 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeULF-Loc: Unbiased Landmark Feature for Robust Visual Localization with 3D Gaussian Splatting
May 06, 2026Visual localization is a core technology for augmented reality and autonomous navigation. Recent methods combine the efficient rendering of 3D Gaussian Splatting (3DGS) with feature-based localization. These methods rely on direct matching between 2D query features and the 3D Gaussian feature field, but this often results in mismatches due to an inherent bias in the learned Gaussian feature. We theoretically analyze the feature learning process in 3DGS, revealing that the widely adopted $α$-blending optimization inherently introduces bias into 3D point features. This bias stems from the entanglement between individual Gaussians and their neighboring Gaussians, making the learned features unsuitable for precise matching tasks. Motivated by these findings, we propose ULF-Loc, an unbiased landmark feature framework that replaces biased feature optimization with geometry-weighted feature fusion. We further introduce keypoint-consensus landmark sampling to select reliable Gaussians and local geometric consistency verification to reject mismatches caused by rendering artifacts. On the Cambridge Landmarks dataset, ULF-Loc reduces the mean median translation error by 17\% compared to the state-of-the-art, while achieving superior efficiency with only 1/10 the training time and 1/6 the GPU memory of STDLoc.
RoboRouter: Training-Free Policy Routing for Robotic Manipulation
Mar 12, 2026Research on robotic manipulation has developed a diverse set of policy paradigms, including vision-language-action (VLA) models, vision-action (VA) policies, and code-based compositional approaches. Concrete policies typically attain high success rates on specific task distributions but lim-ited generalization beyond it. Rather than proposing an other monolithic policy, we propose to leverage the complementary strengths of existing approaches through intelligent policy routing. We introduce RoboRouter, a training-free framework that maintains a pool of heterogeneous policies and learns to select the best-performing policy for each task through accumulated execution experience. Given a new task, RoboRouter constructs a semantic task representation, retrieves historical records of similar tasks, predicts the optimal policy choice without requiring trial-and-error, and incorporates structured feedback to refine subsequent routing decisions. Integrating a new policy into the system requires only lightweight evaluation and incurs no training overhead. Across simulation benchmark and real-world evaluations, RoboRouter consistently outperforms than in-dividual policies, improving average success rate by more than 3% in simulation and over 13% in real-world settings, while preserving execution efficiency. Our results demonstrate that intelligent routing across heterogeneous, off-the-shelf policies provides a practical and scalable pathway toward building more capable robotic systems.
Dream-SLAM: Dreaming the Unseen for Active SLAM in Dynamic Environments
Feb 25, 2026In addition to the core tasks of simultaneous localization and mapping (SLAM), active SLAM additionally in- volves generating robot actions that enable effective and efficient exploration of unknown environments. However, existing active SLAM pipelines are limited by three main factors. First, they inherit the restrictions of the underlying SLAM modules that they may be using. Second, their motion planning strategies are typically shortsighted and lack long-term vision. Third, most approaches struggle to handle dynamic scenes. To address these limitations, we propose a novel monocular active SLAM method, Dream-SLAM, which is based on dreaming cross-spatio-temporal images and semantically plausible structures of partially observed dynamic environments. The generated cross-spatio-temporal im- ages are fused with real observations to mitigate noise and data incompleteness, leading to more accurate camera pose estimation and a more coherent 3D scene representation. Furthermore, we integrate dreamed and observed scene structures to enable long- horizon planning, producing farsighted trajectories that promote efficient and thorough exploration. Extensive experiments on both public and self-collected datasets demonstrate that Dream-SLAM outperforms state-of-the-art methods in localization accuracy, mapping quality, and exploration efficiency. Source code will be publicly available upon paper acceptance.
Advances in Global Solvers for 3D Vision
Feb 16, 2026Global solvers have emerged as a powerful paradigm for 3D vision, offering certifiable solutions to nonconvex geometric optimization problems traditionally addressed by local or heuristic methods. This survey presents the first systematic review of global solvers in geometric vision, unifying the field through a comprehensive taxonomy of three core paradigms: Branch-and-Bound (BnB), Convex Relaxation (CR), and Graduated Non-Convexity (GNC). We present their theoretical foundations, algorithmic designs, and practical enhancements for robustness and scalability, examining how each addresses the fundamental nonconvexity of geometric estimation problems. Our analysis spans ten core vision tasks, from Wahba problem to bundle adjustment, revealing the optimality-robustness-scalability trade-offs that govern solver selection. We identify critical future directions: scaling algorithms while maintaining guarantees, integrating data-driven priors with certifiable optimization, establishing standardized benchmarks, and addressing societal implications for safety-critical deployment. By consolidating theoretical foundations, practical advances, and broader impacts, this survey provides a unified perspective and roadmap toward certifiable, trustworthy perception for real-world applications. A continuously-updated literature summary and companion code tutorials are available at https://github.com/ericzzj1989/Awesome-Global-Solvers-for-3D-Vision.
Neural Predictor-Corrector: Solving Homotopy Problems with Reinforcement Learning
Feb 03, 2026The Homotopy paradigm, a general principle for solving challenging problems, appears across diverse domains such as robust optimization, global optimization, polynomial root-finding, and sampling. Practical solvers for these problems typically follow a predictor-corrector (PC) structure, but rely on hand-crafted heuristics for step sizes and iteration termination, which are often suboptimal and task-specific. To address this, we unify these problems under a single framework, which enables the design of a general neural solver. Building on this unified view, we propose Neural Predictor-Corrector (NPC), which replaces hand-crafted heuristics with automatically learned policies. NPC formulates policy selection as a sequential decision-making problem and leverages reinforcement learning to automatically discover efficient strategies. To further enhance generalization, we introduce an amortized training mechanism, enabling one-time offline training for a class of problems and efficient online inference on new instances. Experiments on four representative homotopy problems demonstrate that our method generalizes effectively to unseen instances. It consistently outperforms classical and specialized baselines in efficiency while demonstrating superior stability across tasks, highlighting the value of unifying homotopy methods into a single neural framework.
AdaGaR: Adaptive Gabor Representation for Dynamic Scene Reconstruction
Jan 02, 2026Reconstructing dynamic 3D scenes from monocular videos requires simultaneously capturing high-frequency appearance details and temporally continuous motion. Existing methods using single Gaussian primitives are limited by their low-pass filtering nature, while standard Gabor functions introduce energy instability. Moreover, lack of temporal continuity constraints often leads to motion artifacts during interpolation. We propose AdaGaR, a unified framework addressing both frequency adaptivity and temporal continuity in explicit dynamic scene modeling. We introduce Adaptive Gabor Representation, extending Gaussians through learnable frequency weights and adaptive energy compensation to balance detail capture and stability. For temporal continuity, we employ Cubic Hermite Splines with Temporal Curvature Regularization to ensure smooth motion evolution. An Adaptive Initialization mechanism combining depth estimation, point tracking, and foreground masks establishes stable point cloud distributions in early training. Experiments on Tap-Vid DAVIS demonstrate state-of-the-art performance (PSNR 35.49, SSIM 0.9433, LPIPS 0.0723) and strong generalization across frame interpolation, depth consistency, video editing, and stereo view synthesis. Project page: https://jiewenchan.github.io/AdaGaR/
TurboReg: TurboClique for Robust and Efficient Point Cloud Registration
Jul 02, 2025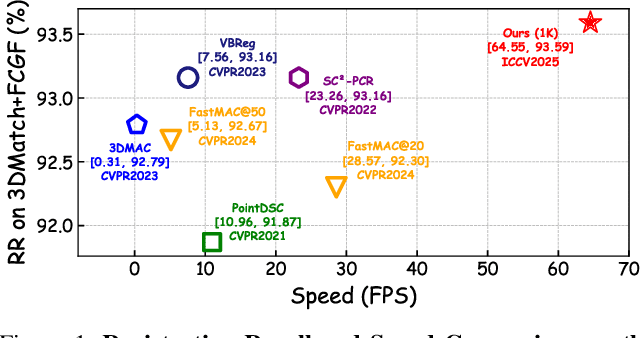
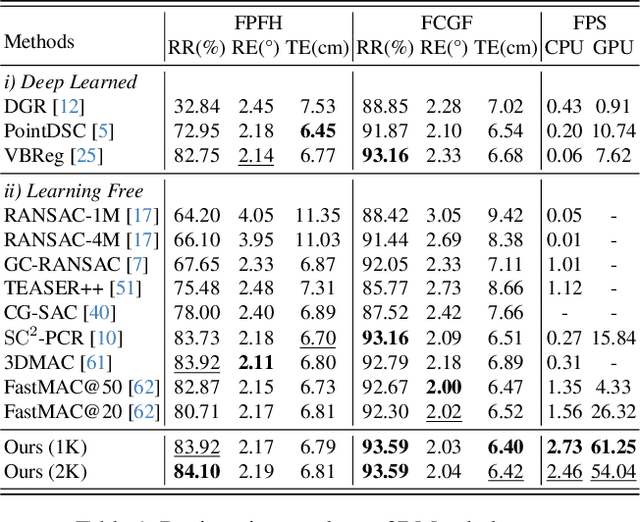


Robust estimation is essential in correspondence-based Point Cloud Registration (PCR). Existing methods using maximal clique search in compatibility graphs achieve high recall but suffer from exponential time complexity, limiting their use in time-sensitive applications. To address this challenge, we propose a fast and robust estimator, TurboReg, built upon a novel lightweight clique, TurboClique, and a highly parallelizable Pivot-Guided Search (PGS) algorithm. First, we define the TurboClique as a 3-clique within a highly-constrained compatibility graph. The lightweight nature of the 3-clique allows for efficient parallel searching, and the highly-constrained compatibility graph ensures robust spatial consistency for stable transformation estimation. Next, PGS selects matching pairs with high SC$^2$ scores as pivots, effectively guiding the search toward TurboCliques with higher inlier ratios. Moreover, the PGS algorithm has linear time complexity and is significantly more efficient than the maximal clique search with exponential time complexity. Extensive experiments show that TurboReg achieves state-of-the-art performance across multiple real-world datasets, with substantial speed improvements. For example, on the 3DMatch+FCGF dataset, TurboReg (1K) operates $208.22\times$ faster than 3DMAC while also achieving higher recall. Our code is accessible at \href{https://github.com/Laka-3DV/TurboReg}{\texttt{TurboReg}}.
Convex Relaxation for Robust Vanishing Point Estimation in Manhattan World
May 07, 2025



Determining the vanishing points (VPs) in a Manhattan world, as a fundamental task in many 3D vision applications, consists of jointly inferring the line-VP association and locating each VP. Existing methods are, however, either sub-optimal solvers or pursuing global optimality at a significant cost of computing time. In contrast to prior works, we introduce convex relaxation techniques to solve this task for the first time. Specifically, we employ a ``soft'' association scheme, realized via a truncated multi-selection error, that allows for joint estimation of VPs' locations and line-VP associations. This approach leads to a primal problem that can be reformulated into a quadratically constrained quadratic programming (QCQP) problem, which is then relaxed into a convex semidefinite programming (SDP) problem. To solve this SDP problem efficiently, we present a globally optimal outlier-robust iterative solver (called \textbf{GlobustVP}), which independently searches for one VP and its associated lines in each iteration, treating other lines as outliers. After each independent update of all VPs, the mutual orthogonality between the three VPs in a Manhattan world is reinforced via local refinement. Extensive experiments on both synthetic and real-world data demonstrate that \textbf{GlobustVP} achieves a favorable balance between efficiency, robustness, and global optimality compared to previous works. The code is publicly available at https://github.com/WU-CVGL/GlobustVP.
Surgical Gaussian Surfels: Highly Accurate Real-time Surgical Scene Rendering
Mar 06, 2025
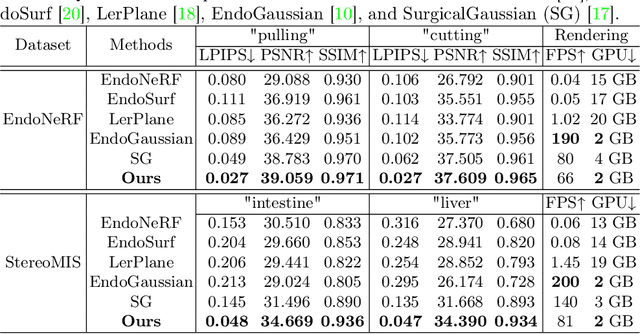

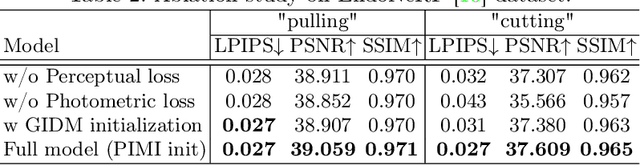
Accurate geometric reconstruction of deformable tissues in monocular endoscopic video remains a fundamental challenge in robot-assisted minimally invasive surgery. Although recent volumetric and point primitive methods based on neural radiance fields (NeRF) and 3D Gaussian primitives have efficiently rendered surgical scenes, they still struggle with handling artifact-free tool occlusions and preserving fine anatomical details. These limitations stem from unrestricted Gaussian scaling and insufficient surface alignment constraints during reconstruction. To address these issues, we introduce Surgical Gaussian Surfels (SGS), which transforms anisotropic point primitives into surface-aligned elliptical splats by constraining the scale component of the Gaussian covariance matrix along the view-aligned axis. We predict accurate surfel motion fields using a lightweight Multi-Layer Perceptron (MLP) coupled with locality constraints to handle complex tissue deformations. We use homodirectional view-space positional gradients to capture fine image details by splitting Gaussian Surfels in over-reconstructed regions. In addition, we define surface normals as the direction of the steepest density change within each Gaussian surfel primitive, enabling accurate normal estimation without requiring monocular normal priors. We evaluate our method on two in-vivo surgical datasets, where it outperforms current state-of-the-art methods in surface geometry, normal map quality, and rendering efficiency, while remaining competitive in real-time rendering performance. We make our code available at https://github.com/aloma85/SurgicalGaussianSurfels
Image Matching Filtering and Refinement by Planes and Beyond
Nov 14, 2024



This paper introduces a modular, non-deep learning method for filtering and refining sparse correspondences in image matching. Assuming that motion flow within the scene can be approximated by local homography transformations, matches are aggregated into overlapping clusters corresponding to virtual planes using an iterative RANSAC-based approach, with non-conforming correspondences discarded. Moreover, the underlying planar structural design provides an explicit map between local patches associated with the matches, enabling optional refinement of keypoint positions through cross-correlation template matching after patch reprojection. Finally, to enhance robustness and fault-tolerance against violations of the piece-wise planar approximation assumption, a further strategy is designed for minimizing relative patch distortion in the plane reprojection by introducing an intermediate homography that projects both patches into a common plane. The proposed method is extensively evaluated on standard datasets and image matching pipelines, and compared with state-of-the-art approaches. Unlike other current comparisons, the proposed benchmark also takes into account the more general, real, and practical cases where camera intrinsics are unavailable. Experimental results demonstrate that our proposed non-deep learning, geometry-based approach achieves performances that are either superior to or on par with recent state-of-the-art deep learning methods. Finally, this study suggests that there are still development potential in actual image matching solutions in the considered research direction, which could be in the future incorporated in novel deep image matching architectures.