 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBringing Diversity from Diffusion Models to Semantic-Guided Face Asset Generation
Apr 21, 2025

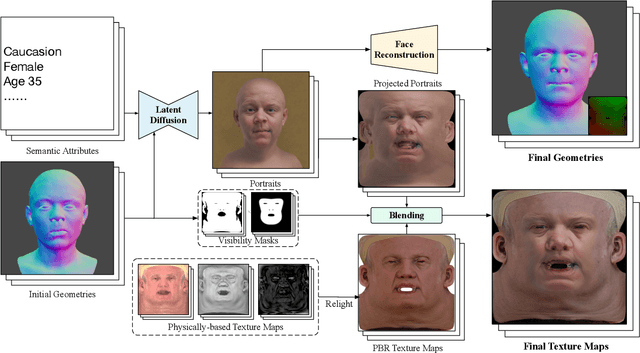

Digital modeling and reconstruction of human faces serve various applications. However, its availability is often hindered by the requirements of data capturing devices, manual labor, and suitable actors. This situation restricts the diversity, expressiveness, and control over the resulting models. This work aims to demonstrate that a semantically controllable generative network can provide enhanced control over the digital face modeling process. To enhance diversity beyond the limited human faces scanned in a controlled setting, we introduce a novel data generation pipeline that creates a high-quality 3D face database using a pre-trained diffusion model. Our proposed normalization module converts synthesized data from the diffusion model into high-quality scanned data. Using the 44,000 face models we obtained, we further developed an efficient GAN-based generator. This generator accepts semantic attributes as input, and generates geometry and albedo. It also allows continuous post-editing of attributes in the latent space. Our asset refinement component subsequently creates physically-based facial assets. We introduce a comprehensive system designed for creating and editing high-quality face assets. Our proposed model has undergone extensive experiment, comparison and evaluation. We also integrate everything into a web-based interactive tool. We aim to make this tool publicly available with the release of the paper.
Texturize a GAN Using a Single Image
Mar 11, 2023



Can we customize a deep generative model which can generate images that can match the texture of some given image? When you see an image of a church, you may wonder if you can get similar pictures for that church. Here we present a method, for adapting GANs with one reference image, and then we can generate images that have similar textures to the given image. Specifically, we modify the weights of the pre-trained GAN model, guided by the reference image given by the user. We use a patch discriminator adversarial loss to encourage the output of the model to match the texture on the given image, also we use a laplacian adversarial loss to ensure diversity and realism, and alleviate the contradiction between the two losses. Experiments show that the proposed method can make the outputs of GANs match the texture of the given image as well as keep diversity and realism.
DisUnknown: Distilling Unknown Factors for Disentanglement Learning
Sep 16, 2021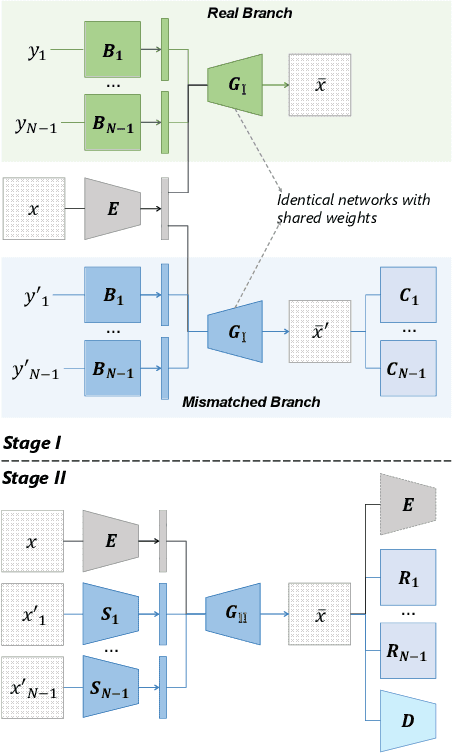
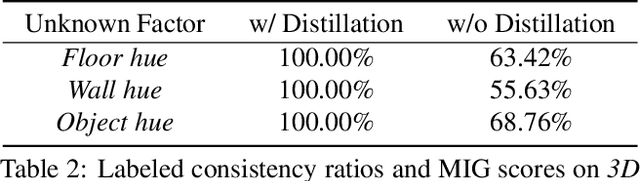


Disentangling data into interpretable and independent factors is critical for controllable generation tasks. With the availability of labeled data, supervision can help enforce the separation of specific factors as expected. However, it is often expensive or even impossible to label every single factor to achieve fully-supervised disentanglement. In this paper, we adopt a general setting where all factors that are hard to label or identify are encapsulated as a single unknown factor. Under this setting, we propose a flexible weakly-supervised multi-factor disentanglement framework DisUnknown, which Distills Unknown factors for enabling multi-conditional generation regarding both labeled and unknown factors. Specifically, a two-stage training approach is adopted to first disentangle the unknown factor with an effective and robust training method, and then train the final generator with the proper disentanglement of all labeled factors utilizing the unknown distillation. To demonstrate the generalization capacity and scalability of our method, we evaluate it on multiple benchmark datasets qualitatively and quantitatively and further apply it to various real-world applications on complicated datasets.
Revisiting the Continuity of Rotation Representations in Neural Networks
Jun 12, 2020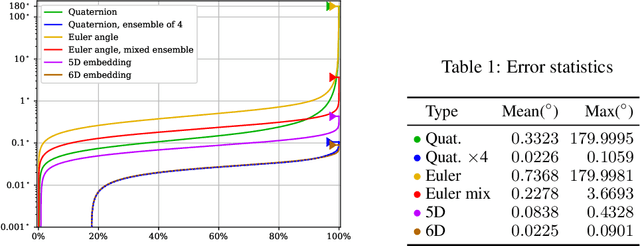
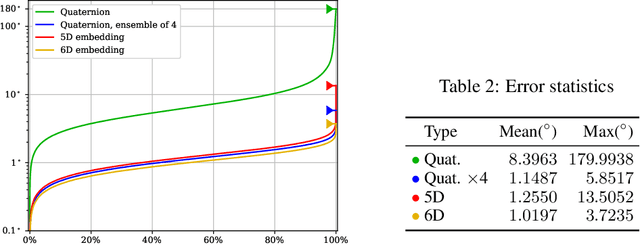
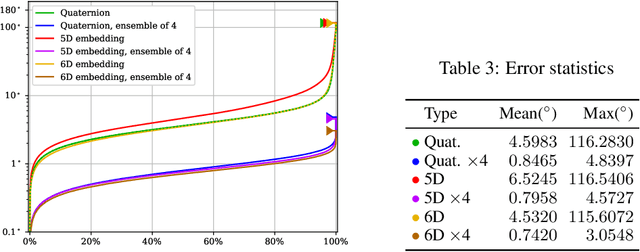
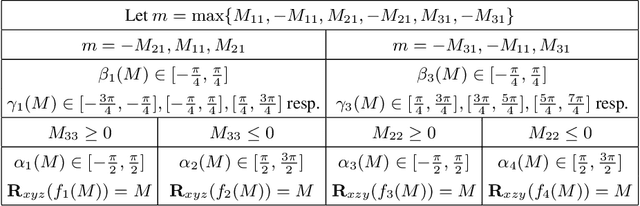
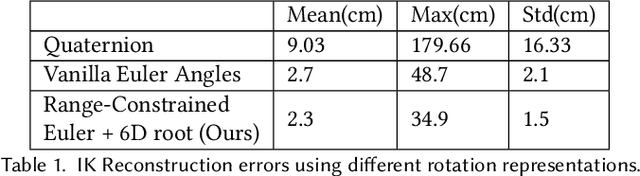
In this paper, we provide some careful analysis of certain pathological behavior of Euler angles and unit quaternions encountered in previous works related to rotation representation in neural networks. In particular, we show that for certain problems, these two representations will provably produce completely wrong results for some inputs, and that this behavior is inherent in the topological property of the problem itself and is not caused by unsuitable network architectures or training procedures. We further show that previously proposed embeddings of $\mathrm{SO}(3)$ into higher dimensional Euclidean spaces aimed at fixing this behavior are not universally effective, due to possible symmetry in the input causing changes to the topology of the input space. We propose an ensemble trick as an alternative solution.
Generative Tweening: Long-term Inbetweening of 3D Human Motions
May 28, 2020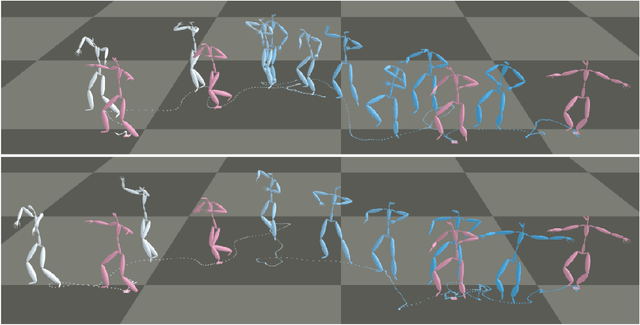
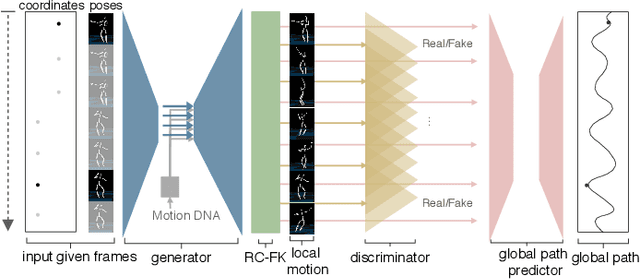

The ability to generate complex and realistic human body animations at scale, while following specific artistic constraints, has been a fundamental goal for the game and animation industry for decades. Popular techniques include key-framing, physics-based simulation, and database methods via motion graphs. Recently, motion generators based on deep learning have been introduced. Although these learning models can automatically generate highly intricate stylized motions of arbitrary length, they still lack user control. To this end, we introduce the problem of long-term inbetweening, which involves automatically synthesizing complex motions over a long time interval given very sparse keyframes by users. We identify a number of challenges related to this problem, including maintaining biomechanical and keyframe constraints, preserving natural motions, and designing the entire motion sequence holistically while considering all constraints. We introduce a biomechanically constrained generative adversarial network that performs long-term inbetweening of human motions, conditioned on keyframe constraints. This network uses a novel two-stage approach where it first predicts local motion in the form of joint angles, and then predicts global motion, i.e. the global path that the character follows. Since there are typically a number of possible motions that could satisfy the given user constraints, we also enable our network to generate a variety of outputs with a scheme that we call Motion DNA. This approach allows the user to manipulate and influence the output content by feeding seed motions (DNA) to the network. Trained with 79 classes of captured motion data, our network performs robustly on a variety of highly complex motion styles.
One-Shot Identity-Preserving Portrait Reenactment
Apr 26, 2020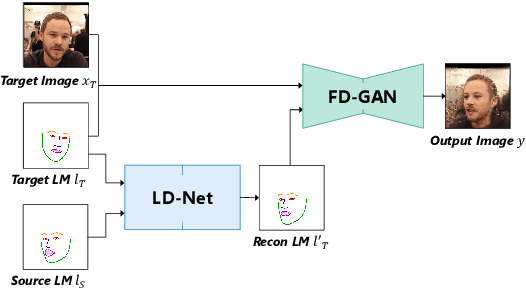

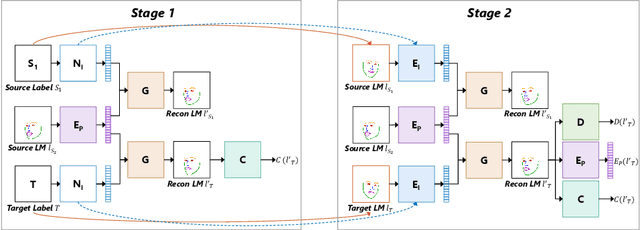

We present a deep learning-based framework for portrait reenactment from a single picture of a target (one-shot) and a video of a driving subject. Existing facial reenactment methods suffer from identity mismatch and produce inconsistent identities when a target and a driving subject are different (cross-subject), especially in one-shot settings. In this work, we aim to address identity preservation in cross-subject portrait reenactment from a single picture. We introduce a novel technique that can disentangle identity from expressions and poses, allowing identity preserving portrait reenactment even when the driver's identity is very different from that of the target. This is achieved by a novel landmark disentanglement network (LD-Net), which predicts personalized facial landmarks that combine the identity of the target with expressions and poses from a different subject. To handle portrait reenactment from unseen subjects, we also introduce a feature dictionary-based generative adversarial network (FD-GAN), which locally translates 2D landmarks into a personalized portrait, enabling one-shot portrait reenactment under large pose and expression variations. We validate the effectiveness of our identity disentangling capabilities via an extensive ablation study, and our method produces consistent identities for cross-subject portrait reenactment. Our comprehensive experiments show that our method significantly outperforms the state-of-the-art single-image facial reenactment methods. We will release our code and models for academic use.
Disentangling Style and Content in Anime Illustrations
May 28, 2019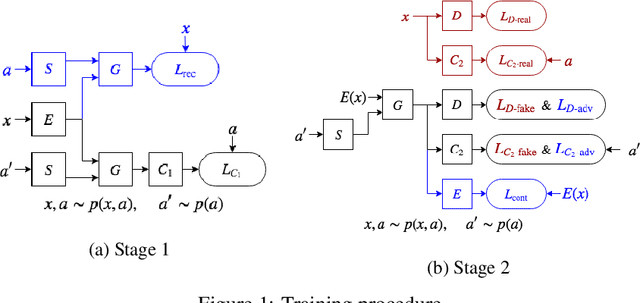


Existing methods for AI-generated artworks still struggle with generating high-quality stylized content, where high-level semantics are preserved, or separating fine-grained styles from various artists. We propose a novel Generative Adversarial Disentanglement Network which can fully decompose complex anime illustrations into style and content. Training such model is challenging, since given a style, various content data may exist but not the other way round. In particular, we disentangle two complementary factors of variations, where one of the factors is labelled. Our approach is divided into two stages, one that encodes an input image into a style independent content, and one based on a dual-conditional generator. We demonstrate the ability to generate high-fidelity anime portraits with a fixed content and a large variety of styles from over a thousand artists, and vice versa, using a single end-to-end network and with applications in style transfer. We show this unique capability as well as superior output to the current state-of-the-art.
Anime Style Space Exploration Using Metric Learning and Generative Adversarial Networks
May 21, 2018
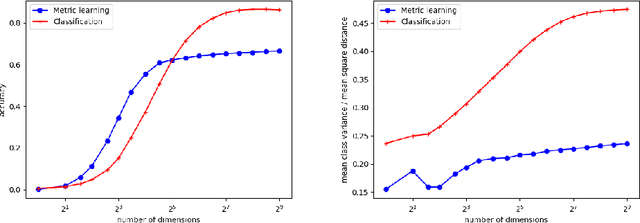


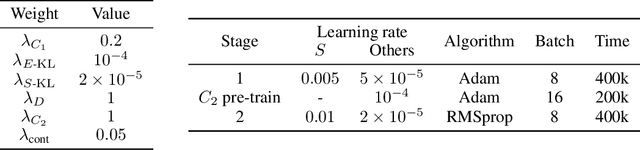
Deep learning-based style transfer between images has recently become a popular area of research. A common way of encoding "style" is through a feature representation based on the Gram matrix of features extracted by some pre-trained neural network or some other form of feature statistics. Such a definition is based on an arbitrary human decision and may not best capture what a style really is. In trying to gain a better understanding of "style", we propose a metric learning-based method to explicitly encode the style of an artwork. In particular, our definition of style captures the differences between artists, as shown by classification performances, and such that the style representation can be interpreted, manipulated and visualized through style-conditioned image generation through a Generative Adversarial Network. We employ this method to explore the style space of anime portrait illustrations.
On the Effects of Batch and Weight Normalization in Generative Adversarial Networks
Dec 04, 2017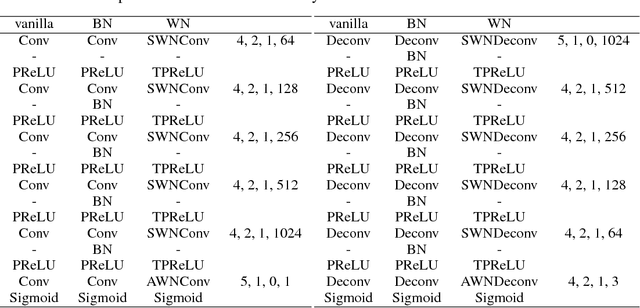
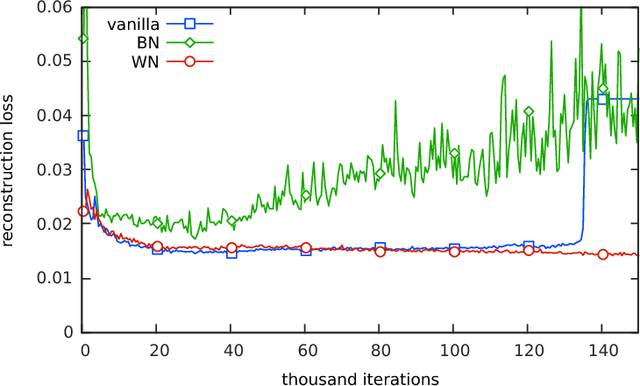


Generative adversarial networks (GANs) are highly effective unsupervised learning frameworks that can generate very sharp data, even for data such as images with complex, highly multimodal distributions. However GANs are known to be very hard to train, suffering from problems such as mode collapse and disturbing visual artifacts. Batch normalization (BN) techniques have been introduced to address the training. Though BN accelerates the training in the beginning, our experiments show that the use of BN can be unstable and negatively impact the quality of the trained model. The evaluation of BN and numerous other recent schemes for improving GAN training is hindered by the lack of an effective objective quality measure for GAN models. To address these issues, we first introduce a weight normalization (WN) approach for GAN training that significantly improves the stability, efficiency and the quality of the generated samples. To allow a methodical evaluation, we introduce squared Euclidean reconstruction error on a test set as a new objective measure, to assess training performance in terms of speed, stability, and quality of generated samples. Our experiments with a standard DCGAN architecture on commonly used datasets (CelebA, LSUN bedroom, and CIFAR-10) indicate that training using WN is generally superior to BN for GANs, achieving 10% lower mean squared loss for reconstruction and significantly better qualitative results than BN. We further demonstrate the stability of WN on a 21-layer ResNet trained with the CelebA data set. The code for this paper is available at https://github.com/stormraiser/gan-weightnorm-resnet