 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgiPose: Estimating Surgical Tool Kinematics from Monocular Video for Surgical Robot Learning
Dec 19, 2025Imitation learning (IL) has shown immense promise in enabling autonomous dexterous manipulation, including learning surgical tasks. To fully unlock the potential of IL for surgery, access to clinical datasets is needed, which unfortunately lack the kinematic data required for current IL approaches. A promising source of large-scale surgical demonstrations is monocular surgical videos available online, making monocular pose estimation a crucial step toward enabling large-scale robot learning. Toward this end, we propose SurgiPose, a differentiable rendering based approach to estimate kinematic information from monocular surgical videos, eliminating the need for direct access to ground truth kinematics. Our method infers tool trajectories and joint angles by optimizing tool pose parameters to minimize the discrepancy between rendered and real images. To evaluate the effectiveness of our approach, we conduct experiments on two robotic surgical tasks: tissue lifting and needle pickup, using the da Vinci Research Kit Si (dVRK Si). We train imitation learning policies with both ground truth measured kinematics and estimated kinematics from video and compare their performance. Our results show that policies trained on estimated kinematics achieve comparable success rates to those trained on ground truth data, demonstrating the feasibility of using monocular video based kinematic estimation for surgical robot learning. By enabling kinematic estimation from monocular surgical videos, our work lays the foundation for large scale learning of autonomous surgical policies from online surgical data.
* 8 pages, 6 figures, 2 tables
SRT-H: A Hierarchical Framework for Autonomous Surgery via Language Conditioned Imitation Learning
May 15, 2025Research on autonomous robotic surgery has largely focused on simple task automation in controlled environments. However, real-world surgical applications require dexterous manipulation over extended time scales while demanding generalization across diverse variations in human tissue. These challenges remain difficult to address using existing logic-based or conventional end-to-end learning strategies. To bridge this gap, we propose a hierarchical framework for dexterous, long-horizon surgical tasks. Our method employs a high-level policy for task planning and a low-level policy for generating task-space controls for the surgical robot. The high-level planner plans tasks using language, producing task-specific or corrective instructions that guide the robot at a coarse level. Leveraging language as a planning modality offers an intuitive and generalizable interface, mirroring how experienced surgeons instruct traineers during procedures. We validate our framework in ex-vivo experiments on a complex minimally invasive procedure, cholecystectomy, and conduct ablative studies to assess key design choices. Our approach achieves a 100% success rate across n=8 different ex-vivo gallbladders, operating fully autonomously without human intervention. The hierarchical approach greatly improves the policy's ability to recover from suboptimal states that are inevitable in the highly dynamic environment of realistic surgical applications. This work represents the first demonstration of step-level autonomy, marking a critical milestone toward autonomous surgical systems for clinical studies. By advancing generalizable autonomy in surgical robotics, our approach brings the field closer to real-world deployment.
From Monocular Vision to Autonomous Action: Guiding Tumor Resection via 3D Reconstruction
Mar 20, 2025Surgical automation requires precise guidance and understanding of the scene. Current methods in the literature rely on bulky depth cameras to create maps of the anatomy, however this does not translate well to space-limited clinical applications. Monocular cameras are small and allow minimally invasive surgeries in tight spaces but additional processing is required to generate 3D scene understanding. We propose a 3D mapping pipeline that uses only RGB images to create segmented point clouds of the target anatomy. To ensure the most precise reconstruction, we compare different structure from motion algorithms' performance on mapping the central airway obstructions, and test the pipeline on a downstream task of tumor resection. In several metrics, including post-procedure tissue model evaluation, our pipeline performs comparably to RGB-D cameras and, in some cases, even surpasses their performance. These promising results demonstrate that automation guidance can be achieved in minimally invasive procedures with monocular cameras. This study is a step toward the complete autonomy of surgical robots.
Surgical Gaussian Surfels: Highly Accurate Real-time Surgical Scene Rendering
Mar 06, 2025
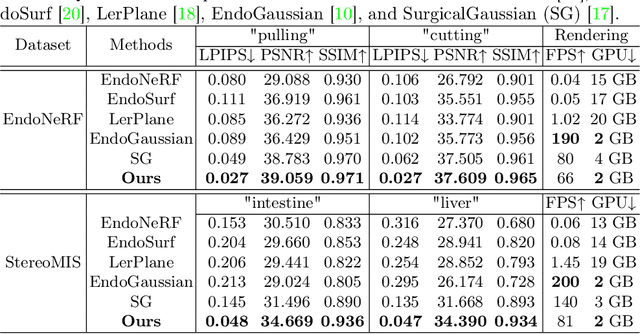

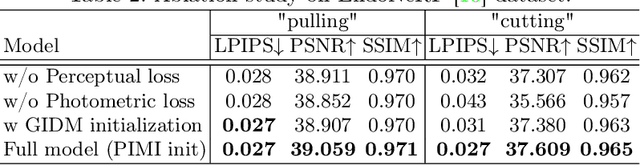
Accurate geometric reconstruction of deformable tissues in monocular endoscopic video remains a fundamental challenge in robot-assisted minimally invasive surgery. Although recent volumetric and point primitive methods based on neural radiance fields (NeRF) and 3D Gaussian primitives have efficiently rendered surgical scenes, they still struggle with handling artifact-free tool occlusions and preserving fine anatomical details. These limitations stem from unrestricted Gaussian scaling and insufficient surface alignment constraints during reconstruction. To address these issues, we introduce Surgical Gaussian Surfels (SGS), which transforms anisotropic point primitives into surface-aligned elliptical splats by constraining the scale component of the Gaussian covariance matrix along the view-aligned axis. We predict accurate surfel motion fields using a lightweight Multi-Layer Perceptron (MLP) coupled with locality constraints to handle complex tissue deformations. We use homodirectional view-space positional gradients to capture fine image details by splitting Gaussian Surfels in over-reconstructed regions. In addition, we define surface normals as the direction of the steepest density change within each Gaussian surfel primitive, enabling accurate normal estimation without requiring monocular normal priors. We evaluate our method on two in-vivo surgical datasets, where it outperforms current state-of-the-art methods in surface geometry, normal map quality, and rendering efficiency, while remaining competitive in real-time rendering performance. We make our code available at https://github.com/aloma85/SurgicalGaussianSurfels
Towards Fluorescence-Guided Autonomous Robotic Partial Nephrectomy on Novel Tissue-Mimicking Hydrogel Phantoms
Mar 04, 2025Autonomous robotic systems hold potential for improving renal tumor resection accuracy and patient outcomes. We present a fluorescence-guided robotic system capable of planning and executing incision paths around exophytic renal tumors with a clinically relevant resection margin. Leveraging point cloud observations, the system handles irregular tumor shapes and distinguishes healthy from tumorous tissue based on near-infrared imaging, akin to indocyanine green staining in partial nephrectomy. Tissue-mimicking phantoms are crucial for the development of autonomous robotic surgical systems for interventions where acquiring ex-vivo animal tissue is infeasible, such as cancer of the kidney and renal pelvis. To this end, we propose novel hydrogel-based kidney phantoms with exophytic tumors that mimic the physical and visual behavior of tissue, and are compatible with electrosurgical instruments, a common limitation of silicone-based phantoms. In contrast to previous hydrogel phantoms, we mix the material with near-infrared dye to enable fluorescence-guided tumor segmentation. Autonomous real-world robotic experiments validate our system and phantoms, achieving an average margin accuracy of 1.44 mm in a completion time of 69 sec.
LUDO: Low-Latency Understanding of Highly Deformable Objects using Point Cloud Occupancy Functions
Nov 13, 2024Accurately determining the shape and location of internal structures within deformable objects is crucial for medical tasks that require precise targeting, such as robotic biopsies. We introduce LUDO, a method for accurate low-latency understanding of deformable objects. LUDO reconstructs objects in their deformed state, including their internal structures, from a single-view point cloud observation in under 30 ms using occupancy networks. We demonstrate LUDO's abilities for autonomous targeting of internal regions of interest (ROIs) in highly deformable objects. Additionally, LUDO provides uncertainty estimates and explainability for its predictions, both of which are important in safety-critical applications such as surgical interventions. We evaluate LUDO in real-world robotic experiments, achieving a success rate of 98.9% for puncturing various ROIs inside highly deformable objects. LUDO demonstrates the potential to interact with deformable objects without the need for deformable registration methods.
Sim-To-Real Transfer for Visual Reinforcement Learning of Deformable Object Manipulation for Robot-Assisted Surgery
Jun 10, 2024Automation holds the potential to assist surgeons in robotic interventions, shifting their mental work load from visuomotor control to high level decision making. Reinforcement learning has shown promising results in learning complex visuomotor policies, especially in simulation environments where many samples can be collected at low cost. A core challenge is learning policies in simulation that can be deployed in the real world, thereby overcoming the sim-to-real gap. In this work, we bridge the visual sim-to-real gap with an image-based reinforcement learning pipeline based on pixel-level domain adaptation and demonstrate its effectiveness on an image-based task in deformable object manipulation. We choose a tissue retraction task because of its importance in clinical reality of precise cancer surgery. After training in simulation on domain-translated images, our policy requires no retraining to perform tissue retraction with a 50% success rate on the real robotic system using raw RGB images. Furthermore, our sim-to-real transfer method makes no assumptions on the task itself and requires no paired images. This work introduces the first successful application of visual sim-to-real transfer for robotic manipulation of deformable objects in the surgical field, which represents a notable step towards the clinical translation of cognitive surgical robotics.
Movement Primitive Diffusion: Learning Gentle Robotic Manipulation of Deformable Objects
Dec 15, 2023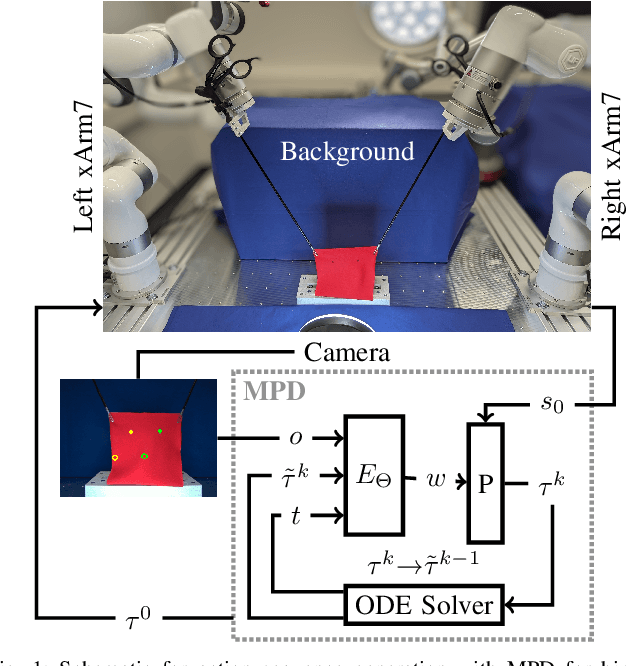
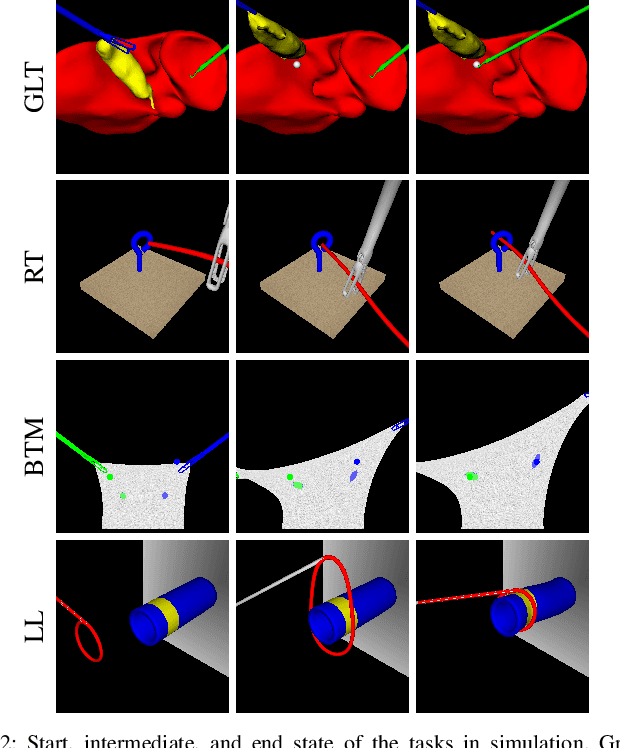

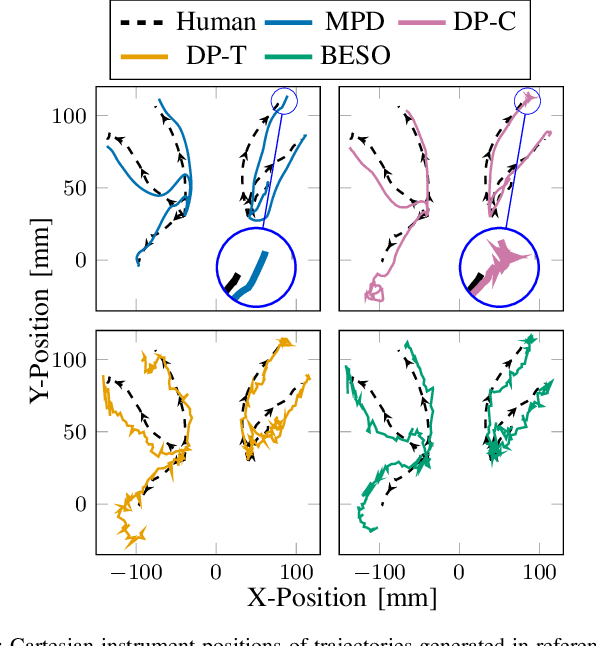
Policy learning in robot-assisted surgery (RAS) lacks data efficient and versatile methods that exhibit the desired motion quality for delicate surgical interventions. To this end, we introduce Movement Primitive Diffusion (MPD), a novel method for imitation learning (IL) in RAS that focuses on gentle manipulation of deformable objects. The approach combines the versatility of diffusion-based imitation learning (DIL) with the high-quality motion generation capabilities of Probabilistic Dynamic Movement Primitives (ProDMPs). This combination enables MPD to achieve gentle manipulation of deformable objects, while maintaining data efficiency critical for RAS applications where demonstration data is scarce. We evaluate MPD across various simulated tasks and a real world robotic setup on both state and image observations. MPD outperforms state-of-the-art DIL methods in success rate, motion quality, and data efficiency.
Registered and Segmented Deformable Object Reconstruction from a Single View Point Cloud
Nov 13, 2023In deformable object manipulation, we often want to interact with specific segments of an object that are only defined in non-deformed models of the object. We thus require a system that can recognize and locate these segments in sensor data of deformed real world objects. This is normally done using deformable object registration, which is problem specific and complex to tune. Recent methods utilize neural occupancy functions to improve deformable object registration by registering to an object reconstruction. Going one step further, we propose a system that in addition to reconstruction learns segmentation of the reconstructed object. As the resulting output already contains the information about the segments, we can skip the registration process. Tested on a variety of deformable objects in simulation and the real world, we demonstrate that our method learns to robustly find these segments. We also introduce a simple sampling algorithm to generate better training data for occupancy learning.
Grounding Graph Network Simulators using Physical Sensor Observations
Mar 07, 2023



Physical simulations that accurately model reality are crucial for many engineering disciplines such as mechanical engineering and robotic motion planning. In recent years, learned Graph Network Simulators produced accurate mesh-based simulations while requiring only a fraction of the computational cost of traditional simulators. Yet, the resulting predictors are confined to learning from data generated by existing mesh-based simulators and thus cannot include real world sensory information such as point cloud data. As these predictors have to simulate complex physical systems from only an initial state, they exhibit a high error accumulation for long-term predictions. In this work, we integrate sensory information to ground Graph Network Simulators on real world observations. In particular, we predict the mesh state of deformable objects by utilizing point cloud data. The resulting model allows for accurate predictions over longer time horizons, even under uncertainties in the simulation, such as unknown material properties. Since point clouds are usually not available for every time step, especially in online settings, we employ an imputation-based model. The model can make use of such additional information only when provided, and resorts to a standard Graph Network Simulator, otherwise. We experimentally validate our approach on a suite of prediction tasks for mesh-based interactions between soft and rigid bodies. Our method results in utilization of additional point cloud information to accurately predict stable simulations where existing Graph Network Simulators fail.