 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICTPolarReal: A Polarized Reflection and Material Dataset of Real World Objects
Mar 26, 2026Accurately modeling how real-world materials reflect light remains a core challenge in inverse rendering, largely due to the scarcity of real measured reflectance data. Existing approaches rely heavily on synthetic datasets with simplified illumination and limited material realism, preventing models from generalizing to real-world images. We introduce a large-scale polarized reflection and material dataset of real-world objects, captured with an 8-camera, 346-light Light Stage equipped with cross/parallel polarization. Our dataset spans 218 everyday objects across five acquisition dimensions-multiview, multi-illumination, polarization, reflectance separation, and material attributes-yielding over 1.2M high-resolution images with diffuse-specular separation and analytically derived diffuse albedo, specular albedo, and surface normals. Using this dataset, we train and evaluate state-of-the-art inverse and forward rendering models on intrinsic decomposition, relighting, and sparse-view 3D reconstruction, demonstrating significant improvements in material separation, illumination fidelity, and geometric consistency. We hope that our work can establish a new foundation for physically grounded material understanding and enable real-world generalization beyond synthetic training regimes. Project page: https://jingyangcarl.github.io/ICTPolarReal/
DCARL: A Divide-and-Conquer Framework for Autoregressive Long-Trajectory Video Generation
Mar 25, 2026Long-trajectory video generation is a crucial yet challenging task for world modeling primarily due to the limited scalability of existing video diffusion models (VDMs). Autoregressive models, while offering infinite rollout, suffer from visual drift and poor controllability. To address these issues, we propose DCARL, a novel divide-and-conquer, autoregressive framework that effectively combines the structural stability of the divide-and-conquer scheme with the high-fidelity generation of VDMs. Our approach first employs a dedicated Keyframe Generator trained without temporal compression to establish long-range, globally consistent structural anchors. Subsequently, an Interpolation Generator synthesizes the dense frames in an autoregressive manner with overlapping segments, utilizing the keyframes for global context and a single clean preceding frame for local coherence. Trained on a large-scale internet long trajectory video dataset, our method achieves superior performance in both visual quality (lower FID and FVD) and camera adherence (lower ATE and ARE) compared to state-of-the-art autoregressive and divide-and-conquer baselines, demonstrating stable and high-fidelity generation for long trajectory videos up to 32 seconds in length.
Olbedo: An Albedo and Shading Aerial Dataset for Large-Scale Outdoor Environments
Feb 24, 2026Intrinsic image decomposition (IID) of outdoor scenes is crucial for relighting, editing, and understanding large-scale environments, but progress has been limited by the lack of real-world datasets with reliable albedo and shading supervision. We introduce Olbedo, a large-scale aerial dataset for outdoor albedo--shading decomposition in the wild. Olbedo contains 5,664 UAV images captured across four landscape types, multiple years, and diverse illumination conditions. Each view is accompanied by multi-view consistent albedo and shading maps, metric depth, surface normals, sun and sky shading components, camera poses, and, for recent flights, measured HDR sky domes. These annotations are derived from an inverse-rendering refinement pipeline over multi-view stereo reconstructions and calibrated sky illumination, together with per-pixel confidence masks. We demonstrate that Olbedo enables state-of-the-art diffusion-based IID models, originally trained on synthetic indoor data, to generalize to real outdoor imagery: fine-tuning on Olbedo significantly improves single-view outdoor albedo prediction on the MatrixCity benchmark. We further illustrate applications of Olbedo-trained models to multi-view consistent relighting of 3D assets, material editing, and scene change analysis for urban digital twins. We release the dataset, baseline models, and an evaluation protocol to support future research in outdoor intrinsic decomposition and illumination-aware aerial vision.
Learning an Implicit Physics Model for Image-based Fluid Simulation
Aug 11, 2025Humans possess an exceptional ability to imagine 4D scenes, encompassing both motion and 3D geometry, from a single still image. This ability is rooted in our accumulated observations of similar scenes and an intuitive understanding of physics. In this paper, we aim to replicate this capacity in neural networks, specifically focusing on natural fluid imagery. Existing methods for this task typically employ simplistic 2D motion estimators to animate the image, leading to motion predictions that often defy physical principles, resulting in unrealistic animations. Our approach introduces a novel method for generating 4D scenes with physics-consistent animation from a single image. We propose the use of a physics-informed neural network that predicts motion for each surface point, guided by a loss term derived from fundamental physical principles, including the Navier-Stokes equations. To capture appearance, we predict feature-based 3D Gaussians from the input image and its estimated depth, which are then animated using the predicted motions and rendered from any desired camera perspective. Experimental results highlight the effectiveness of our method in producing physically plausible animations, showcasing significant performance improvements over existing methods. Our project page is https://physfluid.github.io/ .
FVGen: Accelerating Novel-View Synthesis with Adversarial Video Diffusion Distillation
Aug 08, 2025



Recent progress in 3D reconstruction has enabled realistic 3D models from dense image captures, yet challenges persist with sparse views, often leading to artifacts in unseen areas. Recent works leverage Video Diffusion Models (VDMs) to generate dense observations, filling the gaps when only sparse views are available for 3D reconstruction tasks. A significant limitation of these methods is their slow sampling speed when using VDMs. In this paper, we present FVGen, a novel framework that addresses this challenge by enabling fast novel view synthesis using VDMs in as few as four sampling steps. We propose a novel video diffusion model distillation method that distills a multi-step denoising teacher model into a few-step denoising student model using Generative Adversarial Networks (GANs) and softened reverse KL-divergence minimization. Extensive experiments on real-world datasets show that, compared to previous works, our framework generates the same number of novel views with similar (or even better) visual quality while reducing sampling time by more than 90%. FVGen significantly improves time efficiency for downstream reconstruction tasks, particularly when working with sparse input views (more than 2) where pre-trained VDMs need to be run multiple times to achieve better spatial coverage.
RDD: Robust Feature Detector and Descriptor using Deformable Transformer
May 12, 2025



As a core step in structure-from-motion and SLAM, robust feature detection and description under challenging scenarios such as significant viewpoint changes remain unresolved despite their ubiquity. While recent works have identified the importance of local features in modeling geometric transformations, these methods fail to learn the visual cues present in long-range relationships. We present Robust Deformable Detector (RDD), a novel and robust keypoint detector/descriptor leveraging the deformable transformer, which captures global context and geometric invariance through deformable self-attention mechanisms. Specifically, we observed that deformable attention focuses on key locations, effectively reducing the search space complexity and modeling the geometric invariance. Furthermore, we collected an Air-to-Ground dataset for training in addition to the standard MegaDepth dataset. Our proposed method outperforms all state-of-the-art keypoint detection/description methods in sparse matching tasks and is also capable of semi-dense matching. To ensure comprehensive evaluation, we introduce two challenging benchmarks: one emphasizing large viewpoint and scale variations, and the other being an Air-to-Ground benchmark -- an evaluation setting that has recently gaining popularity for 3D reconstruction across different altitudes.
Bringing Diversity from Diffusion Models to Semantic-Guided Face Asset Generation
Apr 21, 2025

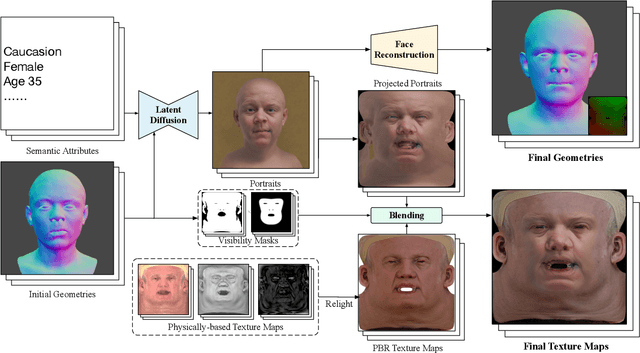

Digital modeling and reconstruction of human faces serve various applications. However, its availability is often hindered by the requirements of data capturing devices, manual labor, and suitable actors. This situation restricts the diversity, expressiveness, and control over the resulting models. This work aims to demonstrate that a semantically controllable generative network can provide enhanced control over the digital face modeling process. To enhance diversity beyond the limited human faces scanned in a controlled setting, we introduce a novel data generation pipeline that creates a high-quality 3D face database using a pre-trained diffusion model. Our proposed normalization module converts synthesized data from the diffusion model into high-quality scanned data. Using the 44,000 face models we obtained, we further developed an efficient GAN-based generator. This generator accepts semantic attributes as input, and generates geometry and albedo. It also allows continuous post-editing of attributes in the latent space. Our asset refinement component subsequently creates physically-based facial assets. We introduce a comprehensive system designed for creating and editing high-quality face assets. Our proposed model has undergone extensive experiment, comparison and evaluation. We also integrate everything into a web-based interactive tool. We aim to make this tool publicly available with the release of the paper.
SC-OmniGS: Self-Calibrating Omnidirectional Gaussian Splatting
Feb 07, 2025



360-degree cameras streamline data collection for radiance field 3D reconstruction by capturing comprehensive scene data. However, traditional radiance field methods do not address the specific challenges inherent to 360-degree images. We present SC-OmniGS, a novel self-calibrating omnidirectional Gaussian splatting system for fast and accurate omnidirectional radiance field reconstruction using 360-degree images. Rather than converting 360-degree images to cube maps and performing perspective image calibration, we treat 360-degree images as a whole sphere and derive a mathematical framework that enables direct omnidirectional camera pose calibration accompanied by 3D Gaussians optimization. Furthermore, we introduce a differentiable omnidirectional camera model in order to rectify the distortion of real-world data for performance enhancement. Overall, the omnidirectional camera intrinsic model, extrinsic poses, and 3D Gaussians are jointly optimized by minimizing weighted spherical photometric loss. Extensive experiments have demonstrated that our proposed SC-OmniGS is able to recover a high-quality radiance field from noisy camera poses or even no pose prior in challenging scenarios characterized by wide baselines and non-object-centric configurations. The noticeable performance gain in the real-world dataset captured by consumer-grade omnidirectional cameras verifies the effectiveness of our general omnidirectional camera model in reducing the distortion of 360-degree images.
Acquisition of Spatially-Varying Reflectance and Surface Normals via Polarized Reflectance Fields
Dec 13, 2024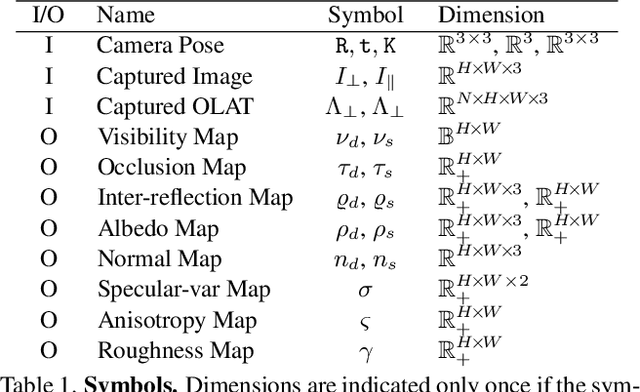
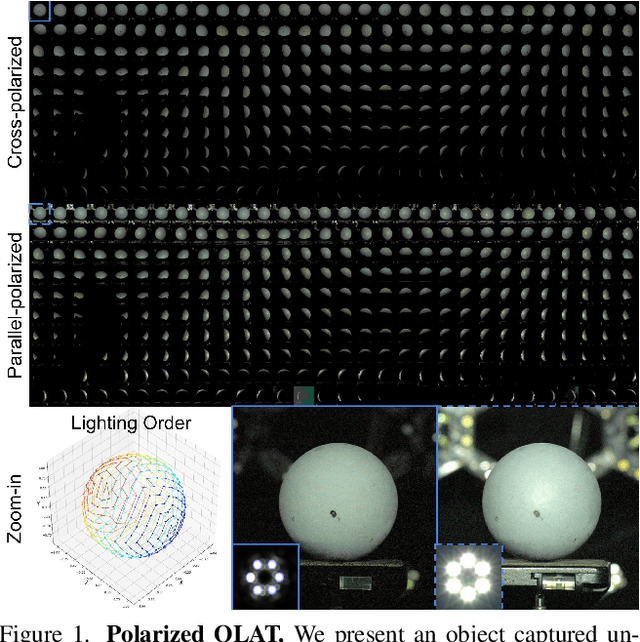
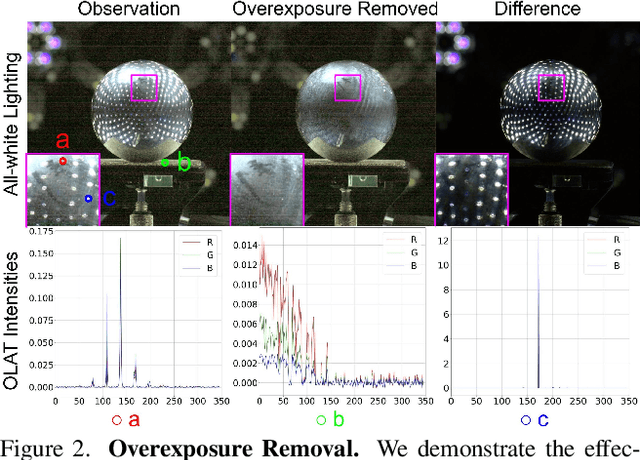
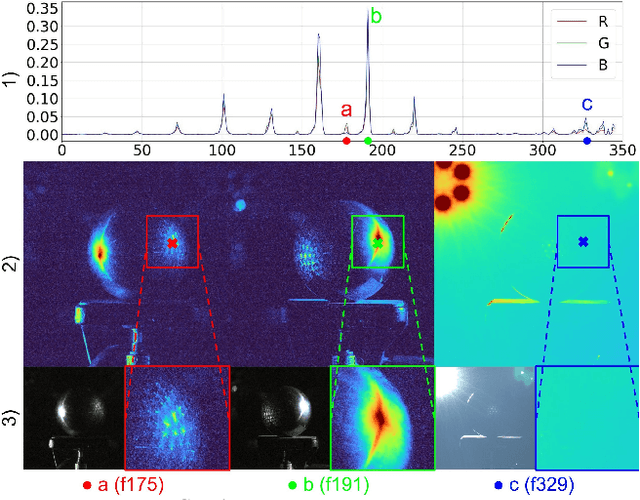
Accurately measuring the geometry and spatially-varying reflectance of real-world objects is a complex task due to their intricate shapes formed by concave features, hollow engravings and diverse surfaces, resulting in inter-reflection and occlusion when photographed. Moreover, issues like lens flare and overexposure can arise from interference from secondary reflections and limitations of hardware even in professional studios. In this paper, we propose a novel approach using polarized reflectance field capture and a comprehensive statistical analysis algorithm to obtain highly accurate surface normals (within 0.1mm/px) and spatially-varying reflectance data, including albedo, specular separation, roughness, and anisotropy parameters for realistic rendering and analysis. Our algorithm removes image artifacts via analytical modeling and further employs both an initial step and an optimization step computed on the whole image collection to further enhance the precision of per-pixel surface reflectance and normal measurement. We showcase the captured shapes and reflectance of diverse objects with a wide material range, spanning from highly diffuse to highly glossy - a challenge unaddressed by prior techniques. Our approach enhances downstream applications by offering precise measurements for realistic rendering and provides a valuable training dataset for emerging research in inverse rendering. We will release the polarized reflectance fields of several captured objects with this work.
Skyeyes: Ground Roaming using Aerial View Images
Sep 25, 2024

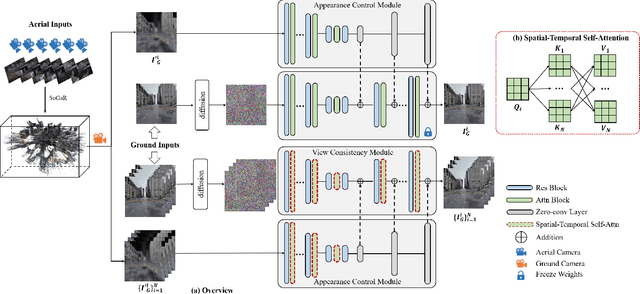

Integrating aerial imagery-based scene generation into applications like autonomous driving and gaming enhances realism in 3D environments, but challenges remain in creating detailed content for occluded areas and ensuring real-time, consistent rendering. In this paper, we introduce Skyeyes, a novel framework that can generate photorealistic sequences of ground view images using only aerial view inputs, thereby creating a ground roaming experience. More specifically, we combine a 3D representation with a view consistent generation model, which ensures coherence between generated images. This method allows for the creation of geometrically consistent ground view images, even with large view gaps. The images maintain improved spatial-temporal coherence and realism, enhancing scene comprehension and visualization from aerial perspectives. To the best of our knowledge, there are no publicly available datasets that contain pairwise geo-aligned aerial and ground view imagery. Therefore, we build a large, synthetic, and geo-aligned dataset using Unreal Engine. Both qualitative and quantitative analyses on this synthetic dataset display superior results compared to other leading synthesis approaches. See the project page for more results: https://chaoren2357.github.io/website-skyeyes/.