 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Position Statement on Endovascular Models and Effectiveness Metrics for Mechanical Thrombectomy Navigation, on behalf of the Stakeholder Taskforce for AI-assisted Robotic Thrombectomy (START)
Mar 30, 2026While we are making progress in overcoming infectious diseases and cancer; one of the major medical challenges of the mid-21st century will be the rising prevalence of stroke. Large vessels occlusions are especially debilitating, yet effective treatment (needed within hours to achieve best outcomes) remains limited due to geography. One solution for improving timely access to mechanical thrombectomy in geographically diverse populations is the deployment of robotic surgical systems. Artificial intelligence (AI) assistance may enable the upskilling of operators in this emerging therapeutic delivery approach. Our aim was to establish consensus frameworks for developing and validating AI-assisted robots for thrombectomy. Objectives included standardizing effectiveness metrics and defining reference testbeds across in silico, in vitro, ex vivo, and in vivo environments. To achieve this, we convened experts in neurointervention, robotics, data science, health economics, policy, statistics, and patient advocacy. Consensus was built through an incubator day, a Delphi process, and a final Position Statement. We identified that the four essential testbed environments each had distinct validation roles. Realism requirements vary: simpler testbeds should include realistic vessel anatomy compatible with guidewire and catheter use, while standard testbeds should incorporate deformable vessels. More advanced testbeds should include blood flow, pulsatility, and disease features. There are two macro-classes of effectiveness metrics: one for in silico, in vitro, and ex vivo stages focusing on technical navigation, and another for in vivo stages, focused on clinical outcomes. Patient safety is central to this technology's development. One requisite patient safety task needed now is to correlate in vitro measurements to in vivo complications.
* Published in Journal of the American Heart Association
Ensemble Learning and 3D Pix2Pix for Comprehensive Brain Tumor Analysis in Multimodal MRI
Dec 16, 2024



Motivated by the need for advanced solutions in the segmentation and inpainting of glioma-affected brain regions in multi-modal magnetic resonance imaging (MRI), this study presents an integrated approach leveraging the strengths of ensemble learning with hybrid transformer models and convolutional neural networks (CNNs), alongside the innovative application of 3D Pix2Pix Generative Adversarial Network (GAN). Our methodology combines robust tumor segmentation capabilities, utilizing axial attention and transformer encoders for enhanced spatial relationship modeling, with the ability to synthesize biologically plausible brain tissue through 3D Pix2Pix GAN. This integrated approach addresses the BraTS 2023 cluster challenges by offering precise segmentation and realistic inpainting, tailored for diverse tumor types and sub-regions. The results demonstrate outstanding performance, evidenced by quantitative evaluations such as the Dice Similarity Coefficient (DSC), Hausdorff Distance (HD95) for segmentation, and Structural Similarity Index Measure (SSIM), Peak Signal-to-Noise Ratio (PSNR), and Mean-Square Error (MSE) for inpainting. Qualitative assessments further validate the high-quality, clinically relevant outputs. In conclusion, this study underscores the potential of combining advanced machine learning techniques for comprehensive brain tumor analysis, promising significant advancements in clinical decision-making and patient care within the realm of medical imaging.
Unified HT-CNNs Architecture: Transfer Learning for Segmenting Diverse Brain Tumors in MRI from Gliomas to Pediatric Tumors
Dec 11, 2024



Accurate segmentation of brain tumors from 3D multimodal MRI is vital for diagnosis and treatment planning across diverse brain tumors. This paper addresses the challenges posed by the BraTS 2023, presenting a unified transfer learning approach that applies to a broader spectrum of brain tumors. We introduce HT-CNNs, an ensemble of Hybrid Transformers and Convolutional Neural Networks optimized through transfer learning for varied brain tumor segmentation. This method captures spatial and contextual details from MRI data, fine-tuned on diverse datasets representing common tumor types. Through transfer learning, HT-CNNs utilize the learned representations from one task to improve generalization in another, harnessing the power of pre-trained models on large datasets and fine-tuning them on specific tumor types. We preprocess diverse datasets from multiple international distributions, ensuring representativeness for the most common brain tumors. Our rigorous evaluation employs standardized quantitative metrics across all tumor types, ensuring robustness and generalizability. The proposed ensemble model achieves superior segmentation results across the BraTS validation datasets over the previous winning methods. Comprehensive quantitative evaluations using the DSC and HD95 demonstrate the effectiveness of our approach. Qualitative segmentation predictions further validate the high-quality outputs produced by our model. Our findings underscore the potential of transfer learning and ensemble approaches in medical image segmentation, indicating a substantial enhancement in clinical decision-making and patient care. Despite facing challenges related to post-processing and domain gaps, our study sets a new precedent for future research for brain tumor segmentation. The docker image for the code and models has been made publicly available, https://hub.docker.com/r/razeineldin/ht-cnns.
LUDO: Low-Latency Understanding of Highly Deformable Objects using Point Cloud Occupancy Functions
Nov 13, 2024Accurately determining the shape and location of internal structures within deformable objects is crucial for medical tasks that require precise targeting, such as robotic biopsies. We introduce LUDO, a method for accurate low-latency understanding of deformable objects. LUDO reconstructs objects in their deformed state, including their internal structures, from a single-view point cloud observation in under 30 ms using occupancy networks. We demonstrate LUDO's abilities for autonomous targeting of internal regions of interest (ROIs) in highly deformable objects. Additionally, LUDO provides uncertainty estimates and explainability for its predictions, both of which are important in safety-critical applications such as surgical interventions. We evaluate LUDO in real-world robotic experiments, achieving a success rate of 98.9% for puncturing various ROIs inside highly deformable objects. LUDO demonstrates the potential to interact with deformable objects without the need for deformable registration methods.
Tracking Tumors under Deformation from Partial Point Clouds using Occupancy Networks
Nov 04, 2024



To track tumors during surgery, information from preoperative CT scans is used to determine their position. However, as the surgeon operates, the tumor may be deformed which presents a major hurdle for accurately resecting the tumor, and can lead to surgical inaccuracy, increased operation time, and excessive margins. This issue is particularly pronounced in robot-assisted partial nephrectomy (RAPN), where the kidney undergoes significant deformations during operation. Toward addressing this, we introduce a occupancy network-based method for the localization of tumors within kidney phantoms undergoing deformations at interactive speeds. We validate our method by introducing a 3D hydrogel kidney phantom embedded with exophytic and endophytic renal tumors. It closely mimics real tissue mechanics to simulate kidney deformation during in vivo surgery, providing excellent contrast and clear delineation of tumor margins to enable automatic threshold-based segmentation. Our findings indicate that the proposed method can localize tumors in moderately deforming kidneys with a margin of 6mm to 10mm, while providing essential volumetric 3D information at over 60Hz. This capability directly enables downstream tasks such as robotic resection.
Learning-Based Autonomous Navigation, Benchmark Environments and Simulation Framework for Endovascular Interventions
Oct 02, 2024



Endovascular interventions are a life-saving treatment for many diseases, yet suffer from drawbacks such as radiation exposure and potential scarcity of proficient physicians. Robotic assistance during these interventions could be a promising support towards these problems. Research focusing on autonomous endovascular interventions utilizing artificial intelligence-based methodologies is gaining popularity. However, variability in assessment environments hinders the ability to compare and contrast the efficacy of different approaches, primarily due to each study employing a unique evaluation framework. In this study, we present deep reinforcement learning-based autonomous endovascular device navigation on three distinct digital benchmark interventions: BasicWireNav, ArchVariety, and DualDeviceNav. The benchmark interventions were implemented with our modular simulation framework stEVE (simulated EndoVascular Environment). Autonomous controllers were trained solely in simulation and evaluated in simulation and on physical test benches with camera and fluoroscopy feedback. Autonomous control for BasicWireNav and ArchVariety reached high success rates and was successfully transferred from the simulated training environment to the physical test benches, while autonomous control for DualDeviceNav reached a moderate success rate. The experiments demonstrate the feasibility of stEVE and its potential for transferring controllers trained in simulation to real-world scenarios. Nevertheless, they also reveal areas that offer opportunities for future research. This study demonstrates the transferability of autonomous controllers from simulation to the real world in endovascular navigation and lowers the entry barriers and increases the comparability of research on endovascular assistance systems by providing open-source training scripts, benchmarks and the stEVE framework.
Interactive Surgical Liver Phantom for Cholecystectomy Training
Sep 05, 2024
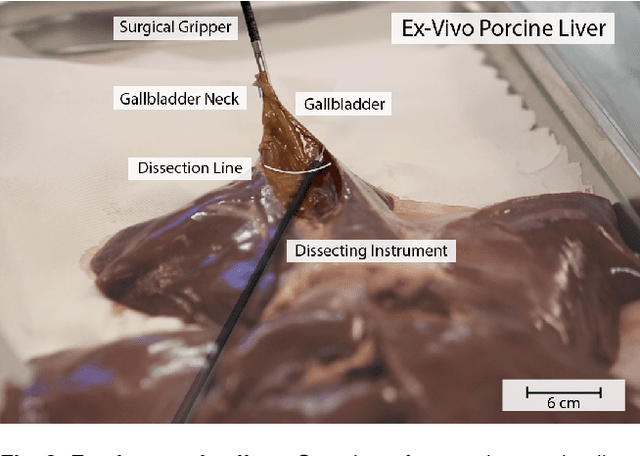
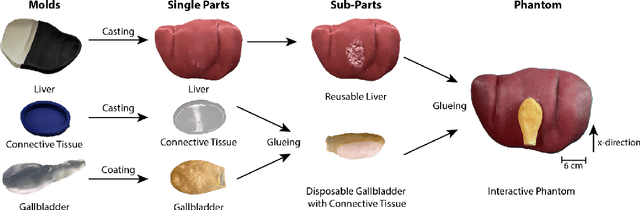
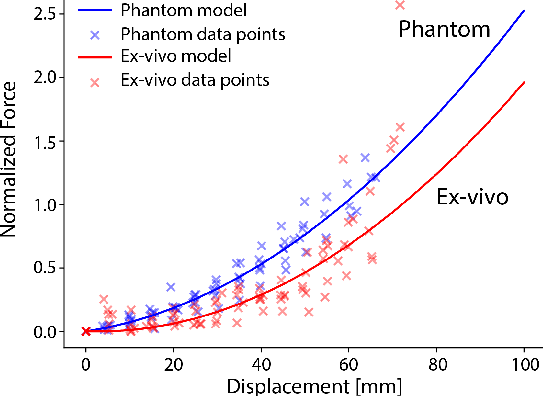
Training and prototype development in robot-assisted surgery requires appropriate and safe environments for the execution of surgical procedures. Current dry lab laparoscopy phantoms often lack the ability to mimic complex, interactive surgical tasks. This work presents an interactive surgical phantom for the cholecystectomy. The phantom enables the removal of the gallbladder during cholecystectomy by allowing manipulations and cutting interactions with the synthetic tissue. The force-displacement behavior of the gallbladder is modelled based on retraction demonstrations. The force model is compared to the force model of ex-vivo porcine gallbladders and evaluated on its ability to estimate retraction forces.
LOOC: Localizing Organs using Occupancy Networks and Body Surface Depth Images
Jun 18, 2024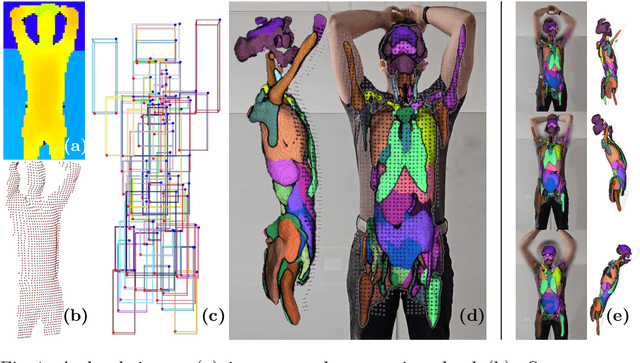
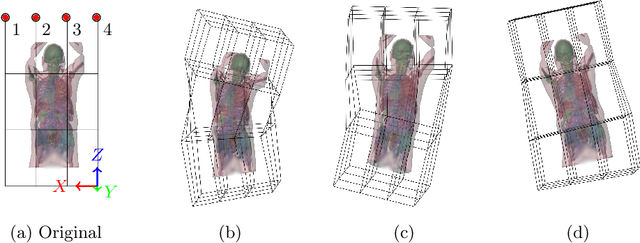
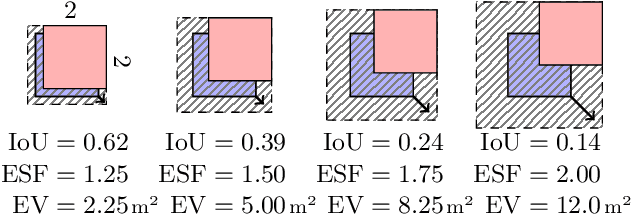
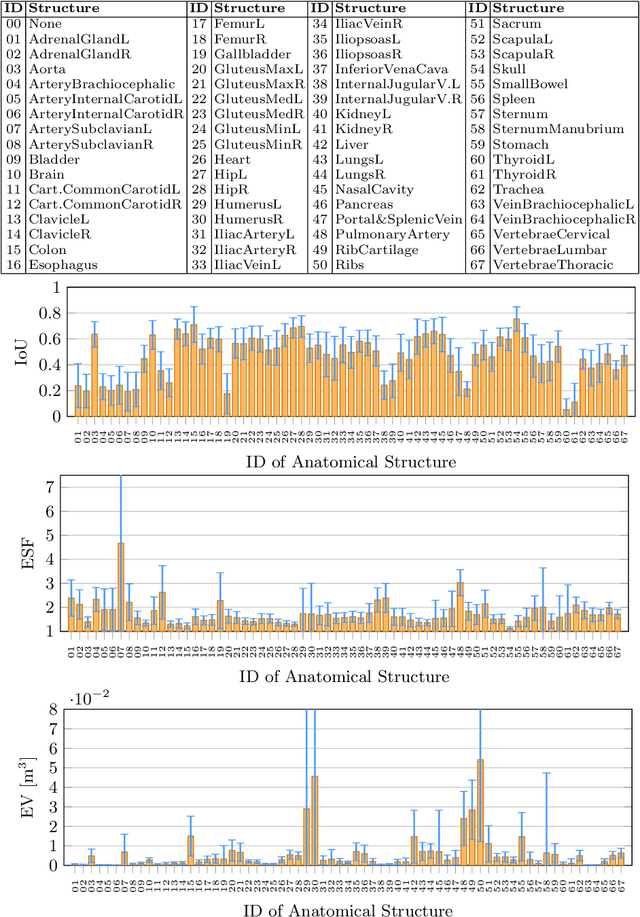
We introduce a novel method employing occupancy networks for the precise localization of 67 anatomical structures from single depth images captured from the exterior of the human body. This method considers the anatomical diversity across individuals. Our contributions include the application of occupancy networks for occluded structure localization, a robust method for estimating anatomical positions from depth images, and the creation of detailed, individualized 3D anatomical atlases. This approach promises improvements in medical imaging and automated diagnostic procedures by offering accurate, non-invasive localization of critical anatomical features.
Sim-To-Real Transfer for Visual Reinforcement Learning of Deformable Object Manipulation for Robot-Assisted Surgery
Jun 10, 2024Automation holds the potential to assist surgeons in robotic interventions, shifting their mental work load from visuomotor control to high level decision making. Reinforcement learning has shown promising results in learning complex visuomotor policies, especially in simulation environments where many samples can be collected at low cost. A core challenge is learning policies in simulation that can be deployed in the real world, thereby overcoming the sim-to-real gap. In this work, we bridge the visual sim-to-real gap with an image-based reinforcement learning pipeline based on pixel-level domain adaptation and demonstrate its effectiveness on an image-based task in deformable object manipulation. We choose a tissue retraction task because of its importance in clinical reality of precise cancer surgery. After training in simulation on domain-translated images, our policy requires no retraining to perform tissue retraction with a 50% success rate on the real robotic system using raw RGB images. Furthermore, our sim-to-real transfer method makes no assumptions on the task itself and requires no paired images. This work introduces the first successful application of visual sim-to-real transfer for robotic manipulation of deformable objects in the surgical field, which represents a notable step towards the clinical translation of cognitive surgical robotics.
Movement Primitive Diffusion: Learning Gentle Robotic Manipulation of Deformable Objects
Dec 15, 2023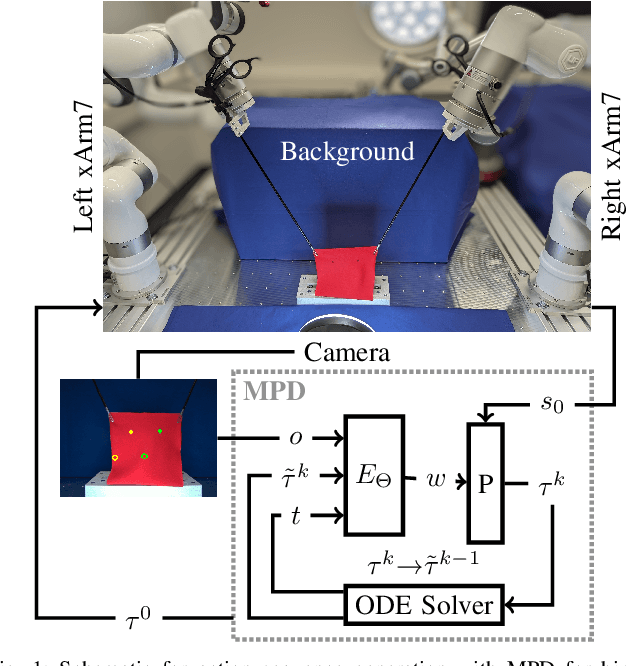
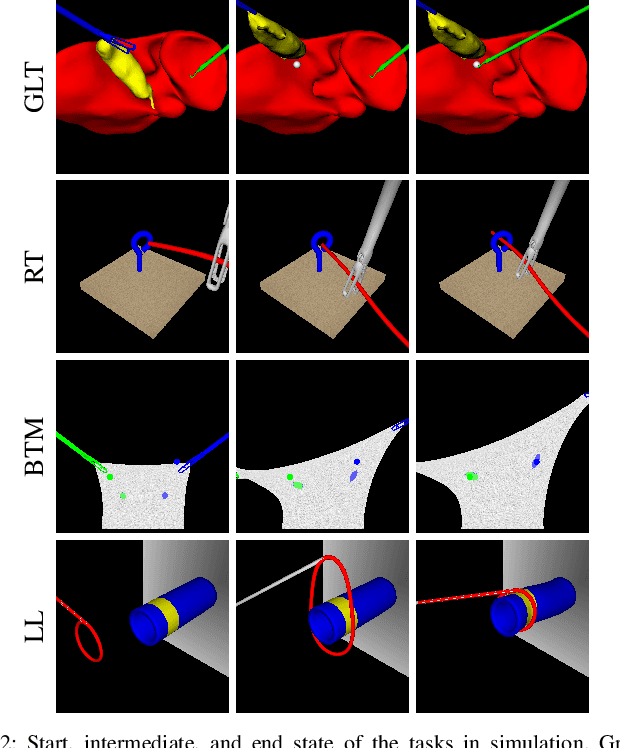

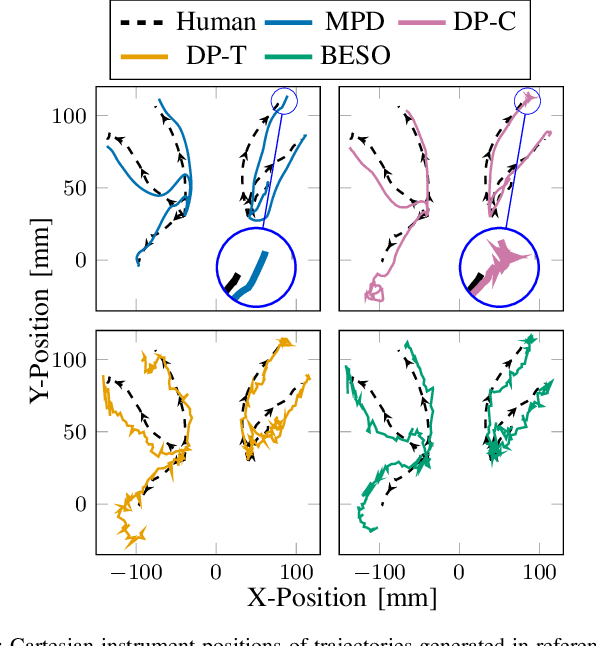
Policy learning in robot-assisted surgery (RAS) lacks data efficient and versatile methods that exhibit the desired motion quality for delicate surgical interventions. To this end, we introduce Movement Primitive Diffusion (MPD), a novel method for imitation learning (IL) in RAS that focuses on gentle manipulation of deformable objects. The approach combines the versatility of diffusion-based imitation learning (DIL) with the high-quality motion generation capabilities of Probabilistic Dynamic Movement Primitives (ProDMPs). This combination enables MPD to achieve gentle manipulation of deformable objects, while maintaining data efficiency critical for RAS applications where demonstration data is scarce. We evaluate MPD across various simulated tasks and a real world robotic setup on both state and image observations. MPD outperforms state-of-the-art DIL methods in success rate, motion quality, and data efficiency.