 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocation Augmentation for CNN
Paper and Code
Oct 14, 2018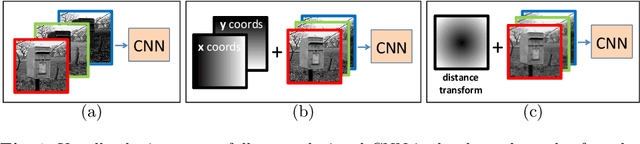
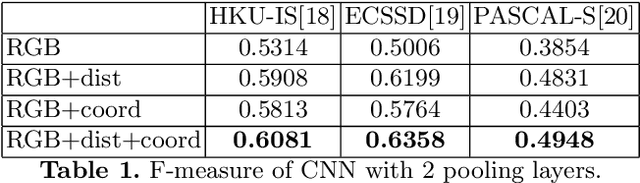
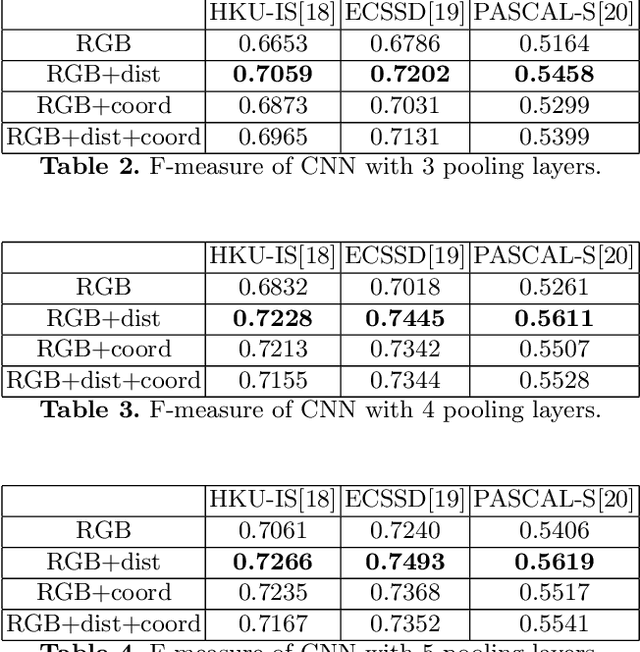
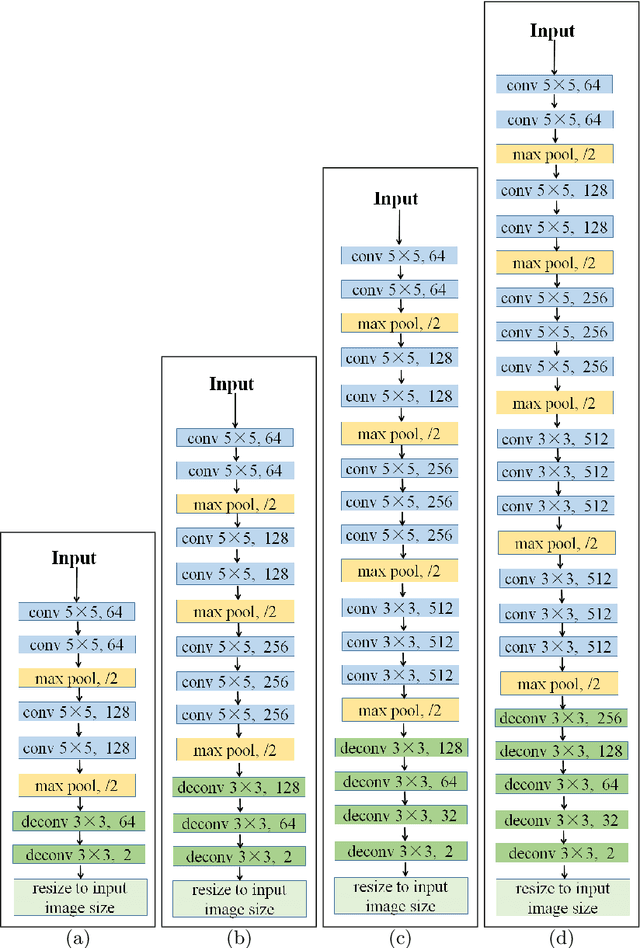
CNNs have made a tremendous impact on the field of computer vision in the last several years. The main component of any CNN architecture is the convolution operation, which is translation invariant by design. However, location in itself can be an important cue. For example, a salient object is more likely to be closer to the center of the image, the sky in the top part of an image, etc. To include the location cue for feature learning, we propose to augment the color image, the usual input to CNNs, with one or more channels that carry location information. We test two approaches for adding location information. In the first approach, we incorporate location directly, by including the row and column indexes as two additional channels to the input image. In the second approach, we add location less directly by adding distance transform from the center pixel as an additional channel to the input image. We perform experiments with both direct and indirect ways to encode location. We show the advantage of augmenting the standard color input with location related channels on the tasks of salient object segmentation, semantic segmentation, and scene parsing.