 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mobile Magnetic Manipulation Platform for Gastrointestinal Navigation with Deep Reinforcement Learning Control
Jan 22, 2026Targeted drug delivery in the gastrointestinal (GI) tract using magnetic robots offers a promising alternative to systemic treatments. However, controlling these robots is a major challenge. Stationary magnetic systems have a limited workspace, while mobile systems (e.g., coils on a robotic arm) suffer from a "model-calibration bottleneck", requiring complex, pre-calibrated physical models that are time-consuming to create and computationally expensive. This paper presents a compact, low-cost mobile magnetic manipulation platform that overcomes this limitation using Deep Reinforcement Learning (DRL). Our system features a compact four-electromagnet array mounted on a UR5 collaborative robot. A Soft Actor-Critic (SAC)-based control strategy is trained through a sim-to-real pipeline, enabling effective policy deployment within 15 minutes and significantly reducing setup time. We validated the platform by controlling a 7-mm magnetic capsule along 2D trajectories. Our DRL-based controller achieved a root-mean-square error (RMSE) of 1.18~mm for a square path and 1.50~mm for a circular path. We also demonstrated successful tracking over a clinically relevant, 30 cm * 20 cm workspace. This work demonstrates a rapidly deployable, model-free control framework capable of precise magnetic manipulation in a large workspace,validated using a 2D GI phantom.
SurgiPose: Estimating Surgical Tool Kinematics from Monocular Video for Surgical Robot Learning
Dec 19, 2025Imitation learning (IL) has shown immense promise in enabling autonomous dexterous manipulation, including learning surgical tasks. To fully unlock the potential of IL for surgery, access to clinical datasets is needed, which unfortunately lack the kinematic data required for current IL approaches. A promising source of large-scale surgical demonstrations is monocular surgical videos available online, making monocular pose estimation a crucial step toward enabling large-scale robot learning. Toward this end, we propose SurgiPose, a differentiable rendering based approach to estimate kinematic information from monocular surgical videos, eliminating the need for direct access to ground truth kinematics. Our method infers tool trajectories and joint angles by optimizing tool pose parameters to minimize the discrepancy between rendered and real images. To evaluate the effectiveness of our approach, we conduct experiments on two robotic surgical tasks: tissue lifting and needle pickup, using the da Vinci Research Kit Si (dVRK Si). We train imitation learning policies with both ground truth measured kinematics and estimated kinematics from video and compare their performance. Our results show that policies trained on estimated kinematics achieve comparable success rates to those trained on ground truth data, demonstrating the feasibility of using monocular video based kinematic estimation for surgical robot learning. By enabling kinematic estimation from monocular surgical videos, our work lays the foundation for large scale learning of autonomous surgical policies from online surgical data.
* 8 pages, 6 figures, 2 tables
A Supervised Autonomous Resection and Retraction Framework for Transurethral Enucleation of the Prostatic Median Lobe
Nov 11, 2025Concentric tube robots (CTRs) offer dexterous motion at millimeter scales, enabling minimally invasive procedures through natural orifices. This work presents a coordinated model-based resection planner and learning-based retraction network that work together to enable semi-autonomous tissue resection using a dual-arm transurethral concentric tube robot (the Virtuoso). The resection planner operates directly on segmented CT volumes of prostate phantoms, automatically generating tool trajectories for a three-phase median lobe resection workflow: left/median trough resection, right/median trough resection, and median blunt dissection. The retraction network, PushCVAE, trained on surgeon demonstrations, generates retractions according to the procedural phase. The procedure is executed under Level-3 (supervised) autonomy on a prostate phantom composed of hydrogel materials that replicate the mechanical and cutting properties of tissue. As a feasibility study, we demonstrate that our combined autonomous system achieves a 97.1% resection of the targeted volume of the median lobe. Our study establishes a foundation for image-guided autonomy in transurethral robotic surgery and represents a first step toward fully automated minimally-invasive prostate enucleation.
Investigating Robot Control Policy Learning for Autonomous X-ray-guided Spine Procedures
Nov 05, 2025Imitation learning-based robot control policies are enjoying renewed interest in video-based robotics. However, it remains unclear whether this approach applies to X-ray-guided procedures, such as spine instrumentation. This is because interpretation of multi-view X-rays is complex. We examine opportunities and challenges for imitation policy learning in bi-plane-guided cannula insertion. We develop an in silico sandbox for scalable, automated simulation of X-ray-guided spine procedures with a high degree of realism. We curate a dataset of correct trajectories and corresponding bi-planar X-ray sequences that emulate the stepwise alignment of providers. We then train imitation learning policies for planning and open-loop control that iteratively align a cannula solely based on visual information. This precisely controlled setup offers insights into limitations and capabilities of this method. Our policy succeeded on the first attempt in 68.5% of cases, maintaining safe intra-pedicular trajectories across diverse vertebral levels. The policy generalized to complex anatomy, including fractures, and remained robust to varied initializations. Rollouts on real bi-planar X-rays further suggest that the model can produce plausible trajectories, despite training exclusively in simulation. While these preliminary results are promising, we also identify limitations, especially in entry point precision. Full closed-look control will require additional considerations around how to provide sufficiently frequent feedback. With more robust priors and domain knowledge, such models may provide a foundation for future efforts toward lightweight and CT-free robotic intra-operative spinal navigation.
Autonomous Soft Robotic Guidewire Navigation via Imitation Learning
Oct 10, 2025In endovascular surgery, endovascular interventionists push a thin tube called a catheter, guided by a thin wire to a treatment site inside the patient's blood vessels to treat various conditions such as blood clots, aneurysms, and malformations. Guidewires with robotic tips can enhance maneuverability, but they present challenges in modeling and control. Automation of soft robotic guidewire navigation has the potential to overcome these challenges, increasing the precision and safety of endovascular navigation. In other surgical domains, end-to-end imitation learning has shown promising results. Thus, we develop a transformer-based imitation learning framework with goal conditioning, relative action outputs, and automatic contrast dye injections to enable generalizable soft robotic guidewire navigation in an aneurysm targeting task. We train the model on 36 different modular bifurcated geometries, generating 647 total demonstrations under simulated fluoroscopy, and evaluate it on three previously unseen vascular geometries. The model can autonomously drive the tip of the robot to the aneurysm location with a success rate of 83% on the unseen geometries, outperforming several baselines. In addition, we present ablation and baseline studies to evaluate the effectiveness of each design and data collection choice. Project website: https://softrobotnavigation.github.io/
SRT-H: A Hierarchical Framework for Autonomous Surgery via Language Conditioned Imitation Learning
May 15, 2025Research on autonomous robotic surgery has largely focused on simple task automation in controlled environments. However, real-world surgical applications require dexterous manipulation over extended time scales while demanding generalization across diverse variations in human tissue. These challenges remain difficult to address using existing logic-based or conventional end-to-end learning strategies. To bridge this gap, we propose a hierarchical framework for dexterous, long-horizon surgical tasks. Our method employs a high-level policy for task planning and a low-level policy for generating task-space controls for the surgical robot. The high-level planner plans tasks using language, producing task-specific or corrective instructions that guide the robot at a coarse level. Leveraging language as a planning modality offers an intuitive and generalizable interface, mirroring how experienced surgeons instruct traineers during procedures. We validate our framework in ex-vivo experiments on a complex minimally invasive procedure, cholecystectomy, and conduct ablative studies to assess key design choices. Our approach achieves a 100% success rate across n=8 different ex-vivo gallbladders, operating fully autonomously without human intervention. The hierarchical approach greatly improves the policy's ability to recover from suboptimal states that are inevitable in the highly dynamic environment of realistic surgical applications. This work represents the first demonstration of step-level autonomy, marking a critical milestone toward autonomous surgical systems for clinical studies. By advancing generalizable autonomy in surgical robotics, our approach brings the field closer to real-world deployment.
From Monocular Vision to Autonomous Action: Guiding Tumor Resection via 3D Reconstruction
Mar 20, 2025Surgical automation requires precise guidance and understanding of the scene. Current methods in the literature rely on bulky depth cameras to create maps of the anatomy, however this does not translate well to space-limited clinical applications. Monocular cameras are small and allow minimally invasive surgeries in tight spaces but additional processing is required to generate 3D scene understanding. We propose a 3D mapping pipeline that uses only RGB images to create segmented point clouds of the target anatomy. To ensure the most precise reconstruction, we compare different structure from motion algorithms' performance on mapping the central airway obstructions, and test the pipeline on a downstream task of tumor resection. In several metrics, including post-procedure tissue model evaluation, our pipeline performs comparably to RGB-D cameras and, in some cases, even surpasses their performance. These promising results demonstrate that automation guidance can be achieved in minimally invasive procedures with monocular cameras. This study is a step toward the complete autonomy of surgical robots.
Robotic Ultrasound-Guided Femoral Artery Reconstruction of Anatomically-Representative Phantoms
Mar 09, 2025Femoral artery access is essential for numerous clinical procedures, including diagnostic angiography, therapeutic catheterization, and emergency interventions. Despite its critical role, successful vascular access remains challenging due to anatomical variability, overlying adipose tissue, and the need for precise ultrasound (US) guidance. Errors in needle placement can lead to severe complications, restricting the procedure to highly skilled clinicians in controlled hospital settings. While robotic systems have shown promise in addressing these challenges through autonomous scanning and vessel reconstruction, clinical translation remains limited due to reliance on simplified phantom models that fail to capture human anatomical complexity. In this work, we present a method for autonomous robotic US scanning of bifurcated femoral arteries, and validate it on five vascular phantoms created from real patient computed tomography (CT) data. Additionally, we introduce a video-based deep learning US segmentation network tailored for vascular imaging, enabling improved 3D arterial reconstruction. The proposed network achieves a Dice score of 89.21% and an Intersection over Union of 80.54% on a newly developed vascular dataset. The quality of the reconstructed artery centerline is evaluated against ground truth CT data, demonstrating an average L2 deviation of 0.91+/-0.70 mm, with an average Hausdorff distance of 4.36+/-1.11mm. This study is the first to validate an autonomous robotic system for US scanning of the femoral artery on a diverse set of patient-specific phantoms, introducing a more advanced framework for evaluating robotic performance in vascular imaging and intervention.
Surgical Gaussian Surfels: Highly Accurate Real-time Surgical Scene Rendering
Mar 06, 2025
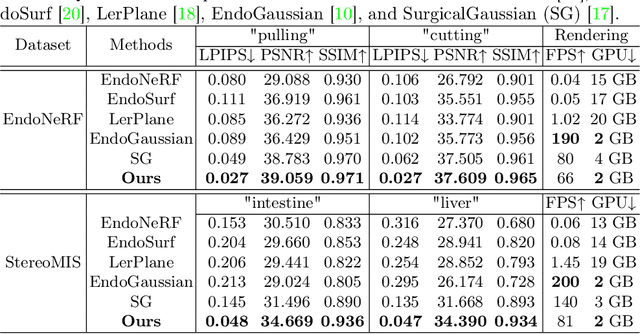

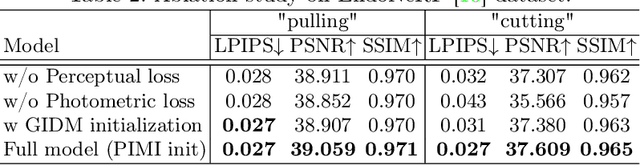
Accurate geometric reconstruction of deformable tissues in monocular endoscopic video remains a fundamental challenge in robot-assisted minimally invasive surgery. Although recent volumetric and point primitive methods based on neural radiance fields (NeRF) and 3D Gaussian primitives have efficiently rendered surgical scenes, they still struggle with handling artifact-free tool occlusions and preserving fine anatomical details. These limitations stem from unrestricted Gaussian scaling and insufficient surface alignment constraints during reconstruction. To address these issues, we introduce Surgical Gaussian Surfels (SGS), which transforms anisotropic point primitives into surface-aligned elliptical splats by constraining the scale component of the Gaussian covariance matrix along the view-aligned axis. We predict accurate surfel motion fields using a lightweight Multi-Layer Perceptron (MLP) coupled with locality constraints to handle complex tissue deformations. We use homodirectional view-space positional gradients to capture fine image details by splitting Gaussian Surfels in over-reconstructed regions. In addition, we define surface normals as the direction of the steepest density change within each Gaussian surfel primitive, enabling accurate normal estimation without requiring monocular normal priors. We evaluate our method on two in-vivo surgical datasets, where it outperforms current state-of-the-art methods in surface geometry, normal map quality, and rendering efficiency, while remaining competitive in real-time rendering performance. We make our code available at https://github.com/aloma85/SurgicalGaussianSurfels
Towards Fluorescence-Guided Autonomous Robotic Partial Nephrectomy on Novel Tissue-Mimicking Hydrogel Phantoms
Mar 04, 2025Autonomous robotic systems hold potential for improving renal tumor resection accuracy and patient outcomes. We present a fluorescence-guided robotic system capable of planning and executing incision paths around exophytic renal tumors with a clinically relevant resection margin. Leveraging point cloud observations, the system handles irregular tumor shapes and distinguishes healthy from tumorous tissue based on near-infrared imaging, akin to indocyanine green staining in partial nephrectomy. Tissue-mimicking phantoms are crucial for the development of autonomous robotic surgical systems for interventions where acquiring ex-vivo animal tissue is infeasible, such as cancer of the kidney and renal pelvis. To this end, we propose novel hydrogel-based kidney phantoms with exophytic tumors that mimic the physical and visual behavior of tissue, and are compatible with electrosurgical instruments, a common limitation of silicone-based phantoms. In contrast to previous hydrogel phantoms, we mix the material with near-infrared dye to enable fluorescence-guided tumor segmentation. Autonomous real-world robotic experiments validate our system and phantoms, achieving an average margin accuracy of 1.44 mm in a completion time of 69 sec.