF-Willow, CUB-200 and SPair-71k datasets.
RePose: Learning Deep Kinematic Priors for Fast Human Pose Estimation
Feb 10, 2020
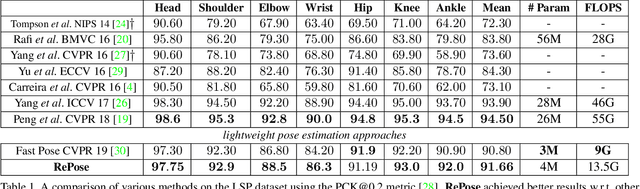
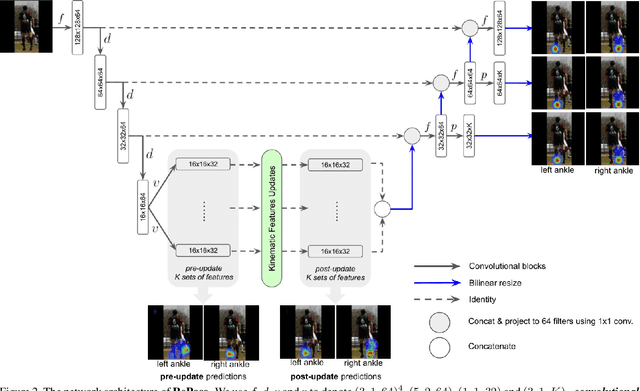
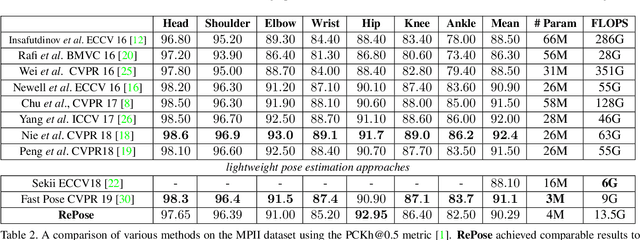
We propose a novel efficient and lightweight model for human pose estimation from a single image. Our model is designed to achieve competitive results at a fraction of the number of parameters and computational cost of various state-of-the-art methods. To this end, we explicitly incorporate part-based structural and geometric priors in a hierarchical prediction framework. At the coarsest resolution, and in a manner similar to classical part-based approaches, we leverage the kinematic structure of the human body to propagate convolutional feature updates between the keypoints or body parts. Unlike classical approaches, we adopt end-to-end training to learn this geometric prior through feature updates from data. We then propagate the feature representation at the coarsest resolution up the hierarchy to refine the predicted pose in a coarse-to-fine fashion. The final network effectively models the geometric prior and intuition within a lightweight deep neural network, yielding state-of-the-art results for a model of this size on two standard datasets, Leeds Sports Pose and MPII Human Pose.
Efficient optimization for Hierarchically-structured Interacting Segments (HINTS)
Mar 30, 2017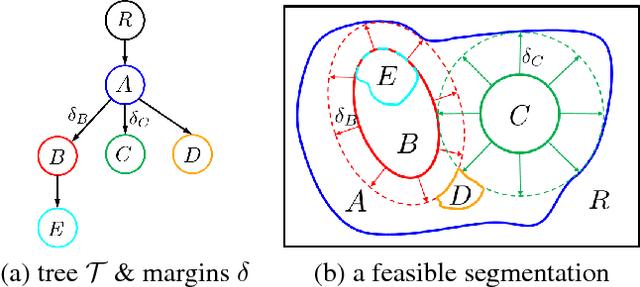

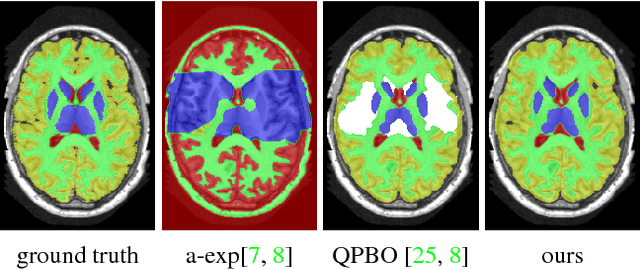

We propose an effective optimization algorithm for a general hierarchical segmentation model with geometric interactions between segments. Any given tree can specify a partial order over object labels defining a hierarchy. It is well-established that segment interactions, such as inclusion/exclusion and margin constraints, make the model significantly more discriminant. However, existing optimization methods do not allow full use of such models. Generic -expansion results in weak local minima, while common binary multi-layered formulations lead to non-submodularity, complex high-order potentials, or polar domain unwrapping and shape biases. In practice, applying these methods to arbitrary trees does not work except for simple cases. Our main contribution is an optimization method for the Hierarchically-structured Interacting Segments (HINTS) model with arbitrary trees. Our Path-Moves algorithm is based on multi-label MRF formulation and can be seen as a combination of well-known a-expansion and Ishikawa techniques. We show state-of-the-art biomedical segmentation for many diverse examples of complex trees.
A-expansion for multiple "hedgehog" shapes
Feb 02, 2016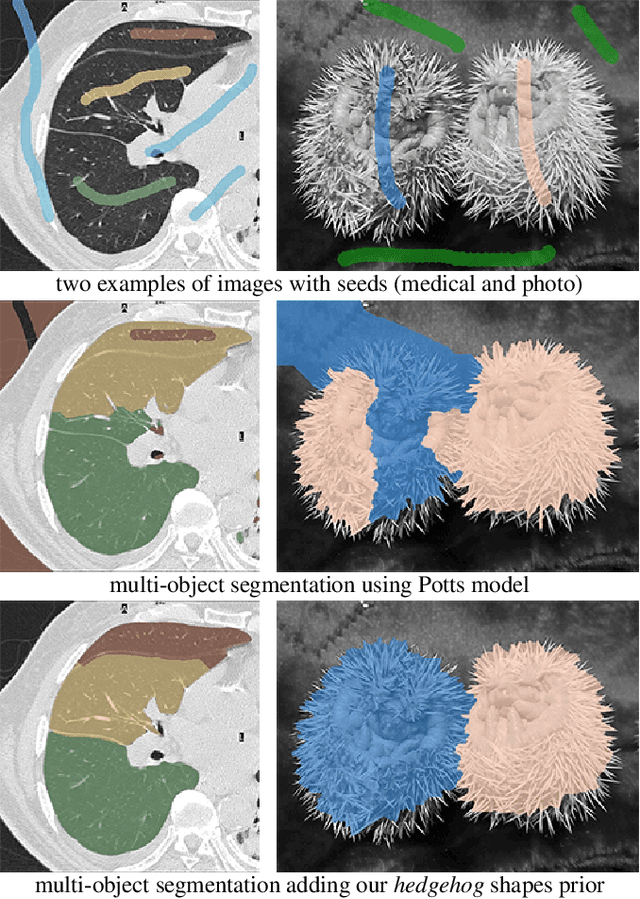
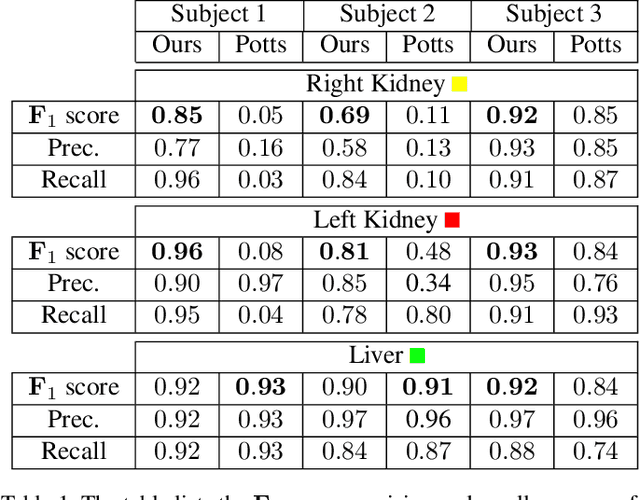
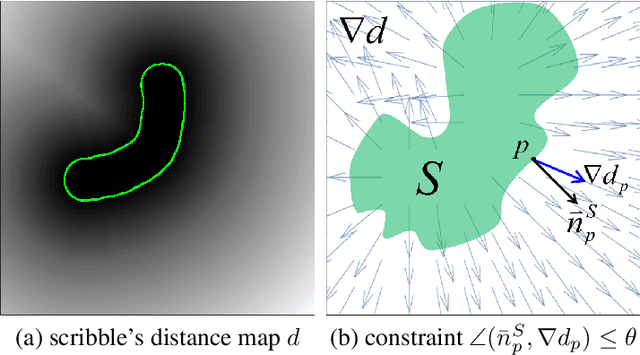
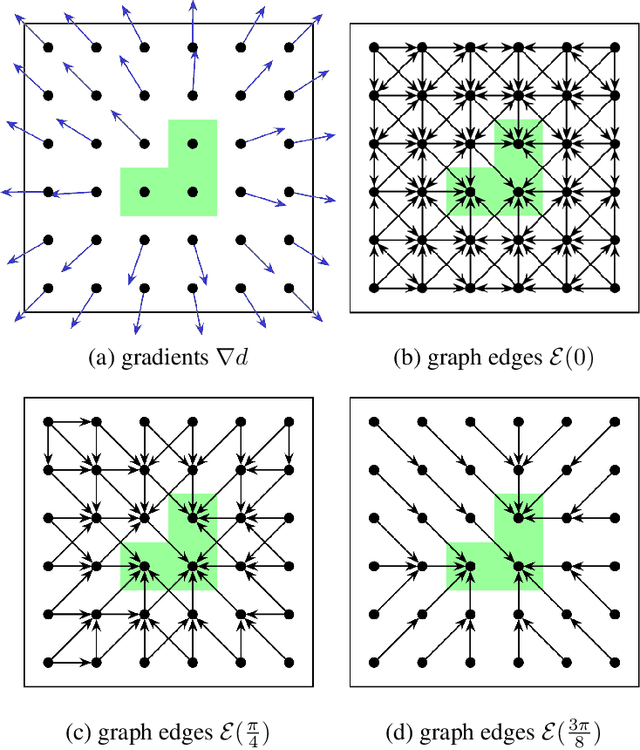
Overlapping colors and cluttered or weak edges are common segmentation problems requiring additional regularization. For example, star-convexity is popular for interactive single object segmentation due to simplicity and amenability to exact graph cut optimization. This paper proposes an approach to multiobject segmentation where objects could be restricted to separate "hedgehog" shapes. We show that a-expansion moves are submodular for our multi-shape constraints. Each "hedgehog" shape has its surface normals constrained by some vector field, e.g. gradients of a distance transform for user scribbles. Tight constraint give an extreme case of a shape prior enforcing skeleton consistency with the scribbles. Wider cones of allowed normals gives more relaxed hedgehog shapes. A single click and +/-90 degrees normal orientation constraints reduce our hedgehog prior to star-convexity. If all hedgehogs come from single clicks then our approach defines multi-star prior. Our general method has significantly more applications than standard one-star segmentation. For example, in medical data we can separate multiple non-star organs with similar appearances and weak or noisy edges.
Volumetric Bias in Segmentation and Reconstruction: Secrets and Solutions
May 01, 2015
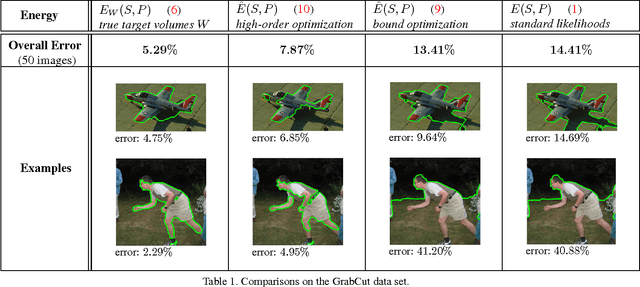
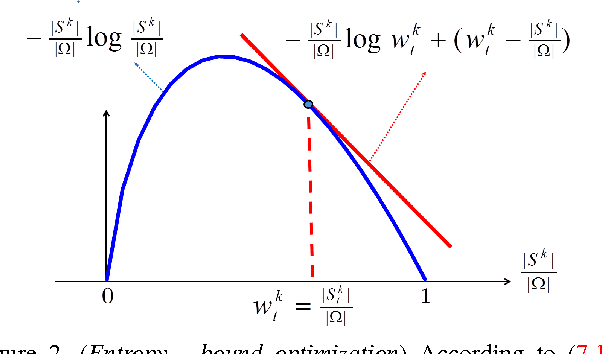
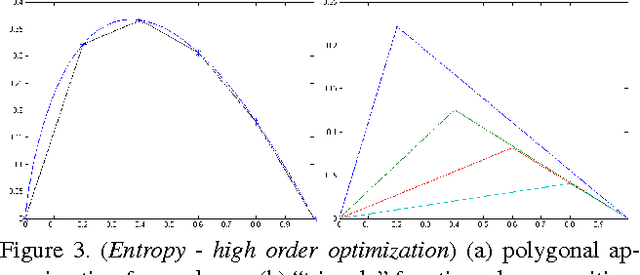
Many standard optimization methods for segmentation and reconstruction compute ML model estimates for appearance or geometry of segments, e.g. Zhu-Yuille 1996, Torr 1998, Chan-Vese 2001, GrabCut 2004, Delong et al. 2012. We observe that the standard likelihood term in these formulations corresponds to a generalized probabilistic K-means energy. In learning it is well known that this energy has a strong bias to clusters of equal size, which can be expressed as a penalty for KL divergence from a uniform distribution of cardinalities. However, this volumetric bias has been mostly ignored in computer vision. We demonstrate significant artifacts in standard segmentation and reconstruction methods due to this bias. Moreover, we propose binary and multi-label optimization techniques that either (a) remove this bias or (b) replace it by a KL divergence term for any given target volume distribution. Our general ideas apply to many continuous or discrete energy formulations in segmentation, stereo, and other reconstruction problems.
Joint optimization of fitting & matching in multi-view reconstruction
Apr 09, 2014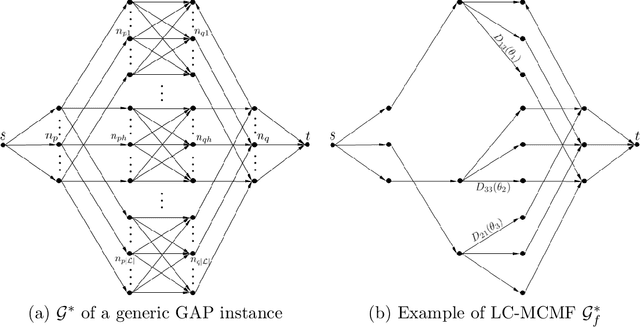
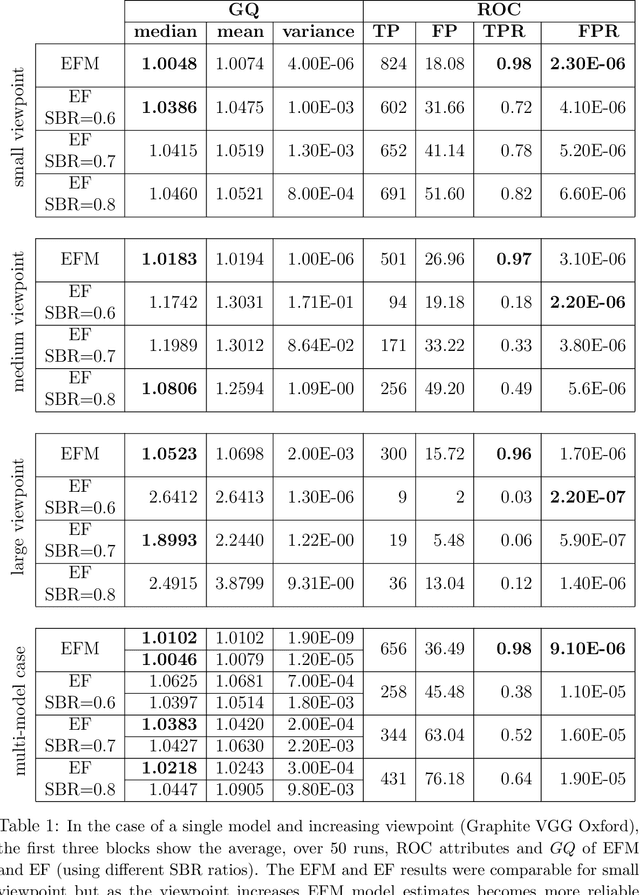
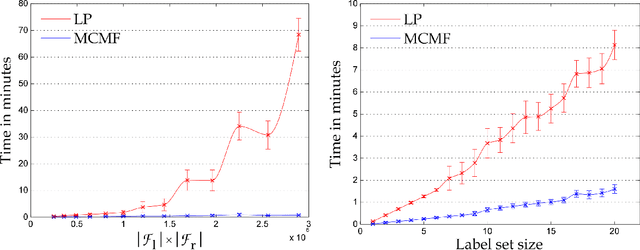
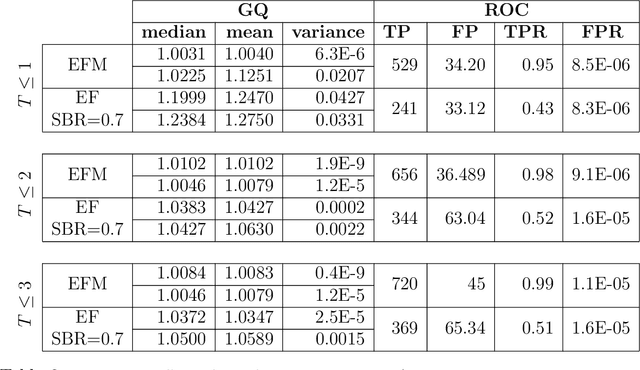
Many standard approaches for geometric model fitting are based on pre-matched image features. Typically, such pre-matching uses only feature appearances (e.g. SIFT) and a large number of non-unique features must be discarded in order to control the false positive rate. In contrast, we solve feature matching and multi-model fitting problems in a joint optimization framework. This paper proposes several fit-&-match energy formulations based on a generalization of the assignment problem. We developed an efficient solver based on min-cost-max-flow algorithm that finds near optimal solutions. Our approach significantly increases the number of detected matches. In practice, energy-based joint fitting & matching allows to increase the distance between view-points previously restricted by robustness of local SIFT-matching and to improve the model fitting accuracy when compared to state-of-the-art multi-model fitting techniques.