 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAMOS-OCTA: Vessel-Aware Multi-Axis Orthogonal Supervision for Inpainting Motion-Corrupted OCT Angiography Volumes
Feb 01, 2026Handheld Optical Coherence Tomography Angiography (OCTA) enables noninvasive retinal imaging in uncooperative or pediatric subjects, but is highly susceptible to motion artifacts that severely degrade volumetric image quality. Sudden motion during 3D acquisition can lead to unsampled retinal regions across entire B-scans (cross-sectional slices), resulting in blank bands in en face projections. We propose VAMOS-OCTA, a deep learning framework for inpainting motion-corrupted B-scans using vessel-aware multi-axis supervision. We employ a 2.5D U-Net architecture that takes a stack of neighboring B-scans as input to reconstruct a corrupted center B-scan, guided by a novel Vessel-Aware Multi-Axis Orthogonal Supervision (VAMOS) loss. This loss combines vessel-weighted intensity reconstruction with axial and lateral projection consistency, encouraging vascular continuity in native B-scans and across orthogonal planes. Unlike prior work that focuses primarily on restoring the en face MIP, VAMOS-OCTA jointly enhances both cross-sectional B-scan sharpness and volumetric projection accuracy, even under severe motion corruptions. We trained our model on both synthetic and real-world corrupted volumes and evaluated its performance using both perceptual quality and pixel-wise accuracy metrics. VAMOS-OCTA consistently outperforms prior methods, producing reconstructions with sharp capillaries, restored vessel continuity, and clean en face projections. These results demonstrate that multi-axis supervision offers a powerful constraint for restoring motion-degraded 3D OCTA data. Our source code is available at https://github.com/MedICL-VU/VAMOS-OCTA.
IntraStyler: Exemplar-based Style Synthesis for Cross-modality Domain Adaptation
Jan 01, 2026Image-level domain alignment is the de facto approach for unsupervised domain adaptation, where unpaired image translation is used to minimize the domain gap. Prior studies mainly focus on the domain shift between the source and target domains, whereas the intra-domain variability remains under-explored. To address the latter, an effective strategy is to diversify the styles of the synthetic target domain data during image translation. However, previous methods typically require intra-domain variations to be pre-specified for style synthesis, which may be impractical. In this paper, we propose an exemplar-based style synthesis method named IntraStyler, which can capture diverse intra-domain styles without any prior knowledge. Specifically, IntraStyler uses an exemplar image to guide the style synthesis such that the output style matches the exemplar style. To extract the style-only features, we introduce a style encoder to learn styles discriminatively based on contrastive learning. We evaluate the proposed method on the largest public dataset for cross-modality domain adaptation, CrossMoDA 2023. Our experiments show the efficacy of our method in controllable style synthesis and the benefits of diverse synthetic data for downstream segmentation. Code is available at https://github.com/han-liu/IntraStyler.
EndoStreamDepth: Temporally Consistent Monocular Depth Estimation for Endoscopic Video Streams
Dec 20, 2025



This work presents EndoStreamDepth, a monocular depth estimation framework for endoscopic video streams. It provides accurate depth maps with sharp anatomical boundaries for each frame, temporally consistent predictions across frames, and real-time throughput. Unlike prior work that uses batched inputs, EndoStreamDepth processes individual frames with a temporal module to propagate inter-frame information. The framework contains three main components: (1) a single-frame depth network with endoscopy-specific transformation to produce accurate depth maps, (2) multi-level Mamba temporal modules that leverage inter-frame information to improve accuracy and stabilize predictions, and (3) a hierarchical design with comprehensive multi-scale supervision, where complementary loss terms jointly improve local boundary sharpness and global geometric consistency. We conduct comprehensive evaluations on two publicly available colonoscopy depth estimation datasets. Compared to state-of-the-art monocular depth estimation methods, EndoStreamDepth substantially improves performance, and it produces depth maps with sharp, anatomically aligned boundaries, which are essential to support downstream tasks such as automation for robotic surgery. The code is publicly available at https://github.com/MedICL-VU/EndoStreamDepth
Endo-SemiS: Towards Robust Semi-Supervised Image Segmentation for Endoscopic Video
Dec 18, 2025



In this paper, we present Endo-SemiS, a semi-supervised segmentation framework for providing reliable segmentation of endoscopic video frames with limited annotation. EndoSemiS uses 4 strategies to improve performance by effectively utilizing all available data, particularly unlabeled data: (1) Cross-supervision between two individual networks that supervise each other; (2) Uncertainty-guided pseudo-labels from unlabeled data, which are generated by selecting high-confidence regions to improve their quality; (3) Joint pseudolabel supervision, which aggregates reliable pixels from the pseudo-labels of both networks to provide accurate supervision for unlabeled data; and (4) Mutual learning, where both networks learn from each other at the feature and image levels, reducing variance and guiding them toward a consistent solution. Additionally, a separate corrective network that utilizes spatiotemporal information from endoscopy video to improve segmentation performance. Endo-SemiS is evaluated on two clinical applications: kidney stone laser lithotomy from ureteroscopy and polyp screening from colonoscopy. Compared to state-of-the-art segmentation methods, Endo-SemiS substantially achieves superior results on both datasets with limited labeled data. The code is publicly available at https://github.com/MedICL-VU/Endo-SemiS
ProbeMDE: Uncertainty-Guided Active Proprioception for Monocular Depth Estimation in Surgical Robotics
Dec 17, 2025Monocular depth estimation (MDE) provides a useful tool for robotic perception, but its predictions are often uncertain and inaccurate in challenging environments such as surgical scenes where textureless surfaces, specular reflections, and occlusions are common. To address this, we propose ProbeMDE, a cost-aware active sensing framework that combines RGB images with sparse proprioceptive measurements for MDE. Our approach utilizes an ensemble of MDE models to predict dense depth maps conditioned on both RGB images and on a sparse set of known depth measurements obtained via proprioception, where the robot has touched the environment in a known configuration. We quantify predictive uncertainty via the ensemble's variance and measure the gradient of the uncertainty with respect to candidate measurement locations. To prevent mode collapse while selecting maximally informative locations to propriocept (touch), we leverage Stein Variational Gradient Descent (SVGD) over this gradient map. We validate our method in both simulated and physical experiments on central airway obstruction surgical phantoms. Our results demonstrate that our approach outperforms baseline methods across standard depth estimation metrics, achieving higher accuracy while minimizing the number of required proprioceptive measurements. Project page: https://brittonjordan.github.io/probe_mde/
DEMIST: \underline{DE}coupled \underline{M}ulti-stream latent d\underline{I}ffusion for Quantitative Myelin Map \underline{S}yn\underline{T}hesis
Nov 16, 2025Quantitative magnetization transfer (qMT) imaging provides myelin-sensitive biomarkers, such as the pool size ratio (PSR), which is valuable for multiple sclerosis (MS) assessment. However, qMT requires specialized 20-30 minute scans. We propose DEMIST to synthesize PSR maps from standard T1w and FLAIR images using a 3D latent diffusion model with three complementary conditioning mechanisms. Our approach has two stages: first, we train separate autoencoders for PSR and anatomical images to learn aligned latent representations. Second, we train a conditional diffusion model in this latent space on top of a frozen diffusion foundation backbone. Conditioning is decoupled into: (i) \textbf{semantic} tokens via cross-attention, (ii) \textbf{spatial} per-scale residual hints via a 3D ControlNet branch, and (iii) \textbf{adaptive} LoRA-modulated attention. We include edge-aware loss terms to preserve lesion boundaries and alignment losses to maintain quantitative consistency, while keeping the number of trainable parameters low and retaining the inductive bias of the pretrained model. We evaluate on 163 scans from 99 subjects using 5-fold cross-validation. Our method outperforms VAE, GAN and diffusion baselines on multiple metrics, producing sharper boundaries and better quantitative agreement with ground truth. Our code is publicly available at https://github.com/MedICL-VU/MS-Synthesis-3DcLDM.
A Supervised Autonomous Resection and Retraction Framework for Transurethral Enucleation of the Prostatic Median Lobe
Nov 11, 2025Concentric tube robots (CTRs) offer dexterous motion at millimeter scales, enabling minimally invasive procedures through natural orifices. This work presents a coordinated model-based resection planner and learning-based retraction network that work together to enable semi-autonomous tissue resection using a dual-arm transurethral concentric tube robot (the Virtuoso). The resection planner operates directly on segmented CT volumes of prostate phantoms, automatically generating tool trajectories for a three-phase median lobe resection workflow: left/median trough resection, right/median trough resection, and median blunt dissection. The retraction network, PushCVAE, trained on surgeon demonstrations, generates retractions according to the procedural phase. The procedure is executed under Level-3 (supervised) autonomy on a prostate phantom composed of hydrogel materials that replicate the mechanical and cutting properties of tissue. As a feasibility study, we demonstrate that our combined autonomous system achieves a 97.1% resection of the targeted volume of the median lobe. Our study establishes a foundation for image-guided autonomy in transurethral robotic surgery and represents a first step toward fully automated minimally-invasive prostate enucleation.
crossMoDA Challenge: Evolution of Cross-Modality Domain Adaptation Techniques for Vestibular Schwannoma and Cochlea Segmentation from 2021 to 2023
Jun 13, 2025The cross-Modality Domain Adaptation (crossMoDA) challenge series, initiated in 2021 in conjunction with the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), focuses on unsupervised cross-modality segmentation, learning from contrast-enhanced T1 (ceT1) and transferring to T2 MRI. The task is an extreme example of domain shift chosen to serve as a meaningful and illustrative benchmark. From a clinical application perspective, it aims to automate Vestibular Schwannoma (VS) and cochlea segmentation on T2 scans for more cost-effective VS management. Over time, the challenge objectives have evolved to enhance its clinical relevance. The challenge evolved from using single-institutional data and basic segmentation in 2021 to incorporating multi-institutional data and Koos grading in 2022, and by 2023, it included heterogeneous routine data and sub-segmentation of intra- and extra-meatal tumour components. In this work, we report the findings of the 2022 and 2023 editions and perform a retrospective analysis of the challenge progression over the years. The observations from the successive challenge contributions indicate that the number of outliers decreases with an expanding dataset. This is notable since the diversity of scanning protocols of the datasets concurrently increased. The winning approach of the 2023 edition reduced the number of outliers on the 2021 and 2022 testing data, demonstrating how increased data heterogeneity can enhance segmentation performance even on homogeneous data. However, the cochlea Dice score declined in 2023, likely due to the added complexity from tumour sub-annotations affecting overall segmentation performance. While progress is still needed for clinically acceptable VS segmentation, the plateauing performance suggests that a more challenging cross-modal task may better serve future benchmarking.
From Monocular Vision to Autonomous Action: Guiding Tumor Resection via 3D Reconstruction
Mar 20, 2025Surgical automation requires precise guidance and understanding of the scene. Current methods in the literature rely on bulky depth cameras to create maps of the anatomy, however this does not translate well to space-limited clinical applications. Monocular cameras are small and allow minimally invasive surgeries in tight spaces but additional processing is required to generate 3D scene understanding. We propose a 3D mapping pipeline that uses only RGB images to create segmented point clouds of the target anatomy. To ensure the most precise reconstruction, we compare different structure from motion algorithms' performance on mapping the central airway obstructions, and test the pipeline on a downstream task of tumor resection. In several metrics, including post-procedure tissue model evaluation, our pipeline performs comparably to RGB-D cameras and, in some cases, even surpasses their performance. These promising results demonstrate that automation guidance can be achieved in minimally invasive procedures with monocular cameras. This study is a step toward the complete autonomy of surgical robots.
SynStitch: a Self-Supervised Learning Network for Ultrasound Image Stitching Using Synthetic Training Pairs and Indirect Supervision
Nov 11, 2024

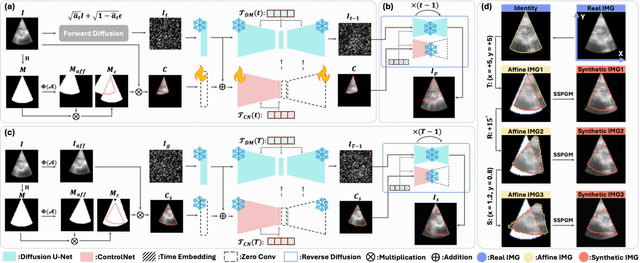

Ultrasound (US) image stitching can expand the field-of-view (FOV) by combining multiple US images from varied probe positions. However, registering US images with only partially overlapping anatomical contents is a challenging task. In this work, we introduce SynStitch, a self-supervised framework designed for 2DUS stitching. SynStitch consists of a synthetic stitching pair generation module (SSPGM) and an image stitching module (ISM). SSPGM utilizes a patch-conditioned ControlNet to generate realistic 2DUS stitching pairs with known affine matrix from a single input image. ISM then utilizes this synthetic paired data to learn 2DUS stitching in a supervised manner. Our framework was evaluated against multiple leading methods on a kidney ultrasound dataset, demonstrating superior 2DUS stitching performance through both qualitative and quantitative analyses. The code will be made public upon acceptance of the paper.