 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Matching Filtering and Refinement by Planes and Beyond
Nov 14, 2024



This paper introduces a modular, non-deep learning method for filtering and refining sparse correspondences in image matching. Assuming that motion flow within the scene can be approximated by local homography transformations, matches are aggregated into overlapping clusters corresponding to virtual planes using an iterative RANSAC-based approach, with non-conforming correspondences discarded. Moreover, the underlying planar structural design provides an explicit map between local patches associated with the matches, enabling optional refinement of keypoint positions through cross-correlation template matching after patch reprojection. Finally, to enhance robustness and fault-tolerance against violations of the piece-wise planar approximation assumption, a further strategy is designed for minimizing relative patch distortion in the plane reprojection by introducing an intermediate homography that projects both patches into a common plane. The proposed method is extensively evaluated on standard datasets and image matching pipelines, and compared with state-of-the-art approaches. Unlike other current comparisons, the proposed benchmark also takes into account the more general, real, and practical cases where camera intrinsics are unavailable. Experimental results demonstrate that our proposed non-deep learning, geometry-based approach achieves performances that are either superior to or on par with recent state-of-the-art deep learning methods. Finally, this study suggests that there are still development potential in actual image matching solutions in the considered research direction, which could be in the future incorporated in novel deep image matching architectures.
Image Matching by Bare Homography
May 15, 2023



This paper presents Slime, a novel non-deep image matching framework which models the scene as rough local overlapping planes. This intermediate representation sits in-between the local affine approximation of the keypoint patches and the global matching based on both geometrical and similarity constraints, providing a progressive pruning of the correspondences, as planes are easier to handle with respect to general scenes. Slime proceeds by selectively detect, expand, merge and refine the matches associated to almost-planar areas of the scene by exploiting homography constraints. As a result, both the coverage and stability of correct matches over the scene are amplified, allowing traditional hybrid matching pipelines to make up lost ground against recent end-to-end deep matching methods. In addition, the paper gives a thorough comparative analysis of recent state-of-the-art in image matching represented by end-to-end deep networks and hybrid pipelines. The evaluation considers both planar and non-planar scenes, taking into account critical and challenging scenarios including abrupt temporal image changes and strong variations in relative image rotations. According to this analysis, although the impressive progress done in this field, there is still a wide room for improvements to be investigated in future research.
HarrisZ$^+$: Harris Corner Selection for Next-Gen Image Matching Pipelines
Sep 29, 2021
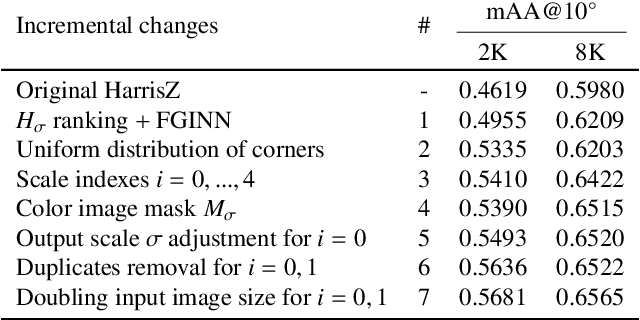


Due to its role in many computer vision tasks, image matching has been subjected to an active investigation by researchers, which has lead to better and more discriminant feature descriptors and to more robust matching strategies, also thanks to the advent of the deep learning and the increased computational power of the modern hardware. Despite of these achievements, the keypoint extraction process at the base of the image matching pipeline has not seen equivalent progresses. This paper presents Harrisz$^{+}$, an upgrade to the HarrisZ corner detector, optimized to synergically take advance of the recent improvements of the other steps of the image matching pipeline. Harrisz$^{+}$ does not only consists of a tuning of the setup parameters, but introduces further refinements to the selection criteria delineated by HarrisZ, so providing more, yet discriminative, keypoints, which are better distributed on the image and with higher localization accuracy. The image matching pipeline including Harrisz$^{+}$, together with the other modern components, obtained in different recent matching benchmarks state-of-the-art results among the classic image matching pipelines, closely following results of the more recent fully deep end-to-end trainable approaches.
SIFT Matching by Context Exposed
Jun 20, 2021



This paper investigates how to step up local image descriptor matching by exploiting matching context information. Two main contexts are identified, originated respectively from the descriptor space and from the keypoint space. The former is generally used to design the actual matching strategy while the latter to filter matches according to the local spatial consistency. On this basis, a new matching strategy and a novel local spatial filter, named respectively blob matching and Delaunay Triangulation Matching (DTM) are devised. Blob matching provides a general matching framework by merging together several strategies, including pre-filtering as well as many-to-many and symmetric matching, enabling to achieve a global improvement upon each individual strategy. DTM alternates between Delaunay triangulation contractions and expansions to figure out and adjust keypoint neighborhood consistency. Experimental evaluation shows that DTM is comparable or better than the state-of-the-art in terms of matching accuracy and robustness, especially for non-planar scenes. Evaluation is carried out according to a new benchmark devised for analyzing the matching pipeline in terms of correct correspondences on both planar and non-planar scenes, including state-of-the-art methods as well as the common SIFT matching approach for reference. This evaluation can be of assistance for future research in this field.