 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Style and Content in Anime Illustrations
Paper and Code
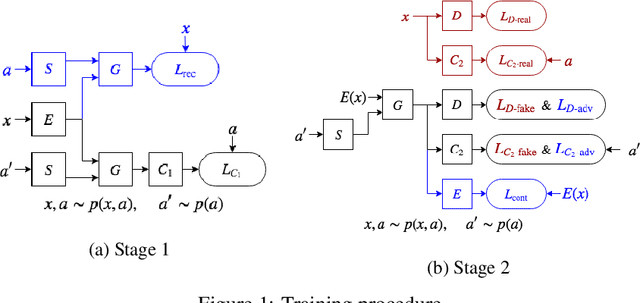

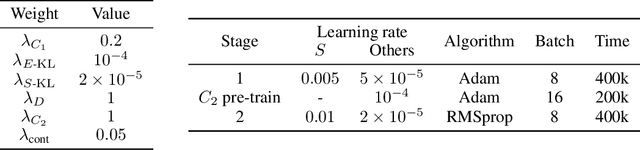

Existing methods for AI-generated artworks still struggle with generating high-quality stylized content, where high-level semantics are preserved, or separating fine-grained styles from various artists. We propose a novel Generative Adversarial Disentanglement Network which can fully decompose complex anime illustrations into style and content. Training such model is challenging, since given a style, various content data may exist but not the other way round. In particular, we disentangle two complementary factors of variations, where one of the factors is labelled. Our approach is divided into two stages, one that encodes an input image into a style independent content, and one based on a dual-conditional generator. We demonstrate the ability to generate high-fidelity anime portraits with a fixed content and a large variety of styles from over a thousand artists, and vice versa, using a single end-to-end network and with applications in style transfer. We show this unique capability as well as superior output to the current state-of-the-art.