 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOcclusion-Ordered Semantic Instance Segmentation
Apr 18, 2025



Standard semantic instance segmentation provides useful, but inherently 2D information from a single image. To enable 3D analysis, one usually integrates absolute monocular depth estimation with instance segmentation. However, monocular depth is a difficult task. Instead, we leverage a simpler single-image task, occlusion-based relative depth ordering, providing coarser but useful 3D information. We show that relative depth ordering works more reliably from occlusions than from absolute depth. We propose to solve the joint task of relative depth ordering and segmentation of instances based on occlusions. We call this task Occlusion-Ordered Semantic Instance Segmentation (OOSIS). We develop an approach to OOSIS that extracts instances and their occlusion order simultaneously from oriented occlusion boundaries and semantic segmentation. Unlike popular detect-and-segment framework for instance segmentation, combining occlusion ordering with instance segmentation allows a simple and clean formulation of OOSIS as a labeling problem. As a part of our solution for OOSIS, we develop a novel oriented occlusion boundaries approach that significantly outperforms prior work. We also develop a new joint OOSIS metric based both on instance mask accuracy and correctness of their occlusion order. We achieve better performance than strong baselines on KINS and COCOA datasets.
Simulating CRF with CNN for CNN
May 06, 2019


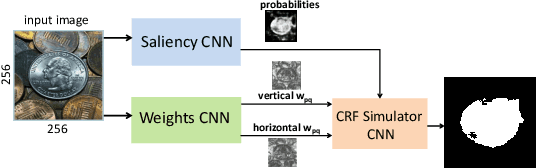
Combining CNN with CRF for modeling dependencies between pixel labels is a popular research direction. This task is far from trivial, especially if end-to-end training is desired. In this paper, we propose a novel simple approach to CNN+CRF combination. In particular, we propose to simulate a CRF regularizer with a trainable module that has standard CNN architecture. We call this module a CRF Simulator. We can automatically generate an unlimited amount of ground truth for training such CRF Simulator without any user interaction, provided we have an efficient algorithm for optimization of the actual CRF regularizer. After our CRF Simulator is trained, it can be directly incorporated as part of any larger CNN architecture, enabling a seamless end-to-end training. In particular, the other modules can learn parameters that are more attuned to the performance of the CRF Simulator module. We demonstrate the effectiveness of our approach on the task of salient object segmentation regularized with the standard binary CRF energy. In contrast to previous work we do not need to develop and implement the complex mechanics of optimizing a specific CRF as part of CNN. In fact, our approach can be easily extended to other CRF energies, including multi-label. To the best of our knowledge we are the first to study the question of whether the output of CNNs can have regularization properties of CRFs.
Location Augmentation for CNN
Oct 14, 2018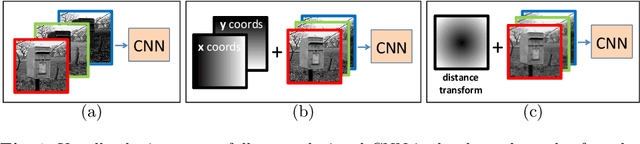
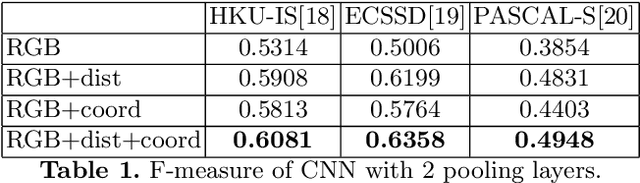
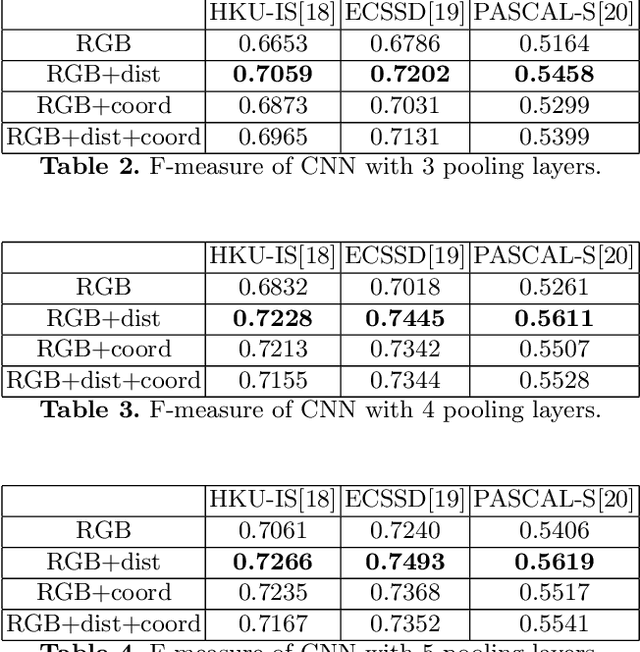
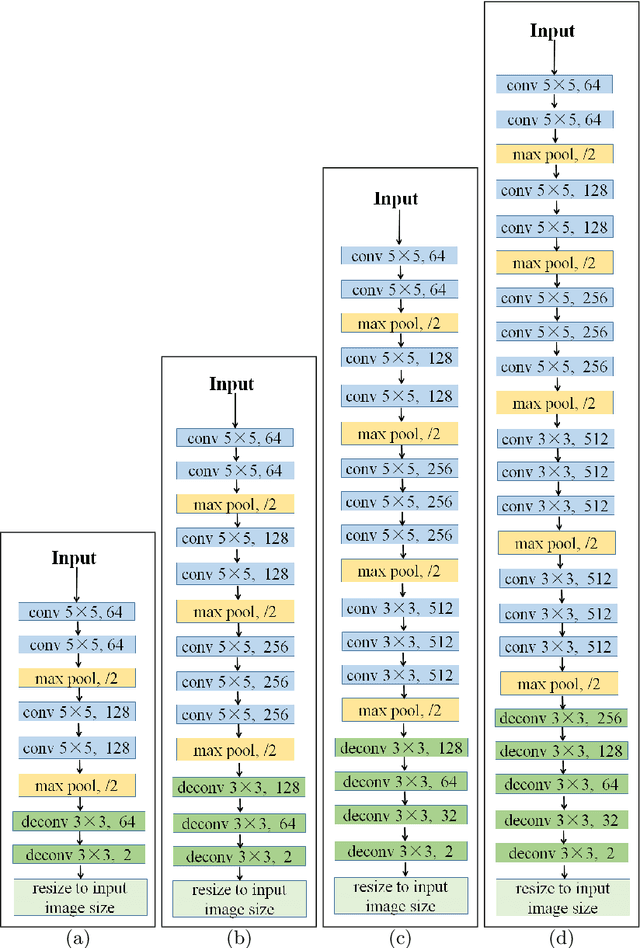
CNNs have made a tremendous impact on the field of computer vision in the last several years. The main component of any CNN architecture is the convolution operation, which is translation invariant by design. However, location in itself can be an important cue. For example, a salient object is more likely to be closer to the center of the image, the sky in the top part of an image, etc. To include the location cue for feature learning, we propose to augment the color image, the usual input to CNNs, with one or more channels that carry location information. We test two approaches for adding location information. In the first approach, we incorporate location directly, by including the row and column indexes as two additional channels to the input image. In the second approach, we add location less directly by adding distance transform from the center pixel as an additional channel to the input image. We perform experiments with both direct and indirect ways to encode location. We show the advantage of augmenting the standard color input with location related channels on the tasks of salient object segmentation, semantic segmentation, and scene parsing.
Efficient Graph Cut Optimization for Full CRFs with Quantized Edges
Sep 13, 2018

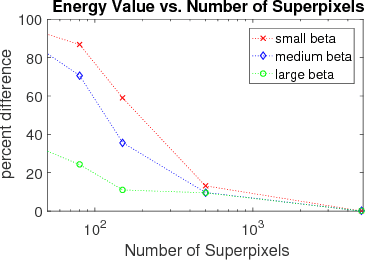

Fully connected pairwise Conditional Random Fields (Full-CRF) with Gaussian edge weights can achieve superior results compared to sparsely connected CRFs. However, traditional methods for Full-CRFs are too expensive. Previous work develops efficient approximate optimization based on mean field inference, which is a local optimization method and can be far from the optimum. We propose efficient and effective optimization based on graph cuts for Full-CRFs with quantized edge weights. To quantize edge weights, we partition the image into superpixels and assume that the weight of an edge between any two pixels depends only on the superpixels these pixels belong to. Our quantized edge CRF is an approximation to the Gaussian edge CRF, and gets closer to it as superpixel size decreases. Being an approximation, our model offers an intuition about the regularization properties of the Guassian edge Full-CRF. For efficient inference, we first consider the two-label case and develop an approximate method based on transforming the original problem into a smaller domain. Then we handle multi-label CRF by showing how to implement expansion moves. In both binary and multi-label cases, our solutions have significantly lower energy compared to that of mean field inference. We also show the effectiveness of our approach on semantic segmentation task.
Efficient optimization for Hierarchically-structured Interacting Segments (HINTS)
Mar 30, 2017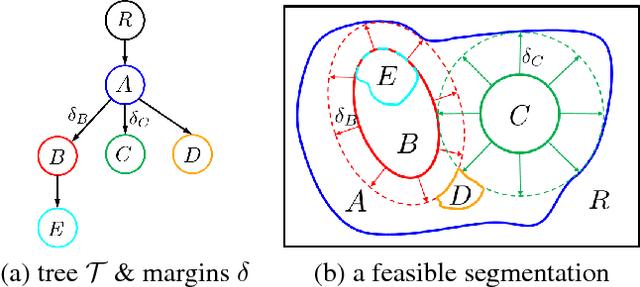

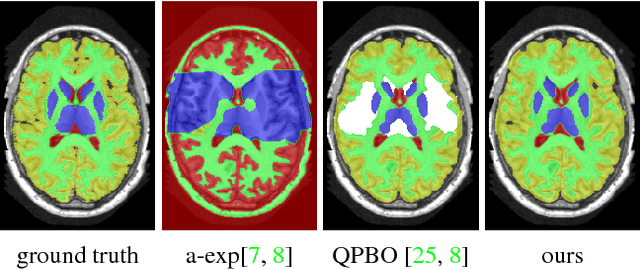

We propose an effective optimization algorithm for a general hierarchical segmentation model with geometric interactions between segments. Any given tree can specify a partial order over object labels defining a hierarchy. It is well-established that segment interactions, such as inclusion/exclusion and margin constraints, make the model significantly more discriminant. However, existing optimization methods do not allow full use of such models. Generic -expansion results in weak local minima, while common binary multi-layered formulations lead to non-submodularity, complex high-order potentials, or polar domain unwrapping and shape biases. In practice, applying these methods to arbitrary trees does not work except for simple cases. Our main contribution is an optimization method for the Hierarchically-structured Interacting Segments (HINTS) model with arbitrary trees. Our Path-Moves algorithm is based on multi-label MRF formulation and can be seen as a combination of well-known a-expansion and Ishikawa techniques. We show state-of-the-art biomedical segmentation for many diverse examples of complex trees.
A-expansion for multiple "hedgehog" shapes
Feb 02, 2016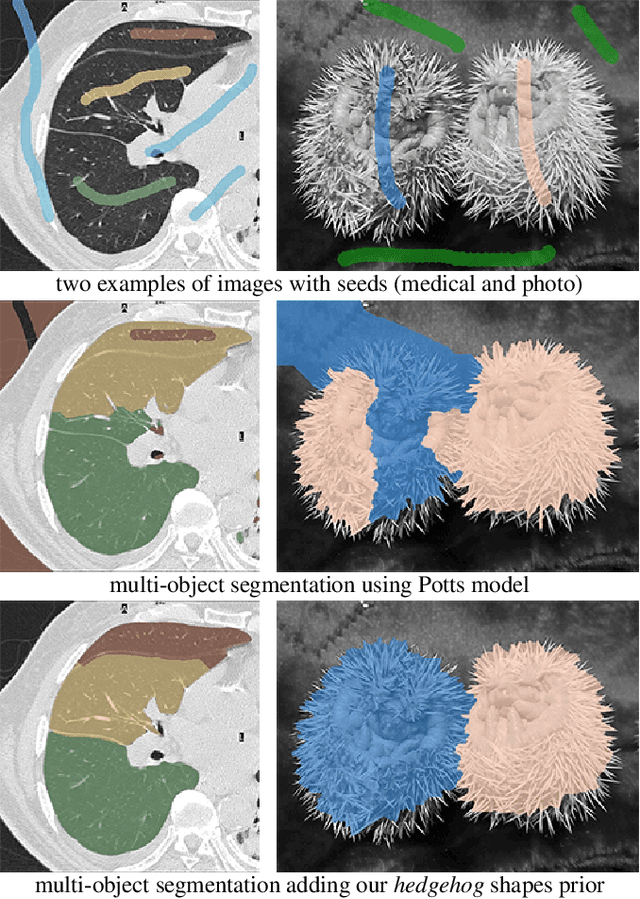
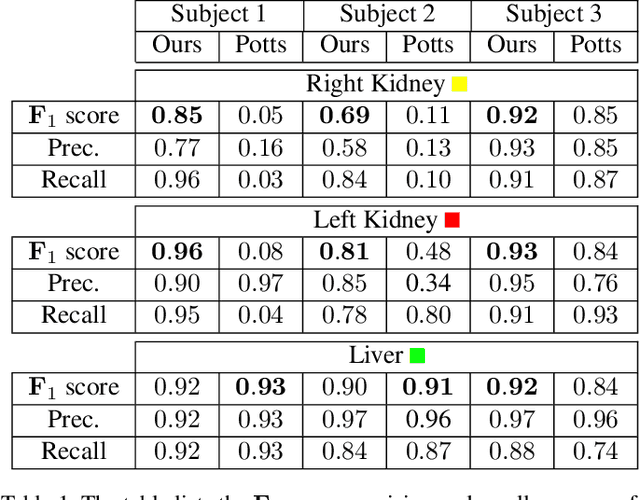
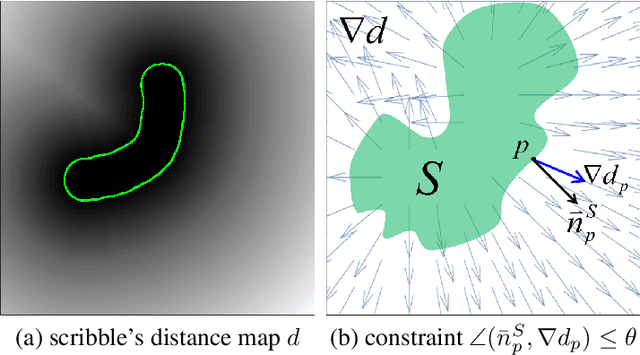
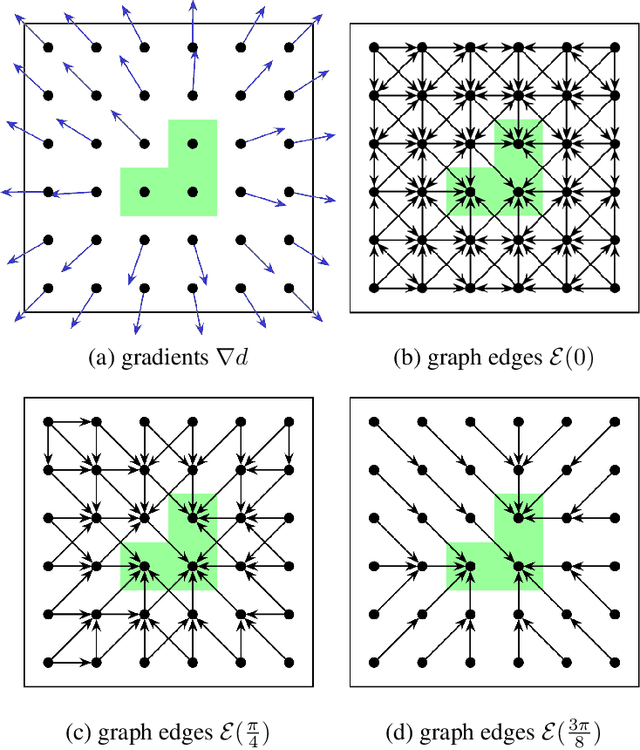
Overlapping colors and cluttered or weak edges are common segmentation problems requiring additional regularization. For example, star-convexity is popular for interactive single object segmentation due to simplicity and amenability to exact graph cut optimization. This paper proposes an approach to multiobject segmentation where objects could be restricted to separate "hedgehog" shapes. We show that a-expansion moves are submodular for our multi-shape constraints. Each "hedgehog" shape has its surface normals constrained by some vector field, e.g. gradients of a distance transform for user scribbles. Tight constraint give an extreme case of a shape prior enforcing skeleton consistency with the scribbles. Wider cones of allowed normals gives more relaxed hedgehog shapes. A single click and +/-90 degrees normal orientation constraints reduce our hedgehog prior to star-convexity. If all hedgehogs come from single clicks then our approach defines multi-star prior. Our general method has significantly more applications than standard one-star segmentation. For example, in medical data we can separate multiple non-star organs with similar appearances and weak or noisy edges.
Efficient Regularization of Squared Curvature
Apr 15, 2014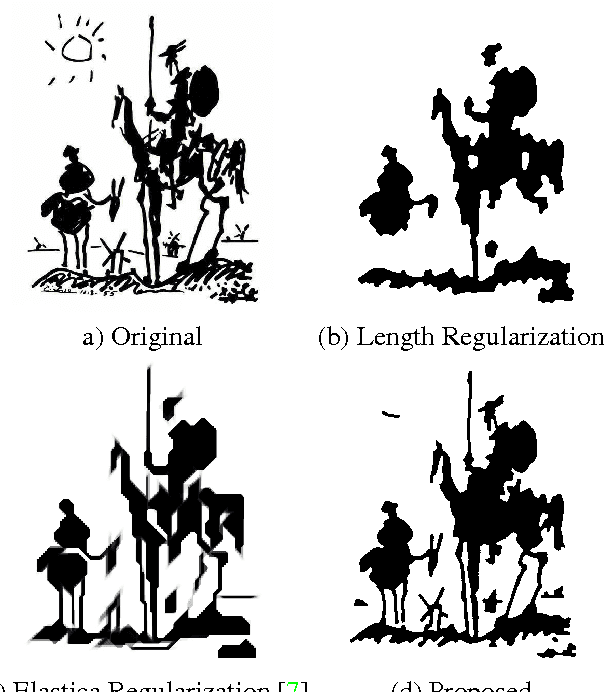

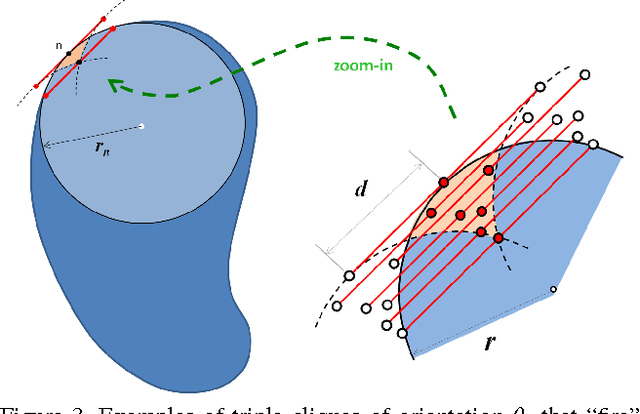
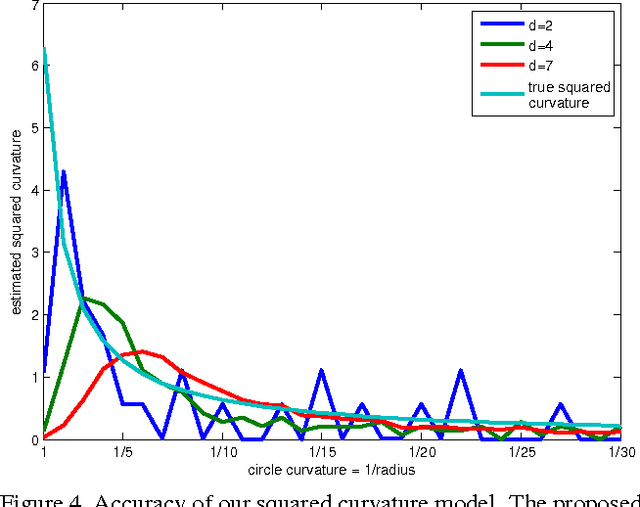
Curvature has received increased attention as an important alternative to length based regularization in computer vision. In contrast to length, it preserves elongated structures and fine details. Existing approaches are either inefficient, or have low angular resolution and yield results with strong block artifacts. We derive a new model for computing squared curvature based on integral geometry. The model counts responses of straight line triple cliques. The corresponding energy decomposes into submodular and supermodular pairwise potentials. We show that this energy can be efficiently minimized even for high angular resolutions using the trust region framework. Our results confirm that we obtain accurate and visually pleasing solutions without strong artifacts at reasonable run times.
Submodularization for Quadratic Pseudo-Boolean Optimization
Apr 15, 2014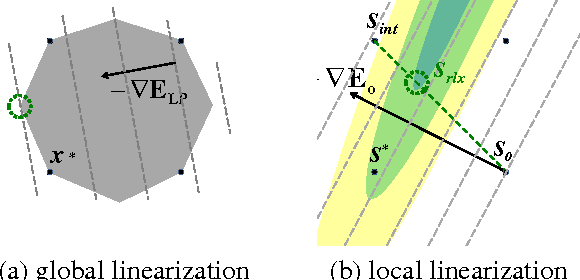
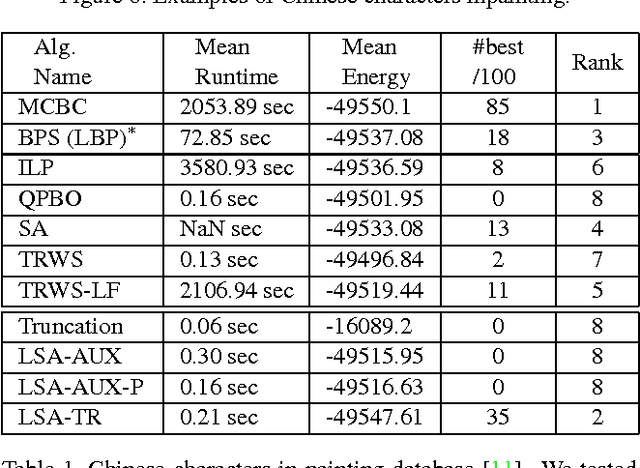
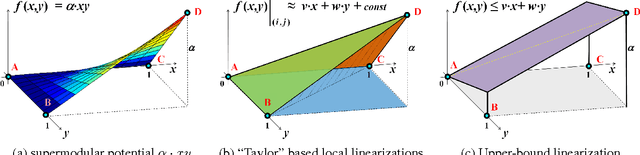

Many computer vision problems require optimization of binary non-submodular energies. We propose a general optimization framework based on local submodular approximations (LSA). Unlike standard LP relaxation methods that linearize the whole energy globally, our approach iteratively approximates the energies locally. On the other hand, unlike standard local optimization methods (e.g. gradient descent or projection techniques) we use non-linear submodular approximations and optimize them without leaving the domain of integer solutions. We discuss two specific LSA algorithms based on "trust region" and "auxiliary function" principles, LSA-TR and LSA-AUX. These methods obtain state-of-the-art results on a wide range of applications outperforming many standard techniques such as LBP, QPBO, and TRWS. While our paper is focused on pairwise energies, our ideas extend to higher-order problems. The code is available online (http://vision.csd.uwo.ca/code/).