 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA-TDOM: Active TDOM via On-the-Fly 3DGS
Sep 16, 2025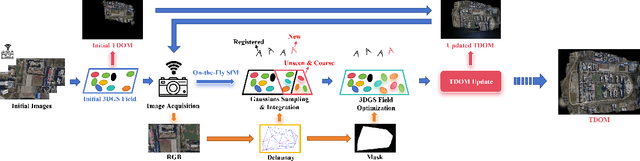
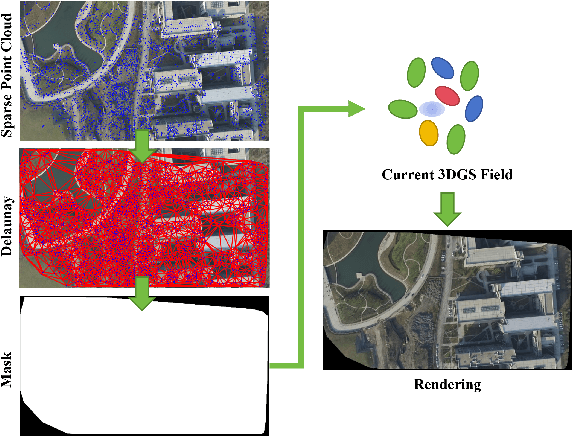
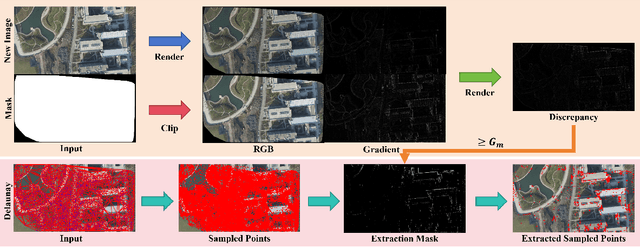
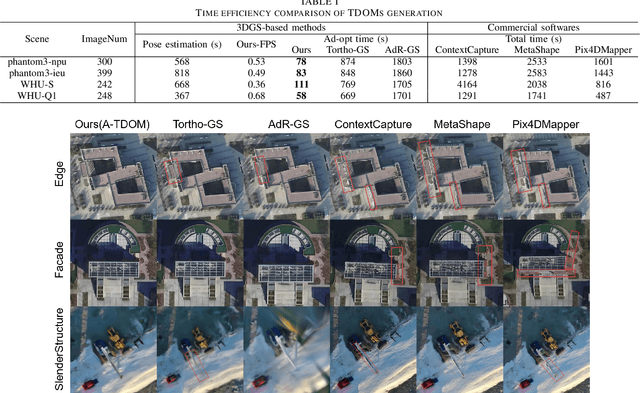
True Digital Orthophoto Map (TDOM) serves as a crucial geospatial product in various fields such as urban management, city planning, land surveying, etc. However, traditional TDOM generation methods generally rely on a complex offline photogrammetric pipeline, resulting in delays that hinder real-time applications. Moreover, the quality of TDOM may degrade due to various challenges, such as inaccurate camera poses or Digital Surface Model (DSM) and scene occlusions. To address these challenges, this work introduces A-TDOM, a near real-time TDOM generation method based on On-the-Fly 3DGS optimization. As each image is acquired, its pose and sparse point cloud are computed via On-the-Fly SfM. Then new Gaussians are integrated and optimized into previously unseen or coarsely reconstructed regions. By integrating with orthogonal splatting, A-TDOM can render just after each update of a new 3DGS field. Initial experiments on multiple benchmarks show that the proposed A-TDOM is capable of actively rendering TDOM in near real-time, with 3DGS optimization for each new image in seconds while maintaining acceptable rendering quality and TDOM geometric accuracy.
Image Matching Filtering and Refinement by Planes and Beyond
Nov 14, 2024



This paper introduces a modular, non-deep learning method for filtering and refining sparse correspondences in image matching. Assuming that motion flow within the scene can be approximated by local homography transformations, matches are aggregated into overlapping clusters corresponding to virtual planes using an iterative RANSAC-based approach, with non-conforming correspondences discarded. Moreover, the underlying planar structural design provides an explicit map between local patches associated with the matches, enabling optional refinement of keypoint positions through cross-correlation template matching after patch reprojection. Finally, to enhance robustness and fault-tolerance against violations of the piece-wise planar approximation assumption, a further strategy is designed for minimizing relative patch distortion in the plane reprojection by introducing an intermediate homography that projects both patches into a common plane. The proposed method is extensively evaluated on standard datasets and image matching pipelines, and compared with state-of-the-art approaches. Unlike other current comparisons, the proposed benchmark also takes into account the more general, real, and practical cases where camera intrinsics are unavailable. Experimental results demonstrate that our proposed non-deep learning, geometry-based approach achieves performances that are either superior to or on par with recent state-of-the-art deep learning methods. Finally, this study suggests that there are still development potential in actual image matching solutions in the considered research direction, which could be in the future incorporated in novel deep image matching architectures.
Exploring the potential of collaborative UAV 3D mapping in Kenyan savanna for wildlife research
Sep 24, 2024



UAV-based biodiversity conservation applications have exhibited many data acquisition advantages for researchers. UAV platforms with embedded data processing hardware can support conservation challenges through 3D habitat mapping, surveillance and monitoring solutions. High-quality real-time scene reconstruction as well as real-time UAV localization can optimize the exploration vs exploitation balance of single or collaborative mission. In this work, we explore the potential of two collaborative frameworks - Visual Simultaneous Localization and Mapping (V-SLAM) and Structure-from-Motion (SfM) for 3D mapping purposes and compare results with standard offline approaches.
Deep Learning Meets Satellite Images -- An Evaluation on Handcrafted and Learning-based Features for Multi-date Satellite Stereo Images
Sep 04, 2024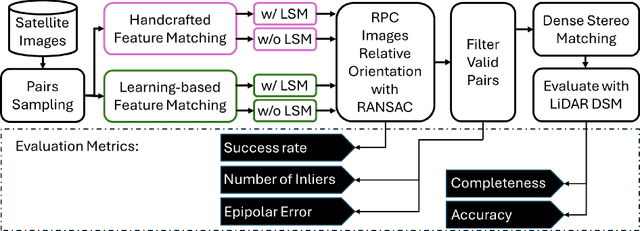
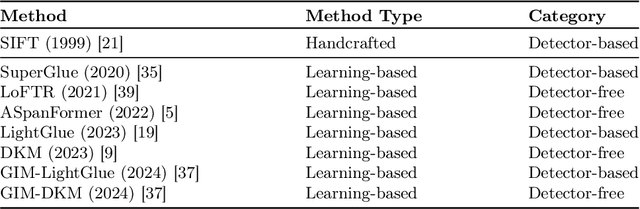

A critical step in the digital surface models(DSM) generation is feature matching. Off-track (or multi-date) satellite stereo images, in particular, can challenge the performance of feature matching due to spectral distortions between images, long baseline, and wide intersection angles. Feature matching methods have evolved over the years from handcrafted methods (e.g., SIFT) to learning-based methods (e.g., SuperPoint and SuperGlue). In this paper, we compare the performance of different features, also known as feature extraction and matching methods, applied to satellite imagery. A wide range of stereo pairs(~500) covering two separate study sites are used. SIFT, as a widely used classic feature extraction and matching algorithm, is compared with seven deep-learning matching methods: SuperGlue, LightGlue, LoFTR, ASpanFormer, DKM, GIM-LightGlue, and GIM-DKM. Results demonstrate that traditional matching methods are still competitive in this age of deep learning, although for particular scenarios learning-based methods are very promising.