 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFVGen: Accelerating Novel-View Synthesis with Adversarial Video Diffusion Distillation
Aug 08, 2025Recent progress in 3D reconstruction has enabled realistic 3D models from dense image captures, yet challenges persist with sparse views, often leading to artifacts in unseen areas. Recent works leverage Video Diffusion Models (VDMs) to generate dense observations, filling the gaps when only sparse views are available for 3D reconstruction tasks. A significant limitation of these methods is their slow sampling speed when using VDMs. In this paper, we present FVGen, a novel framework that addresses this challenge by enabling fast novel view synthesis using VDMs in as few as four sampling steps. We propose a novel video diffusion model distillation method that distills a multi-step denoising teacher model into a few-step denoising student model using Generative Adversarial Networks (GANs) and softened reverse KL-divergence minimization. Extensive experiments on real-world datasets show that, compared to previous works, our framework generates the same number of novel views with similar (or even better) visual quality while reducing sampling time by more than 90%. FVGen significantly improves time efficiency for downstream reconstruction tasks, particularly when working with sparse input views (more than 2) where pre-trained VDMs need to be run multiple times to achieve better spatial coverage.
RDD: Robust Feature Detector and Descriptor using Deformable Transformer
May 12, 2025As a core step in structure-from-motion and SLAM, robust feature detection and description under challenging scenarios such as significant viewpoint changes remain unresolved despite their ubiquity. While recent works have identified the importance of local features in modeling geometric transformations, these methods fail to learn the visual cues present in long-range relationships. We present Robust Deformable Detector (RDD), a novel and robust keypoint detector/descriptor leveraging the deformable transformer, which captures global context and geometric invariance through deformable self-attention mechanisms. Specifically, we observed that deformable attention focuses on key locations, effectively reducing the search space complexity and modeling the geometric invariance. Furthermore, we collected an Air-to-Ground dataset for training in addition to the standard MegaDepth dataset. Our proposed method outperforms all state-of-the-art keypoint detection/description methods in sparse matching tasks and is also capable of semi-dense matching. To ensure comprehensive evaluation, we introduce two challenging benchmarks: one emphasizing large viewpoint and scale variations, and the other being an Air-to-Ground benchmark -- an evaluation setting that has recently gaining popularity for 3D reconstruction across different altitudes.
Bringing Diversity from Diffusion Models to Semantic-Guided Face Asset Generation
Apr 21, 2025

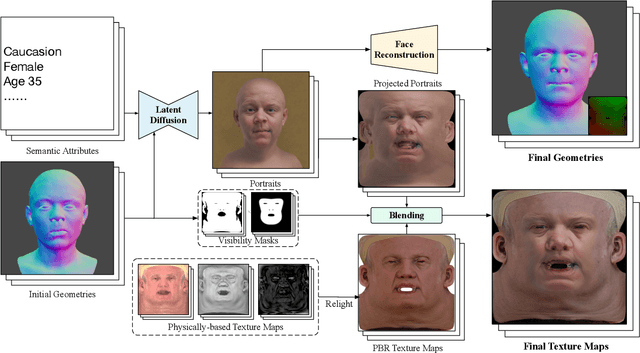

Digital modeling and reconstruction of human faces serve various applications. However, its availability is often hindered by the requirements of data capturing devices, manual labor, and suitable actors. This situation restricts the diversity, expressiveness, and control over the resulting models. This work aims to demonstrate that a semantically controllable generative network can provide enhanced control over the digital face modeling process. To enhance diversity beyond the limited human faces scanned in a controlled setting, we introduce a novel data generation pipeline that creates a high-quality 3D face database using a pre-trained diffusion model. Our proposed normalization module converts synthesized data from the diffusion model into high-quality scanned data. Using the 44,000 face models we obtained, we further developed an efficient GAN-based generator. This generator accepts semantic attributes as input, and generates geometry and albedo. It also allows continuous post-editing of attributes in the latent space. Our asset refinement component subsequently creates physically-based facial assets. We introduce a comprehensive system designed for creating and editing high-quality face assets. Our proposed model has undergone extensive experiment, comparison and evaluation. We also integrate everything into a web-based interactive tool. We aim to make this tool publicly available with the release of the paper.
Geometry-aware Feature Matching for Large-Scale Structure from Motion
Sep 03, 2024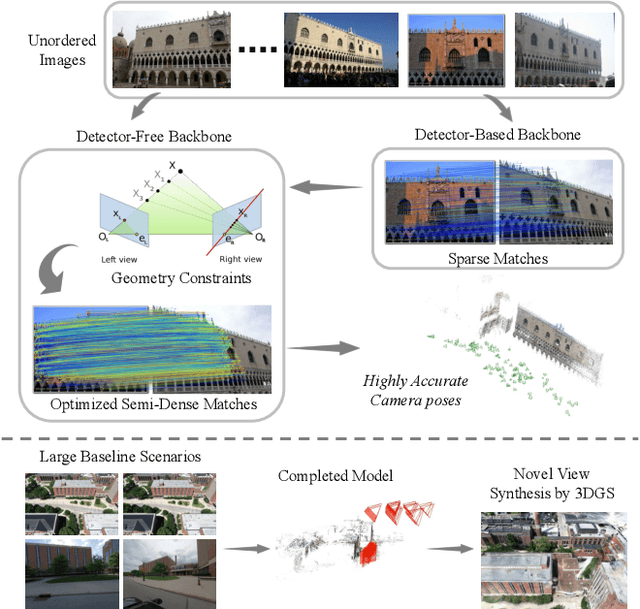
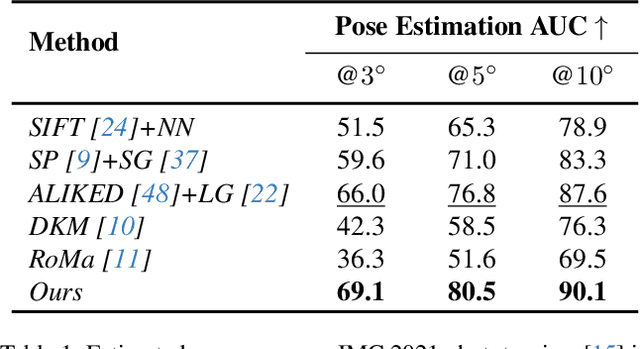

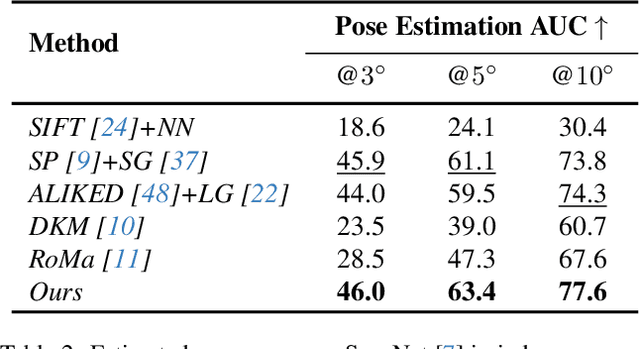
Establishing consistent and dense correspondences across multiple images is crucial for Structure from Motion (SfM) systems. Significant view changes, such as air-to-ground with very sparse view overlap, pose an even greater challenge to the correspondence solvers. We present a novel optimization-based approach that significantly enhances existing feature matching methods by introducing geometry cues in addition to color cues. This helps fill gaps when there is less overlap in large-scale scenarios. Our method formulates geometric verification as an optimization problem, guiding feature matching within detector-free methods and using sparse correspondences from detector-based methods as anchor points. By enforcing geometric constraints via the Sampson Distance, our approach ensures that the denser correspondences from detector-free methods are geometrically consistent and more accurate. This hybrid strategy significantly improves correspondence density and accuracy, mitigates multi-view inconsistencies, and leads to notable advancements in camera pose accuracy and point cloud density. It outperforms state-of-the-art feature matching methods on benchmark datasets and enables feature matching in challenging extreme large-scale settings.
Don't Look into the Dark: Latent Codes for Pluralistic Image Inpainting
Mar 27, 2024

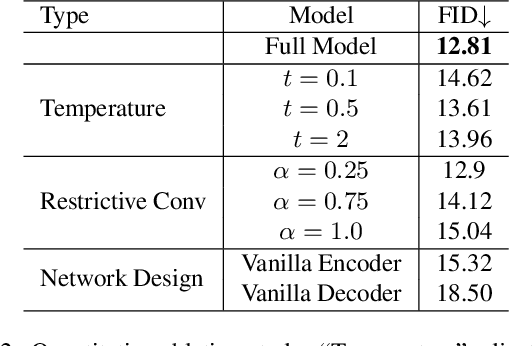
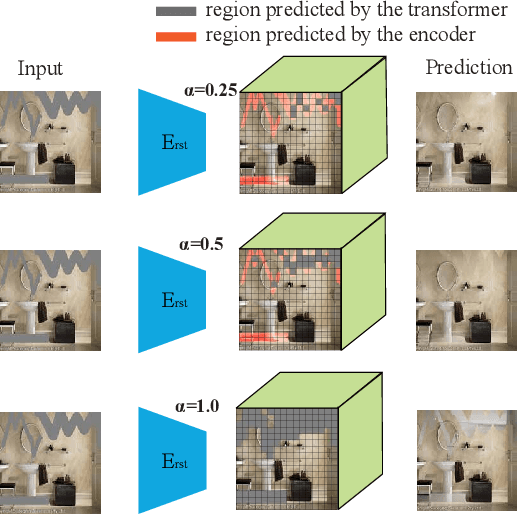
We present a method for large-mask pluralistic image inpainting based on the generative framework of discrete latent codes. Our method learns latent priors, discretized as tokens, by only performing computations at the visible locations of the image. This is realized by a restrictive partial encoder that predicts the token label for each visible block, a bidirectional transformer that infers the missing labels by only looking at these tokens, and a dedicated synthesis network that couples the tokens with the partial image priors to generate coherent and pluralistic complete image even under extreme mask settings. Experiments on public benchmarks validate our design choices as the proposed method outperforms strong baselines in both visual quality and diversity metrics.
Exemplar-based Pattern Synthesis with Implicit Periodic Field Network
Apr 15, 2022
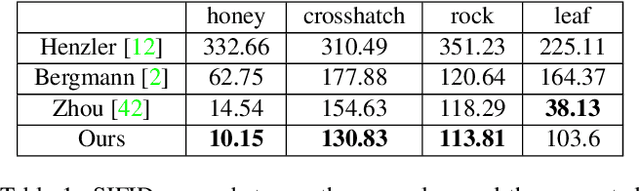
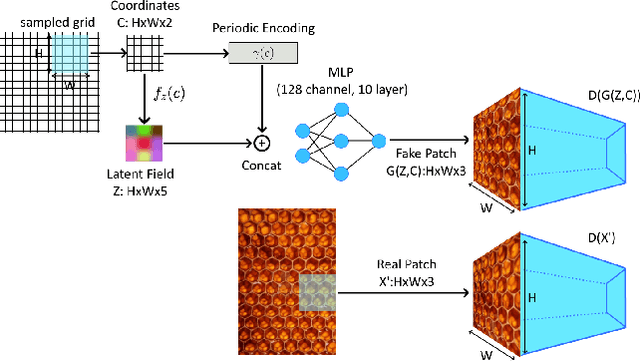
Synthesis of ergodic, stationary visual patterns is widely applicable in texturing, shape modeling, and digital content creation. The wide applicability of this technique thus requires the pattern synthesis approaches to be scalable, diverse, and authentic. In this paper, we propose an exemplar-based visual pattern synthesis framework that aims to model the inner statistics of visual patterns and generate new, versatile patterns that meet the aforementioned requirements. To this end, we propose an implicit network based on generative adversarial network (GAN) and periodic encoding, thus calling our network the Implicit Periodic Field Network (IPFN). The design of IPFN ensures scalability: the implicit formulation directly maps the input coordinates to features, which enables synthesis of arbitrary size and is computationally efficient for 3D shape synthesis. Learning with a periodic encoding scheme encourages diversity: the network is constrained to model the inner statistics of the exemplar based on spatial latent codes in a periodic field. Coupled with continuously designed GAN training procedures, IPFN is shown to synthesize tileable patterns with smooth transitions and local variations. Last but not least, thanks to both the adversarial training technique and the encoded Fourier features, IPFN learns high-frequency functions that produce authentic, high-quality results. To validate our approach, we present novel experimental results on various applications in 2D texture synthesis and 3D shape synthesis.
Equivariant Point Network for 3D Point Cloud Analysis
Apr 02, 2021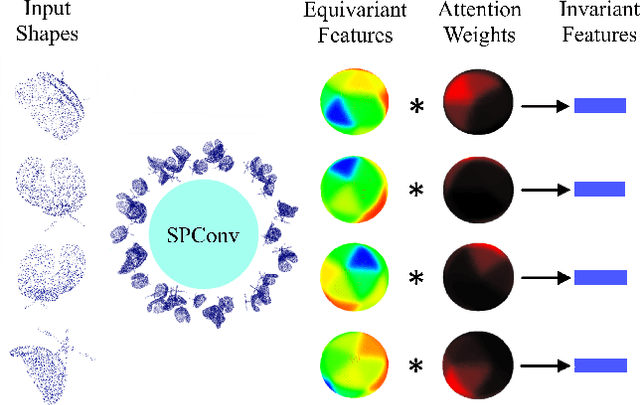
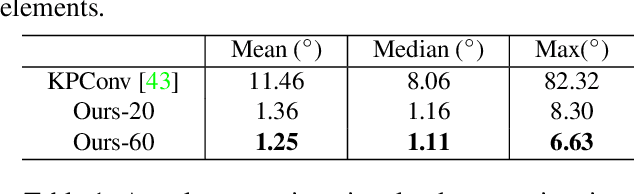
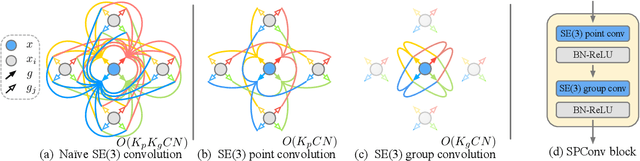
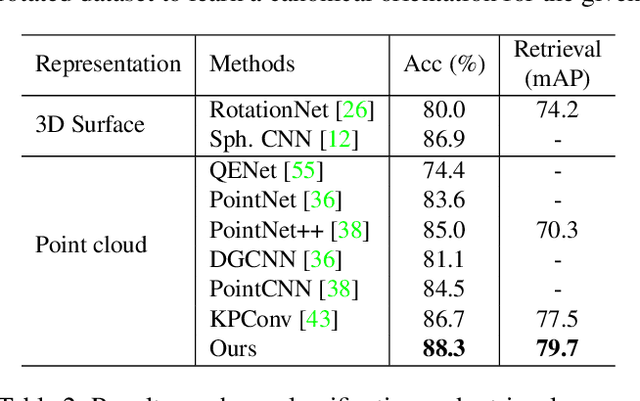
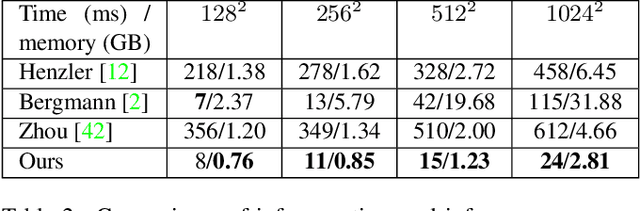
Features that are equivariant to a larger group of symmetries have been shown to be more discriminative and powerful in recent studies. However, higher-order equivariant features often come with an exponentially-growing computational cost. Furthermore, it remains relatively less explored how rotation-equivariant features can be leveraged to tackle 3D shape alignment tasks. While many past approaches have been based on either non-equivariant or invariant descriptors to align 3D shapes, we argue that such tasks may benefit greatly from an equivariant framework. In this paper, we propose an effective and practical SE(3) (3D translation and rotation) equivariant network for point cloud analysis that addresses both problems. First, we present SE(3) separable point convolution, a novel framework that breaks down the 6D convolution into two separable convolutional operators alternatively performed in the 3D Euclidean and SO(3) spaces. This significantly reduces the computational cost without compromising the performance. Second, we introduce an attention layer to effectively harness the expressiveness of the equivariant features. While jointly trained with the network, the attention layer implicitly derives the intrinsic local frame in the feature space and generates attention vectors that can be integrated into different alignment tasks. We evaluate our approach through extensive studies and visual interpretations. The empirical results demonstrate that our proposed model outperforms strong baselines in a variety of benchmarks
One-Shot Identity-Preserving Portrait Reenactment
Apr 26, 2020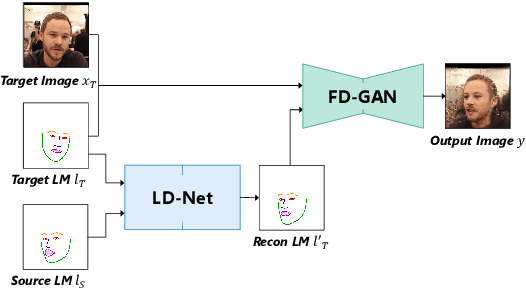

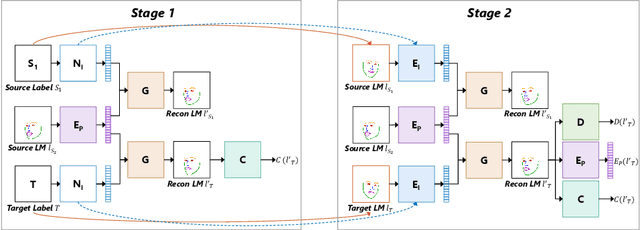

We present a deep learning-based framework for portrait reenactment from a single picture of a target (one-shot) and a video of a driving subject. Existing facial reenactment methods suffer from identity mismatch and produce inconsistent identities when a target and a driving subject are different (cross-subject), especially in one-shot settings. In this work, we aim to address identity preservation in cross-subject portrait reenactment from a single picture. We introduce a novel technique that can disentangle identity from expressions and poses, allowing identity preserving portrait reenactment even when the driver's identity is very different from that of the target. This is achieved by a novel landmark disentanglement network (LD-Net), which predicts personalized facial landmarks that combine the identity of the target with expressions and poses from a different subject. To handle portrait reenactment from unseen subjects, we also introduce a feature dictionary-based generative adversarial network (FD-GAN), which locally translates 2D landmarks into a personalized portrait, enabling one-shot portrait reenactment under large pose and expression variations. We validate the effectiveness of our identity disentangling capabilities via an extensive ablation study, and our method produces consistent identities for cross-subject portrait reenactment. Our comprehensive experiments show that our method significantly outperforms the state-of-the-art single-image facial reenactment methods. We will release our code and models for academic use.