 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Segmentation for Autonomous Clip Positioning in Laparoscopic Cholecystectomy on a Phantom
Jun 10, 2026High-risk applications in robotics, such as robot-assisted surgery, present unique challenges. These systems must be both highly precise and interpretable in order to be deployed in environments with very low tolerance for error or unsafe exploration. We present the first robotic system to demonstrate autonomous clip positioning on a physical phantom in laparoscopic surgery, one of the most common interventions in general surgery. After segmentation of a colorless point cloud from a single camera, target positions for the clips are extracted using spline interpolation, and can then be adjusted by the human operator. The segmentation model is trained on only 60 hand-labeled real point clouds, reflecting data scarcity in the surgical domain. We overcome this with a combination of pre-training on 128,000 synthetic point clouds and two novel data augmentation techniques. The motion of the end-effector to each target is visualized for the operator, satisfying the unique motion constraints of minimally-invasive surgery while ensuring that the robot's actions are verifiable and interpretable. In real robot experiments, our system localizes targets with the required precision of 0.75mm at a 95% success rate and executes autonomous clip positioning with a 100% success rate. We provide insights that are applicable to many other surgical and non-surgical tasks that require identifying and navigating to a precise target. Source code and project page: https://github.com/balazsgyenes/kirurc
* 8 pages, 5 figures, accepted to IEEE Robotics and Automation Letters (RAL)
Fourier Features Let Agents Learn High Precision Policies with Imitation Learning
Jun 10, 2026High-precision robotic manipulation requires fine-grained spatial reasoning that is often difficult to achieve with RGB-only policies due to depth ambiguity and perspective scale issues. Policies that leverage 3D information directly, such as those based on point clouds, offer a stronger geometric prior over purely image-based ones, yet their performance remains highly task-dependent. We hypothesize that this discrepancy may be due to the spectral bias of neural networks towards learning low frequency functions, which especially affects architectures conditioned on slow-moving Cartesian features. We thus propose to map point clouds from Cartesian space into high-dimensional Fourier space, effectively equipping the point cloud encoder with direct access to high-frequency features. We experimentally validate the use of Fourier features on challenging manipulation tasks from the RoboCasa and ManiSkill3 benchmarks and on a real robot setup. Despite their simplicity, we find that Fourier features provide significant benefits across diverse encoder architectures and benchmarks and are robust across hyperparameters. Our results indicate that Fourier features let policies leverage geometric details more effectively than Cartesian features, showing their potential as a general-purpose tool for point cloud-based imitation learning. We provide source code and videos on our project page: https://fourier-il.github.io/fourier-il
Point Cloud Sequence Encoding for Material-conditioned Graph Network Simulators
May 20, 2026Graph Network Simulators (GNSs) have emerged as powerful surrogates for complex physics-based simulation, offering inherent differentiability and orders-of-magnitude speedups over traditional solvers. However, GNSs typically assume access to the underlying material parameters, such as stiffness or viscosity, severely limiting their utility in realistic experimental settings. While recent meta-learning approaches address the parameter dependency by inferring properties from mesh trajectories, reconstructing a mesh from an observed scene is challenging. In this work, we introduce Point Cloud Encoding for Accurate Context Handling (PEACH), a novel framework that applies in-context learning on point clouds to adapt a learned simulator to unseen physical properties during inference. Our approach relies on a novel spatio-temporal point cloud sequence encoder, as well as two forms of auxiliary supervision to help improve simulation fidelity. We demonstrate that PEACH is capable of accurate zero-shot sim-to-real transfer on a challenging, dynamic scene. Experiments on simulation scenes show that PEACH even outperforms mesh-based baselines on prediction accuracy, while being much more practical for real-world deployment.
PointMapPolicy: Structured Point Cloud Processing for Multi-Modal Imitation Learning
Oct 23, 2025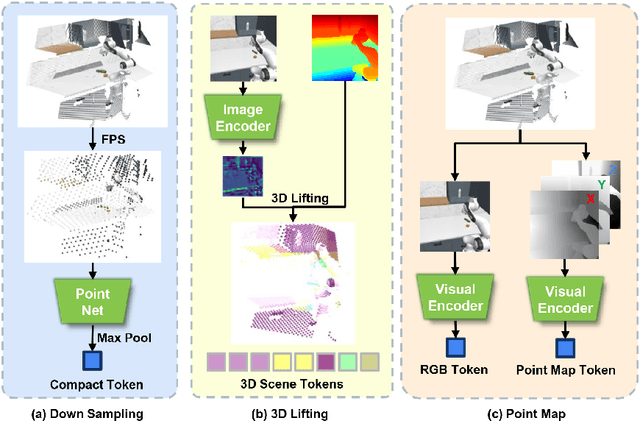
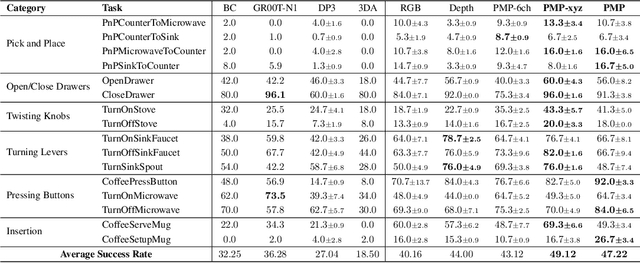
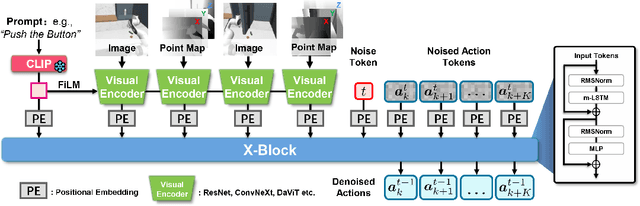
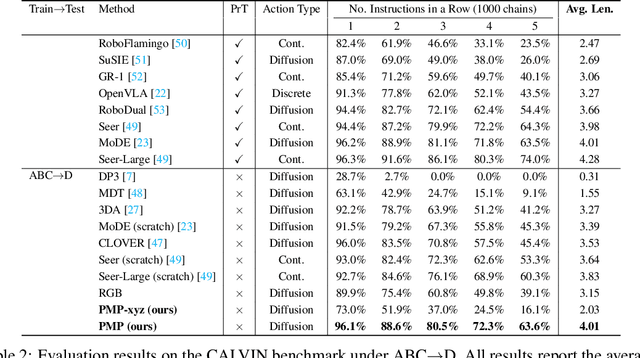
Robotic manipulation systems benefit from complementary sensing modalities, where each provides unique environmental information. Point clouds capture detailed geometric structure, while RGB images provide rich semantic context. Current point cloud methods struggle to capture fine-grained detail, especially for complex tasks, which RGB methods lack geometric awareness, which hinders their precision and generalization. We introduce PointMapPolicy, a novel approach that conditions diffusion policies on structured grids of points without downsampling. The resulting data type makes it easier to extract shape and spatial relationships from observations, and can be transformed between reference frames. Yet due to their structure in a regular grid, we enable the use of established computer vision techniques directly to 3D data. Using xLSTM as a backbone, our model efficiently fuses the point maps with RGB data for enhanced multi-modal perception. Through extensive experiments on the RoboCasa and CALVIN benchmarks and real robot evaluations, we demonstrate that our method achieves state-of-the-art performance across diverse manipulation tasks. The overview and demos are available on our project page: https://point-map.github.io/Point-Map/
PointPatchRL -- Masked Reconstruction Improves Reinforcement Learning on Point Clouds
Oct 24, 2024



Perceiving the environment via cameras is crucial for Reinforcement Learning (RL) in robotics. While images are a convenient form of representation, they often complicate extracting important geometric details, especially with varying geometries or deformable objects. In contrast, point clouds naturally represent this geometry and easily integrate color and positional data from multiple camera views. However, while deep learning on point clouds has seen many recent successes, RL on point clouds is under-researched, with only the simplest encoder architecture considered in the literature. We introduce PointPatchRL (PPRL), a method for RL on point clouds that builds on the common paradigm of dividing point clouds into overlapping patches, tokenizing them, and processing the tokens with transformers. PPRL provides significant improvements compared with other point-cloud processing architectures previously used for RL. We then complement PPRL with masked reconstruction for representation learning and show that our method outperforms strong model-free and model-based baselines on image observations in complex manipulation tasks containing deformable objects and variations in target object geometry. Videos and code are available at https://alrhub.github.io/pprl-website
Sim-To-Real Transfer for Visual Reinforcement Learning of Deformable Object Manipulation for Robot-Assisted Surgery
Jun 10, 2024Automation holds the potential to assist surgeons in robotic interventions, shifting their mental work load from visuomotor control to high level decision making. Reinforcement learning has shown promising results in learning complex visuomotor policies, especially in simulation environments where many samples can be collected at low cost. A core challenge is learning policies in simulation that can be deployed in the real world, thereby overcoming the sim-to-real gap. In this work, we bridge the visual sim-to-real gap with an image-based reinforcement learning pipeline based on pixel-level domain adaptation and demonstrate its effectiveness on an image-based task in deformable object manipulation. We choose a tissue retraction task because of its importance in clinical reality of precise cancer surgery. After training in simulation on domain-translated images, our policy requires no retraining to perform tissue retraction with a 50% success rate on the real robotic system using raw RGB images. Furthermore, our sim-to-real transfer method makes no assumptions on the task itself and requires no paired images. This work introduces the first successful application of visual sim-to-real transfer for robotic manipulation of deformable objects in the surgical field, which represents a notable step towards the clinical translation of cognitive surgical robotics.
Registered and Segmented Deformable Object Reconstruction from a Single View Point Cloud
Nov 13, 2023



In deformable object manipulation, we often want to interact with specific segments of an object that are only defined in non-deformed models of the object. We thus require a system that can recognize and locate these segments in sensor data of deformed real world objects. This is normally done using deformable object registration, which is problem specific and complex to tune. Recent methods utilize neural occupancy functions to improve deformable object registration by registering to an object reconstruction. Going one step further, we propose a system that in addition to reconstruction learns segmentation of the reconstructed object. As the resulting output already contains the information about the segments, we can skip the registration process. Tested on a variety of deformable objects in simulation and the real world, we demonstrate that our method learns to robustly find these segments. We also introduce a simple sampling algorithm to generate better training data for occupancy learning.
LapGym -- An Open Source Framework for Reinforcement Learning in Robot-Assisted Laparoscopic Surgery
Feb 19, 2023



Recent advances in reinforcement learning (RL) have increased the promise of introducing cognitive assistance and automation to robot-assisted laparoscopic surgery (RALS). However, progress in algorithms and methods depends on the availability of standardized learning environments that represent skills relevant to RALS. We present LapGym, a framework for building RL environments for RALS that models the challenges posed by surgical tasks, and sofa_env, a diverse suite of 12 environments. Motivated by surgical training, these environments are organized into 4 tracks: Spatial Reasoning, Deformable Object Manipulation & Grasping, Dissection, and Thread Manipulation. Each environment is highly parametrizable for increasing difficulty, resulting in a high performance ceiling for new algorithms. We use Proximal Policy Optimization (PPO) to establish a baseline for model-free RL algorithms, investigating the effect of several environment parameters on task difficulty. Finally, we show that many environments and parameter configurations reflect well-known, open problems in RL research, allowing researchers to continue exploring these fundamental problems in a surgical context. We aim to provide a challenging, standard environment suite for further development of RL for RALS, ultimately helping to realize the full potential of cognitive surgical robotics. LapGym is publicly accessible through GitHub (https://github.com/ScheiklP/lap_gym).
Cooperative Assistance in Robotic Surgery through Multi-Agent Reinforcement Learning
Oct 10, 2021

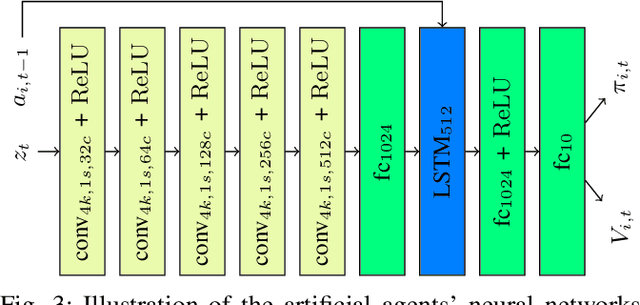
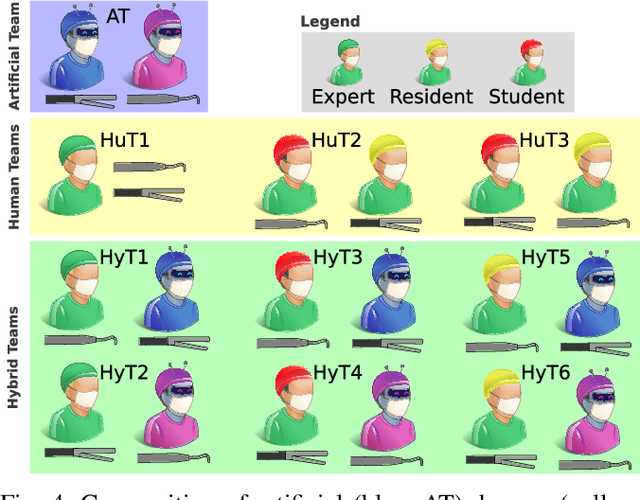
Cognitive cooperative assistance in robot-assisted surgery holds the potential to increase quality of care in minimally invasive interventions. Automation of surgical tasks promises to reduce the mental exertion and fatigue of surgeons. In this work, multi-agent reinforcement learning is demonstrated to be robust to the distribution shift introduced by pairing a learned policy with a human team member. Multi-agent policies are trained directly from images in simulation to control multiple instruments in a sub task of the minimally invasive removal of the gallbladder. These agents are evaluated individually and in cooperation with humans to demonstrate their suitability as autonomous assistants. Compared to human teams, the hybrid teams with artificial agents perform better considering completion time (44.4% to 71.2% shorter) as well as number of collisions (44.7% to 98.0% fewer). Path lengths, however, increase under control of an artificial agent (11.4% to 33.5% longer). A multi-agent formulation of the learning problem was favored over a single-agent formulation on this surgical sub task, due to the sequential learning of the two instruments. This approach may be extended to other tasks that are difficult to formulate within the standard reinforcement learning framework. Multi-agent reinforcement learning may shift the paradigm of cognitive robotic surgery towards seamless cooperation between surgeons and assistive technologies.