 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA-TDOM: Active TDOM via On-the-Fly 3DGS
Sep 16, 2025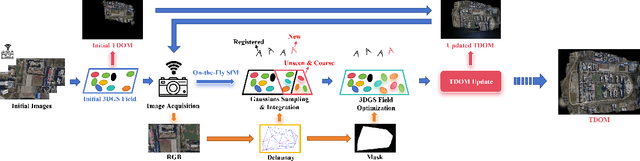
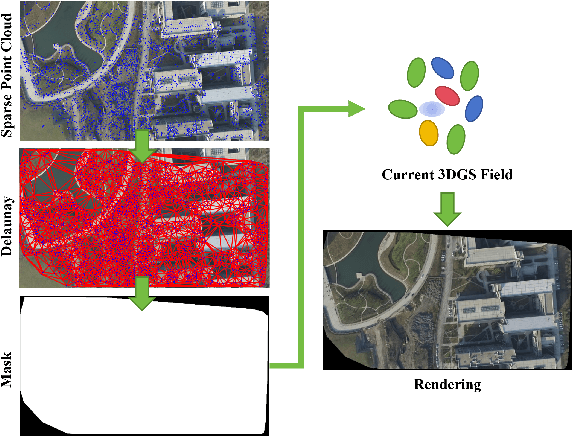
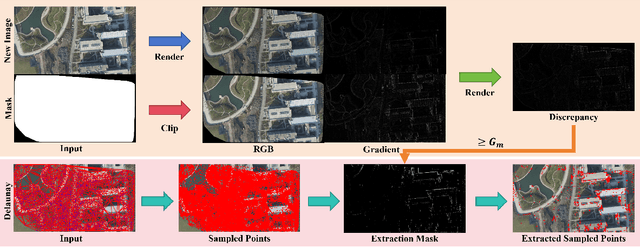
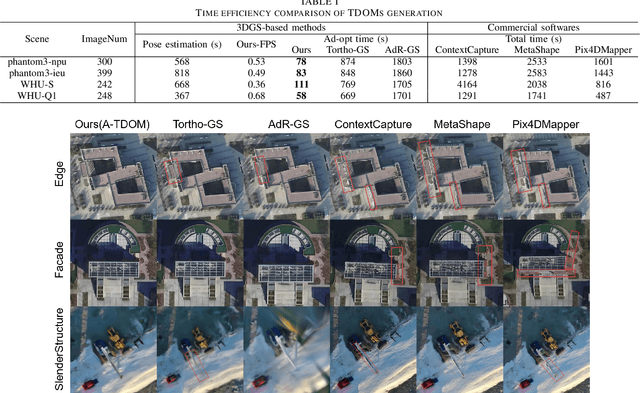
True Digital Orthophoto Map (TDOM) serves as a crucial geospatial product in various fields such as urban management, city planning, land surveying, etc. However, traditional TDOM generation methods generally rely on a complex offline photogrammetric pipeline, resulting in delays that hinder real-time applications. Moreover, the quality of TDOM may degrade due to various challenges, such as inaccurate camera poses or Digital Surface Model (DSM) and scene occlusions. To address these challenges, this work introduces A-TDOM, a near real-time TDOM generation method based on On-the-Fly 3DGS optimization. As each image is acquired, its pose and sparse point cloud are computed via On-the-Fly SfM. Then new Gaussians are integrated and optimized into previously unseen or coarsely reconstructed regions. By integrating with orthogonal splatting, A-TDOM can render just after each update of a new 3DGS field. Initial experiments on multiple benchmarks show that the proposed A-TDOM is capable of actively rendering TDOM in near real-time, with 3DGS optimization for each new image in seconds while maintaining acceptable rendering quality and TDOM geometric accuracy.
Multispectral LiDAR data for extracting tree points in urban and suburban areas
Aug 27, 2025Monitoring urban tree dynamics is vital for supporting greening policies and reducing risks to electrical infrastructure. Airborne laser scanning has advanced large-scale tree management, but challenges remain due to complex urban environments and tree variability. Multispectral (MS) light detection and ranging (LiDAR) improves this by capturing both 3D spatial and spectral data, enabling detailed mapping. This study explores tree point extraction using MS-LiDAR and deep learning (DL) models. Three state-of-the-art models are evaluated: Superpoint Transformer (SPT), Point Transformer V3 (PTv3), and Point Transformer V1 (PTv1). Results show the notable time efficiency and accuracy of SPT, with a mean intersection over union (mIoU) of 85.28%. The highest detection accuracy is achieved by incorporating pseudo normalized difference vegetation index (pNDVI) with spatial data, reducing error rate by 10.61 percentage points (pp) compared to using spatial information alone. These findings highlight the potential of MS-LiDAR and DL to improve tree extraction and further tree inventories.
Multispectral airborne laser scanning for tree species classification: a benchmark of machine learning and deep learning algorithms
Apr 19, 2025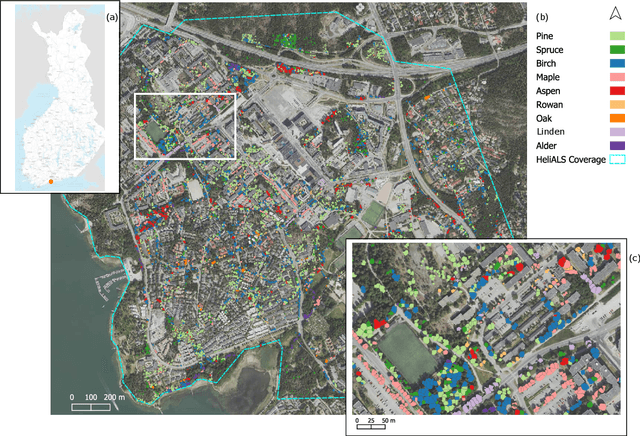


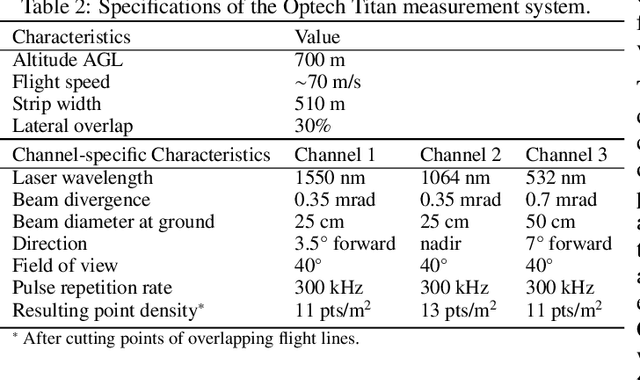
Climate-smart and biodiversity-preserving forestry demands precise information on forest resources, extending to the individual tree level. Multispectral airborne laser scanning (ALS) has shown promise in automated point cloud processing and tree segmentation, but challenges remain in identifying rare tree species and leveraging deep learning techniques. This study addresses these gaps by conducting a comprehensive benchmark of machine learning and deep learning methods for tree species classification. For the study, we collected high-density multispectral ALS data (>1000 pts/m$^2$) at three wavelengths using the FGI-developed HeliALS system, complemented by existing Optech Titan data (35 pts/m$^2$), to evaluate the species classification accuracy of various algorithms in a test site located in Southern Finland. Based on 5261 test segments, our findings demonstrate that point-based deep learning methods, particularly a point transformer model, outperformed traditional machine learning and image-based deep learning approaches on high-density multispectral point clouds. For the high-density ALS dataset, a point transformer model provided the best performance reaching an overall (macro-average) accuracy of 87.9% (74.5%) with a training set of 1065 segments and 92.0% (85.1%) with 5000 training segments. The best image-based deep learning method, DetailView, reached an overall (macro-average) accuracy of 84.3% (63.9%), whereas a random forest (RF) classifier achieved an overall (macro-average) accuracy of 83.2% (61.3%). Importantly, the overall classification accuracy of the point transformer model on the HeliALS data increased from 73.0% with no spectral information to 84.7% with single-channel reflectance, and to 87.9% with spectral information of all the three channels.
3DSceneEditor: Controllable 3D Scene Editing with Gaussian Splatting
Dec 02, 2024
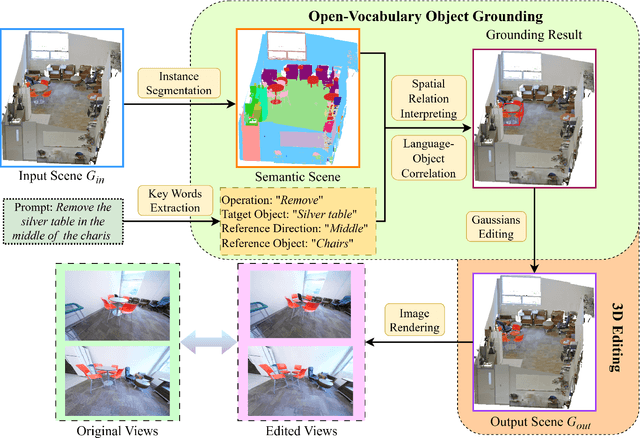


The creation of 3D scenes has traditionally been both labor-intensive and costly, requiring designers to meticulously configure 3D assets and environments. Recent advancements in generative AI, including text-to-3D and image-to-3D methods, have dramatically reduced the complexity and cost of this process. However, current techniques for editing complex 3D scenes continue to rely on generally interactive multi-step, 2D-to-3D projection methods and diffusion-based techniques, which often lack precision in control and hamper real-time performance. In this work, we propose 3DSceneEditor, a fully 3D-based paradigm for real-time, precise editing of intricate 3D scenes using Gaussian Splatting. Unlike conventional methods, 3DSceneEditor operates through a streamlined 3D pipeline, enabling direct manipulation of Gaussians for efficient, high-quality edits based on input prompts.The proposed framework (i) integrates a pre-trained instance segmentation model for semantic labeling; (ii) employs a zero-shot grounding approach with CLIP to align target objects with user prompts; and (iii) applies scene modifications, such as object addition, repositioning, recoloring, replacing, and deletion directly on Gaussians. Extensive experimental results show that 3DSceneEditor achieves superior editing precision and speed with respect to current SOTA 3D scene editing approaches, establishing a new benchmark for efficient and interactive 3D scene customization.
Image Matching Filtering and Refinement by Planes and Beyond
Nov 14, 2024



This paper introduces a modular, non-deep learning method for filtering and refining sparse correspondences in image matching. Assuming that motion flow within the scene can be approximated by local homography transformations, matches are aggregated into overlapping clusters corresponding to virtual planes using an iterative RANSAC-based approach, with non-conforming correspondences discarded. Moreover, the underlying planar structural design provides an explicit map between local patches associated with the matches, enabling optional refinement of keypoint positions through cross-correlation template matching after patch reprojection. Finally, to enhance robustness and fault-tolerance against violations of the piece-wise planar approximation assumption, a further strategy is designed for minimizing relative patch distortion in the plane reprojection by introducing an intermediate homography that projects both patches into a common plane. The proposed method is extensively evaluated on standard datasets and image matching pipelines, and compared with state-of-the-art approaches. Unlike other current comparisons, the proposed benchmark also takes into account the more general, real, and practical cases where camera intrinsics are unavailable. Experimental results demonstrate that our proposed non-deep learning, geometry-based approach achieves performances that are either superior to or on par with recent state-of-the-art deep learning methods. Finally, this study suggests that there are still development potential in actual image matching solutions in the considered research direction, which could be in the future incorporated in novel deep image matching architectures.
Exploring the potential of collaborative UAV 3D mapping in Kenyan savanna for wildlife research
Sep 24, 2024



UAV-based biodiversity conservation applications have exhibited many data acquisition advantages for researchers. UAV platforms with embedded data processing hardware can support conservation challenges through 3D habitat mapping, surveillance and monitoring solutions. High-quality real-time scene reconstruction as well as real-time UAV localization can optimize the exploration vs exploitation balance of single or collaborative mission. In this work, we explore the potential of two collaborative frameworks - Visual Simultaneous Localization and Mapping (V-SLAM) and Structure-from-Motion (SfM) for 3D mapping purposes and compare results with standard offline approaches.
RenderWorld: World Model with Self-Supervised 3D Label
Sep 17, 2024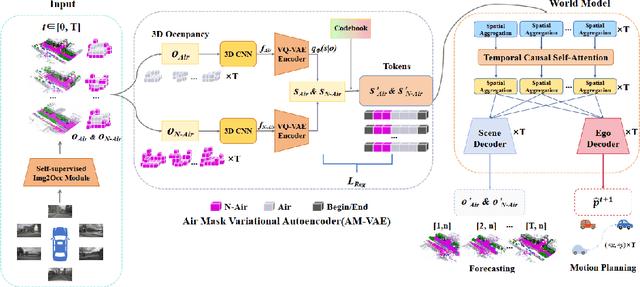
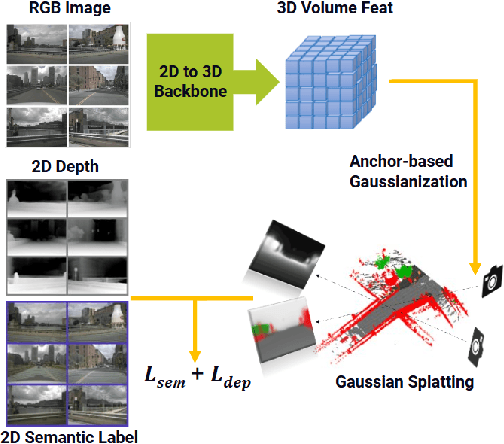
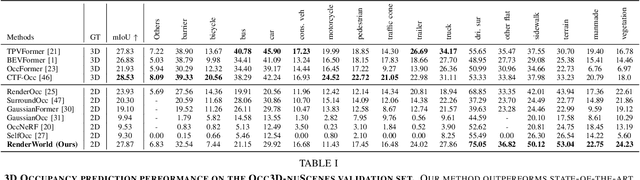

End-to-end autonomous driving with vision-only is not only more cost-effective compared to LiDAR-vision fusion but also more reliable than traditional methods. To achieve a economical and robust purely visual autonomous driving system, we propose RenderWorld, a vision-only end-to-end autonomous driving framework, which generates 3D occupancy labels using a self-supervised gaussian-based Img2Occ Module, then encodes the labels by AM-VAE, and uses world model for forecasting and planning. RenderWorld employs Gaussian Splatting to represent 3D scenes and render 2D images greatly improves segmentation accuracy and reduces GPU memory consumption compared with NeRF-based methods. By applying AM-VAE to encode air and non-air separately, RenderWorld achieves more fine-grained scene element representation, leading to state-of-the-art performance in both 4D occupancy forecasting and motion planning from autoregressive world model.
Deep Learning Meets Satellite Images -- An Evaluation on Handcrafted and Learning-based Features for Multi-date Satellite Stereo Images
Sep 04, 2024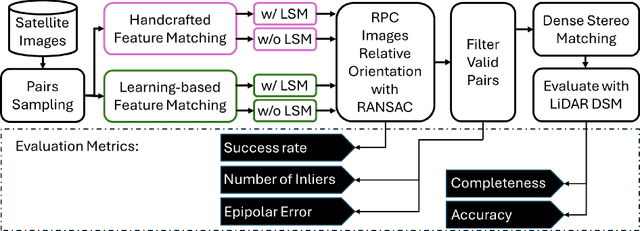
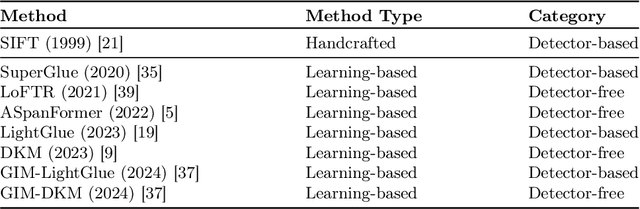
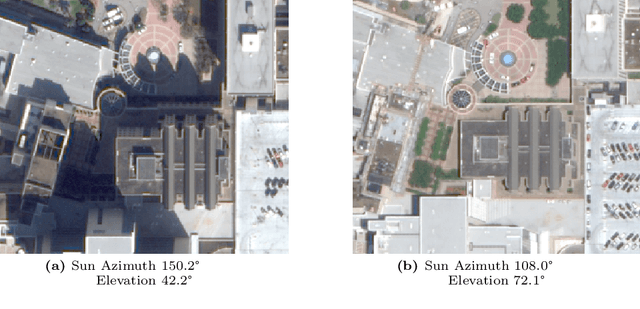

A critical step in the digital surface models(DSM) generation is feature matching. Off-track (or multi-date) satellite stereo images, in particular, can challenge the performance of feature matching due to spectral distortions between images, long baseline, and wide intersection angles. Feature matching methods have evolved over the years from handcrafted methods (e.g., SIFT) to learning-based methods (e.g., SuperPoint and SuperGlue). In this paper, we compare the performance of different features, also known as feature extraction and matching methods, applied to satellite imagery. A wide range of stereo pairs(~500) covering two separate study sites are used. SIFT, as a widely used classic feature extraction and matching algorithm, is compared with seven deep-learning matching methods: SuperGlue, LightGlue, LoFTR, ASpanFormer, DKM, GIM-LightGlue, and GIM-DKM. Results demonstrate that traditional matching methods are still competitive in this age of deep learning, although for particular scenarios learning-based methods are very promising.
Enabling Neural Radiance Fields (NeRF) for Large-scale Aerial Images -- A Multi-tiling Approach and the Geometry Assessment of NeRF
Oct 17, 2023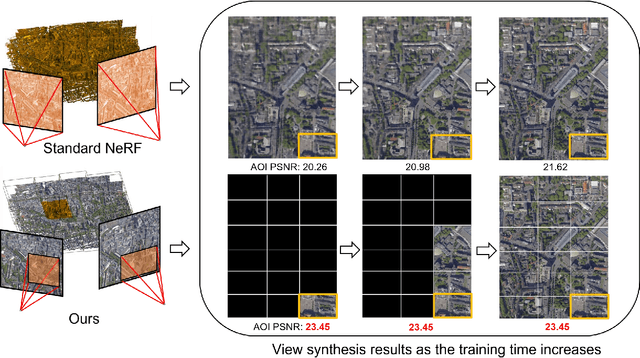
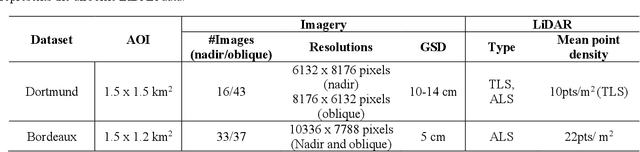


Neural Radiance Fields (NeRF) offer the potential to benefit 3D reconstruction tasks, including aerial photogrammetry. However, the scalability and accuracy of the inferred geometry are not well-documented for large-scale aerial assets,since such datasets usually result in very high memory consumption and slow convergence.. In this paper, we aim to scale the NeRF on large-scael aerial datasets and provide a thorough geometry assessment of NeRF. Specifically, we introduce a location-specific sampling technique as well as a multi-camera tiling (MCT) strategy to reduce memory consumption during image loading for RAM, representation training for GPU memory, and increase the convergence rate within tiles. MCT decomposes a large-frame image into multiple tiled images with different camera models, allowing these small-frame images to be fed into the training process as needed for specific locations without a loss of accuracy. We implement our method on a representative approach, Mip-NeRF, and compare its geometry performance with threephotgrammetric MVS pipelines on two typical aerial datasets against LiDAR reference data. Both qualitative and quantitative results suggest that the proposed NeRF approach produces better completeness and object details than traditional approaches, although as of now, it still falls short in terms of accuracy.
NERFBK: A High-Quality Benchmark for NERF-Based 3D Reconstruction
Jun 15, 2023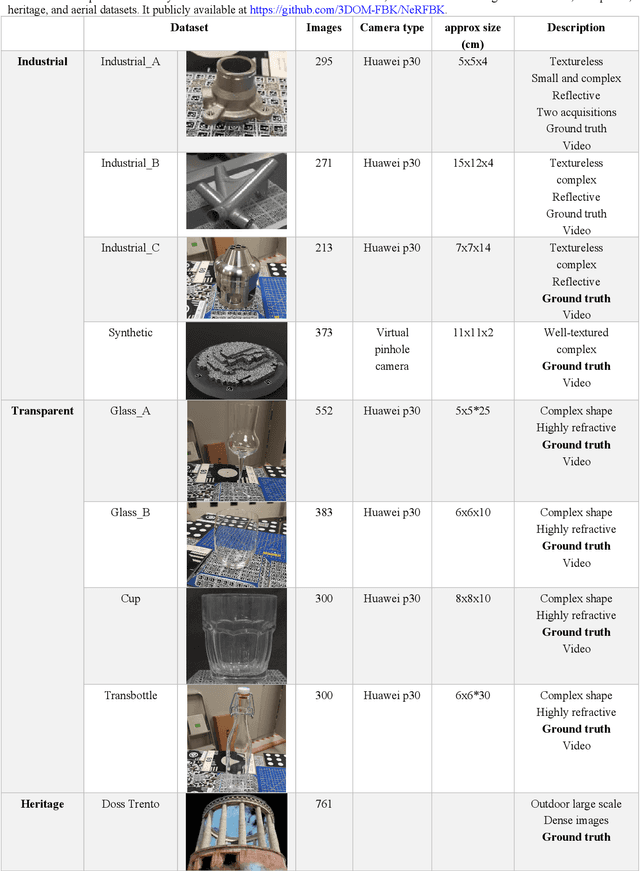
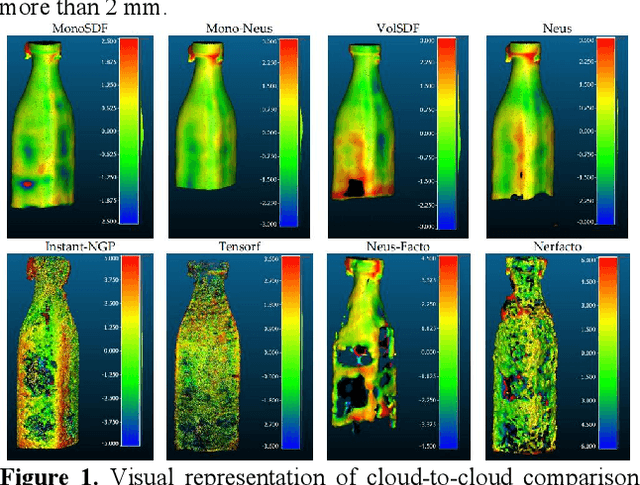
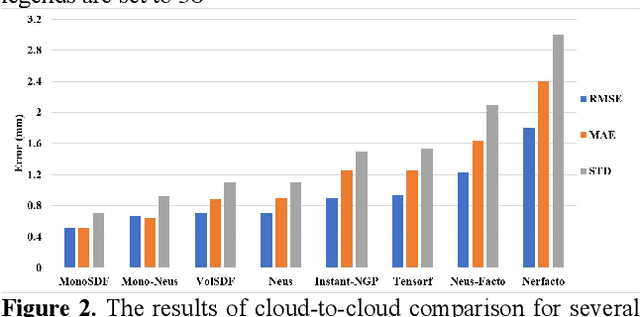
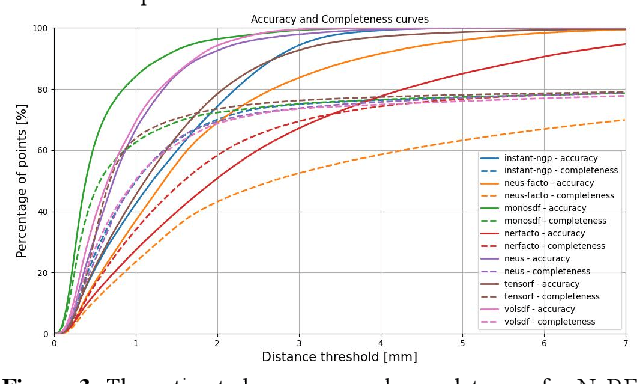
This paper introduces a new real and synthetic dataset called NeRFBK specifically designed for testing and comparing NeRF-based 3D reconstruction algorithms. High-quality 3D reconstruction has significant potential in various fields, and advancements in image-based algorithms make it essential to evaluate new advanced techniques. However, gathering diverse data with precise ground truth is challenging and may not encompass all relevant applications. The NeRFBK dataset addresses this issue by providing multi-scale, indoor and outdoor datasets with high-resolution images and videos and camera parameters for testing and comparing NeRF-based algorithms. This paper presents the design and creation of the NeRFBK benchmark, various examples and application scenarios, and highlights its potential for advancing the field of 3D reconstruction.