 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeed-Forward Gaussian Splatting from Sparse Aerial Views
May 19, 2026Reconstructing large-scale urban scenes from sparse aerial views is a crucial yet challenging task. Due to biased top-down and shallow-oblique camera poses, sparse aerial captures exhibit strong evidence imbalance: roofs and open regions are repeatedly observed, while facades, distant buildings, and occluded structures receive little multi-view support. Existing feed-forward 3D Gaussian Splatting methods directly regress a deterministic representation from sparse inputs, but this often leads to ghosting, melted facades, and stretched textures. Recent pseudo-view and video-based generative reconstruction methods use additional supervision or generative priors. However, they often lack a clear separation between observed geometry and prior-driven content, which can lead to plausible but inconsistent structures. We propose AnyCity, an observation-grounded generative reconstruction framework for sparse aerial urban scenes. AnyCity first predicts an observation-supported geometry latent to anchor reliable structures, and then uses scaffold-conditioned aerial completion tokens to predict a gated residual update for weakly constrained content before Gaussian decoding. During training, dense-to-sparse distillation transfers structural cues from dense-view reconstruction, while an aerial-adapted video diffusion prior provides fine-grained urban appearance cues through gated token conditioning. Observation-preserving objectives keep the refined representation consistent with input-supported geometry. At inference time, AnyCity reconstructs the final 3D Gaussian scene from sparse aerial views in a single feed-forward pass, achieving coherent urban novel-view synthesis with second-level inference. Experiments on synthetic, aerial-domain, UAV-textured, and real-world scenes show consistent improvements over feed-forward baselines.
Accurate Point Measurement in 3DGS -- A New Alternative to Traditional Stereoscopic-View Based Measurements
Mar 25, 20263D Gaussian Splatting (3DGS) has revolutionized real-time rendering with its state-of-the-art novel view synthesis, but its utility for accurate geometric measurement remains underutilized. Compared to multi-view stereo (MVS) point clouds or meshes, 3DGS rendered views present superior visual quality and completeness. However, current point measurement methods still rely on demanding stereoscopic workstations or direct picking on often-incomplete and inaccurate 3D meshes. As a novel view synthesizer, 3DGS renders exact source views and smoothly interpolates in-between views. This allows users to intuitively pick congruent points across different views while operating 3DGS models. By triangulating these congruent points, one can precisely generate 3D point measurements. This approach mimics traditional stereoscopic measurement but is significantly less demanding: it requires neither a stereo workstation nor specialized operator stereoscopic capability. Furthermore, it enables multi-view intersection (more than two views) for higher measurement accuracy. We implemented a web-based application to demonstrate this proof-of-concept (PoC). Using several UAV aerial datasets, we show this PoC allows users to successfully perform highly accurate point measurements, achieving accuracy matching or exceeding traditional stereoscopic methods on standard hardware. Specifically, our approach significantly outperforms direct mesh-based measurements. Quantitatively, our method achieves RMSEs in the 1-2 cm range on well-defined points. More critically, on challenging thin structures where mesh-based RMSE was 0.062 m, our method achieved 0.037 m. On sharp corners poorly reconstructed in the mesh, our method successfully measured all points with a 0.013 m RMSE, whereas the mesh method failed entirely. Code is available at: https://github.com/GDAOSU/3dgs_measurement_tool.
AeroDGS: Physically Consistent Dynamic Gaussian Splatting for Single-Sequence Aerial 4D Reconstruction
Feb 25, 2026Recent advances in 4D scene reconstruction have significantly improved dynamic modeling across various domains. However, existing approaches remain limited under aerial conditions with single-view capture, wide spatial range, and dynamic objects of limited spatial footprint and large motion disparity. These challenges cause severe depth ambiguity and unstable motion estimation, making monocular aerial reconstruction inherently ill-posed. To this end, we present AeroDGS, a physics-guided 4D Gaussian splatting framework for monocular UAV videos. AeroDGS introduces a Monocular Geometry Lifting module that reconstructs reliable static and dynamic geometry from a single aerial sequence, providing a robust basis for dynamic estimation. To further resolve monocular ambiguity, we propose a Physics-Guided Optimization module that incorporates differentiable ground-support, upright-stability, and trajectory-smoothness priors, transforming ambiguous image cues into physically consistent motion. The framework jointly refines static backgrounds and dynamic entities with stable geometry and coherent temporal evolution. We additionally build a real-world UAV dataset that spans various altitudes and motion conditions to evaluate dynamic aerial reconstruction. Experiments on synthetic and real UAV scenes demonstrate that AeroDGS outperforms state-of-the-art methods, achieving superior reconstruction fidelity in dynamic aerial environments.
Olbedo: An Albedo and Shading Aerial Dataset for Large-Scale Outdoor Environments
Feb 24, 2026Intrinsic image decomposition (IID) of outdoor scenes is crucial for relighting, editing, and understanding large-scale environments, but progress has been limited by the lack of real-world datasets with reliable albedo and shading supervision. We introduce Olbedo, a large-scale aerial dataset for outdoor albedo--shading decomposition in the wild. Olbedo contains 5,664 UAV images captured across four landscape types, multiple years, and diverse illumination conditions. Each view is accompanied by multi-view consistent albedo and shading maps, metric depth, surface normals, sun and sky shading components, camera poses, and, for recent flights, measured HDR sky domes. These annotations are derived from an inverse-rendering refinement pipeline over multi-view stereo reconstructions and calibrated sky illumination, together with per-pixel confidence masks. We demonstrate that Olbedo enables state-of-the-art diffusion-based IID models, originally trained on synthetic indoor data, to generalize to real outdoor imagery: fine-tuning on Olbedo significantly improves single-view outdoor albedo prediction on the MatrixCity benchmark. We further illustrate applications of Olbedo-trained models to multi-view consistent relighting of 3D assets, material editing, and scene change analysis for urban digital twins. We release the dataset, baseline models, and an evaluation protocol to support future research in outdoor intrinsic decomposition and illumination-aware aerial vision.
Cross-view Localization and Synthesis - Datasets, Challenges and Opportunities
Oct 26, 2025Cross-view localization and synthesis are two fundamental tasks in cross-view visual understanding, which deals with cross-view datasets: overhead (satellite or aerial) and ground-level imagery. These tasks have gained increasing attention due to their broad applications in autonomous navigation, urban planning, and augmented reality. Cross-view localization aims to estimate the geographic position of ground-level images based on information provided by overhead imagery while cross-view synthesis seeks to generate ground-level images based on information from the overhead imagery. Both tasks remain challenging due to significant differences in viewing perspective, resolution, and occlusion, which are widely embedded in cross-view datasets. Recent years have witnessed rapid progress driven by the availability of large-scale datasets and novel approaches. Typically, cross-view localization is formulated as an image retrieval problem where ground-level features are matched with tiled overhead images feature, extracted by convolutional neural networks (CNNs) or vision transformers (ViTs) for cross-view feature embedding. Cross-view synthesis, on the other hand, seeks to generate ground-level views based on information from overhead imagery, generally using generative adversarial networks (GANs) or diffusion models. This paper presents a comprehensive survey of advances in cross-view localization and synthesis, reviewing widely used datasets, highlighting key challenges, and providing an organized overview of state-of-the-art techniques. Furthermore, it discusses current limitations, offers comparative analyses, and outlines promising directions for future research. We also include the project page via https://github.com/GDAOSU/Awesome-Cross-View-Methods.
Deep learning for 3D point cloud processing -- from approaches, tasks to its implications on urban and environmental applications
Sep 15, 2025Point cloud processing as a fundamental task in the field of geomatics and computer vision, has been supporting tasks and applications at different scales from air to ground, including mapping, environmental monitoring, urban/tree structure modeling, automated driving, robotics, disaster responses etc. Due to the rapid development of deep learning, point cloud processing algorithms have nowadays been almost explicitly dominated by learning-based approaches, most of which are yet transitioned into real-world practices. Existing surveys primarily focus on the ever-updating network architecture to accommodate unordered point clouds, largely ignoring their practical values in typical point cloud processing applications, in which extra-large volume of data, diverse scene contents, varying point density, data modality need to be considered. In this paper, we provide a meta review on deep learning approaches and datasets that cover a selection of critical tasks of point cloud processing in use such as scene completion, registration, semantic segmentation, and modeling. By reviewing a broad range of urban and environmental applications these tasks can support, we identify gaps to be closed as these methods transformed into applications and draw concluding remarks in both the algorithmic and practical aspects of the surveyed methods.
Synthetic Data Matters: Re-training with Geo-typical Synthetic Labels for Building Detection
Jul 22, 2025Deep learning has significantly advanced building segmentation in remote sensing, yet models struggle to generalize on data of diverse geographic regions due to variations in city layouts and the distribution of building types, sizes and locations. However, the amount of time-consuming annotated data for capturing worldwide diversity may never catch up with the demands of increasingly data-hungry models. Thus, we propose a novel approach: re-training models at test time using synthetic data tailored to the target region's city layout. This method generates geo-typical synthetic data that closely replicates the urban structure of a target area by leveraging geospatial data such as street network from OpenStreetMap. Using procedural modeling and physics-based rendering, very high-resolution synthetic images are created, incorporating domain randomization in building shapes, materials, and environmental illumination. This enables the generation of virtually unlimited training samples that maintain the essential characteristics of the target environment. To overcome synthetic-to-real domain gaps, our approach integrates geo-typical data into an adversarial domain adaptation framework for building segmentation. Experiments demonstrate significant performance enhancements, with median improvements of up to 12%, depending on the domain gap. This scalable and cost-effective method blends partial geographic knowledge with synthetic imagery, providing a promising solution to the "model collapse" issue in purely synthetic datasets. It offers a practical pathway to improving generalization in remote sensing building segmentation without extensive real-world annotations.
Uncertainty Quantification Framework for Aerial and UAV Photogrammetry through Error Propagation
Jul 17, 2025Uncertainty quantification of the photogrammetry process is essential for providing per-point accuracy credentials of the point clouds. Unlike airborne LiDAR, which typically delivers consistent accuracy across various scenes, the accuracy of photogrammetric point clouds is highly scene-dependent, since it relies on algorithm-generated measurements (i.e., stereo or multi-view stereo). Generally, errors of the photogrammetric point clouds propagate through a two-step process: Structure-from-Motion (SfM) with Bundle adjustment (BA), followed by Multi-view Stereo (MVS). While uncertainty estimation in the SfM stage has been well studied using the first-order statistics of the reprojection error function, that in the MVS stage remains largely unsolved and non-standardized, primarily due to its non-differentiable and multi-modal nature (i.e., from pixel values to geometry). In this paper, we present an uncertainty quantification framework closing this gap by associating an error covariance matrix per point accounting for this two-step photogrammetry process. Specifically, to estimate the uncertainty in the MVS stage, we propose a novel, self-calibrating method by taking reliable n-view points (n>=6) per-view to regress the disparity uncertainty using highly relevant cues (such as matching cost values) from the MVS stage. Compared to existing approaches, our method uses self-contained, reliable 3D points extracted directly from the MVS process, with the benefit of being self-supervised and naturally adhering to error propagation path of the photogrammetry process, thereby providing a robust and certifiable uncertainty quantification across diverse scenes. We evaluate the framework using a variety of publicly available airborne and UAV imagery datasets. Results demonstrate that our method outperforms existing approaches by achieving high bounding rates without overestimating uncertainty.
Satellite to GroundScape -- Large-scale Consistent Ground View Generation from Satellite Views
Apr 22, 2025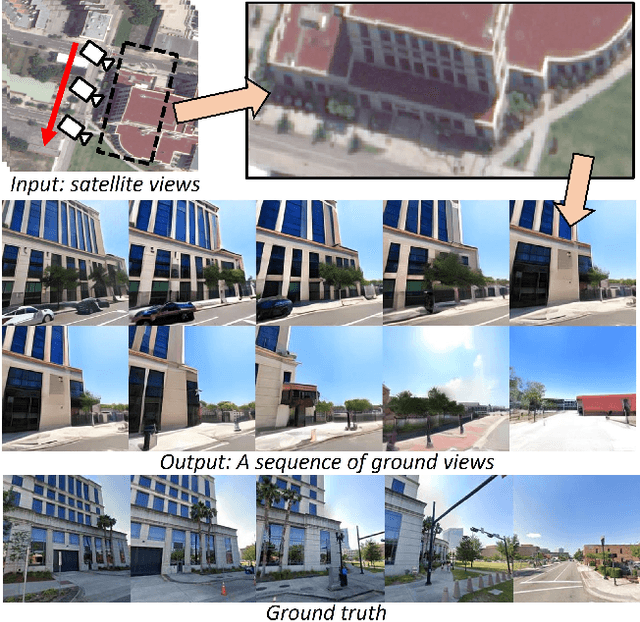



Generating consistent ground-view images from satellite imagery is challenging, primarily due to the large discrepancies in viewing angles and resolution between satellite and ground-level domains. Previous efforts mainly concentrated on single-view generation, often resulting in inconsistencies across neighboring ground views. In this work, we propose a novel cross-view synthesis approach designed to overcome these challenges by ensuring consistency across ground-view images generated from satellite views. Our method, based on a fixed latent diffusion model, introduces two conditioning modules: satellite-guided denoising, which extracts high-level scene layout to guide the denoising process, and satellite-temporal denoising, which captures camera motion to maintain consistency across multiple generated views. We further contribute a large-scale satellite-ground dataset containing over 100,000 perspective pairs to facilitate extensive ground scene or video generation. Experimental results demonstrate that our approach outperforms existing methods on perceptual and temporal metrics, achieving high photorealism and consistency in multi-view outputs.
A Critical Synthesis of Uncertainty Quantification and Foundation Models in Monocular Depth Estimation
Jan 14, 2025
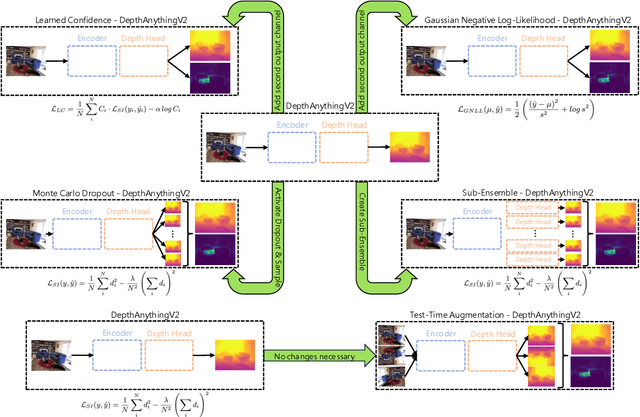
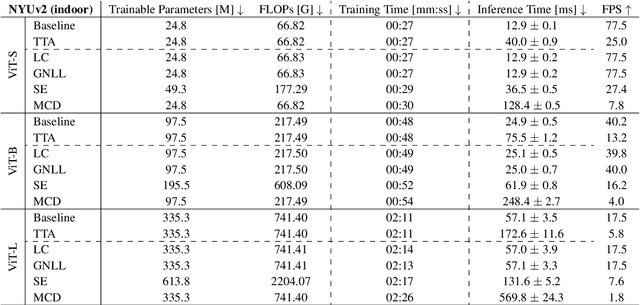
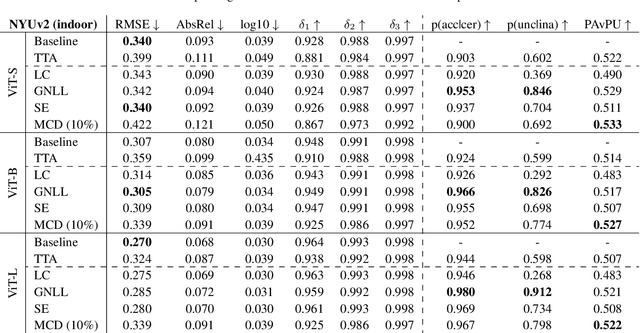
While recent foundation models have enabled significant breakthroughs in monocular depth estimation, a clear path towards safe and reliable deployment in the real-world remains elusive. Metric depth estimation, which involves predicting absolute distances, poses particular challenges, as even the most advanced foundation models remain prone to critical errors. Since quantifying the uncertainty has emerged as a promising endeavor to address these limitations and enable trustworthy deployment, we fuse five different uncertainty quantification methods with the current state-of-the-art DepthAnythingV2 foundation model. To cover a wide range of metric depth domains, we evaluate their performance on four diverse datasets. Our findings identify fine-tuning with the Gaussian Negative Log-Likelihood Loss (GNLL) as a particularly promising approach, offering reliable uncertainty estimates while maintaining predictive performance and computational efficiency on par with the baseline, encompassing both training and inference time. By fusing uncertainty quantification and foundation models within the context of monocular depth estimation, this paper lays a critical foundation for future research aimed at improving not only model performance but also its explainability. Extending this critical synthesis of uncertainty quantification and foundation models into other crucial tasks, such as semantic segmentation and pose estimation, presents exciting opportunities for safer and more reliable machine vision systems.