 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiFSQ: Improving FSQ for Image Generation with 1 Line of Code
Jan 27, 2026The field of image generation is currently bifurcated into autoregressive (AR) models operating on discrete tokens and diffusion models utilizing continuous latents. This divide, rooted in the distinction between VQ-VAEs and VAEs, hinders unified modeling and fair benchmarking. Finite Scalar Quantization (FSQ) offers a theoretical bridge, yet vanilla FSQ suffers from a critical flaw: its equal-interval quantization can cause activation collapse. This mismatch forces a trade-off between reconstruction fidelity and information efficiency. In this work, we resolve this dilemma by simply replacing the activation function in original FSQ with a distribution-matching mapping to enforce a uniform prior. Termed iFSQ, this simple strategy requires just one line of code yet mathematically guarantees both optimal bin utilization and reconstruction precision. Leveraging iFSQ as a controlled benchmark, we uncover two key insights: (1) The optimal equilibrium between discrete and continuous representations lies at approximately 4 bits per dimension. (2) Under identical reconstruction constraints, AR models exhibit rapid initial convergence, whereas diffusion models achieve a superior performance ceiling, suggesting that strict sequential ordering may limit the upper bounds of generation quality. Finally, we extend our analysis by adapting Representation Alignment (REPA) to AR models, yielding LlamaGen-REPA. Codes is available at https://github.com/Tencent-Hunyuan/iFSQ
Can Understanding and Generation Truly Benefit Together -- or Just Coexist?
Sep 11, 2025



In this paper, we introduce an insightful paradigm through the Auto-Encoder lens-understanding as the encoder (I2T) that compresses images into text, and generation as the decoder (T2I) that reconstructs images from that text. Using reconstruction fidelity as the unified training objective, we enforce the coherent bidirectional information flow between the understanding and generation processes, bringing mutual gains. To implement this, we propose UAE, a novel framework for unified multimodal learning. We begin by pre-training the decoder with large-scale long-context image captions to capture fine-grained semantic and complex spatial relationships. We then propose Unified-GRPO via reinforcement learning (RL), which covers three stages: (1) A cold-start phase to gently initialize both encoder and decoder with a semantic reconstruction loss; (2) Generation for Understanding, where the encoder is trained to generate informative captions that maximize the decoder's reconstruction quality, enhancing its visual understanding; (3) Understanding for Generation, where the decoder is refined to reconstruct from these captions, forcing it to leverage every detail and improving its long-context instruction following and generation fidelity. For evaluation, we introduce Unified-Bench, the first benchmark tailored to assess the degree of unification of the UMMs. A surprising "aha moment" arises within the multimodal learning domain: as RL progresses, the encoder autonomously produces more descriptive captions, while the decoder simultaneously demonstrates a profound ability to understand these intricate descriptions, resulting in reconstructions of striking fidelity.
ImgEdit: A Unified Image Editing Dataset and Benchmark
May 26, 2025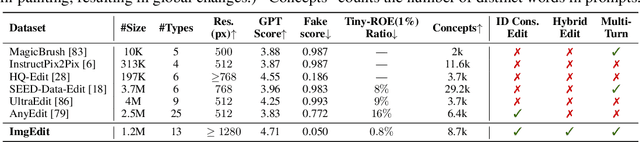
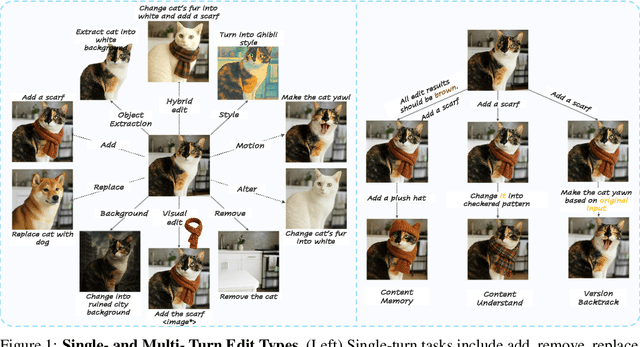
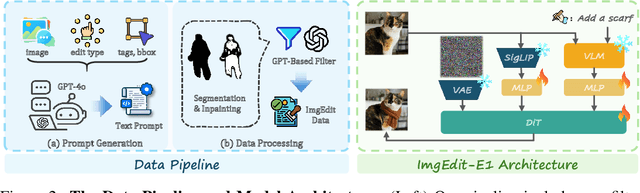

Recent advancements in generative models have enabled high-fidelity text-to-image generation. However, open-source image-editing models still lag behind their proprietary counterparts, primarily due to limited high-quality data and insufficient benchmarks. To overcome these limitations, we introduce ImgEdit, a large-scale, high-quality image-editing dataset comprising 1.2 million carefully curated edit pairs, which contain both novel and complex single-turn edits, as well as challenging multi-turn tasks. To ensure the data quality, we employ a multi-stage pipeline that integrates a cutting-edge vision-language model, a detection model, a segmentation model, alongside task-specific in-painting procedures and strict post-processing. ImgEdit surpasses existing datasets in both task novelty and data quality. Using ImgEdit, we train ImgEdit-E1, an editing model using Vision Language Model to process the reference image and editing prompt, which outperforms existing open-source models on multiple tasks, highlighting the value of ImgEdit and model design. For comprehensive evaluation, we introduce ImgEdit-Bench, a benchmark designed to evaluate image editing performance in terms of instruction adherence, editing quality, and detail preservation. It includes a basic testsuite, a challenging single-turn suite, and a dedicated multi-turn suite. We evaluate both open-source and proprietary models, as well as ImgEdit-E1, providing deep analysis and actionable insights into the current behavior of image-editing models. The source data are publicly available on https://github.com/PKU-YuanGroup/ImgEdit.
Bringing Diversity from Diffusion Models to Semantic-Guided Face Asset Generation
Apr 21, 2025

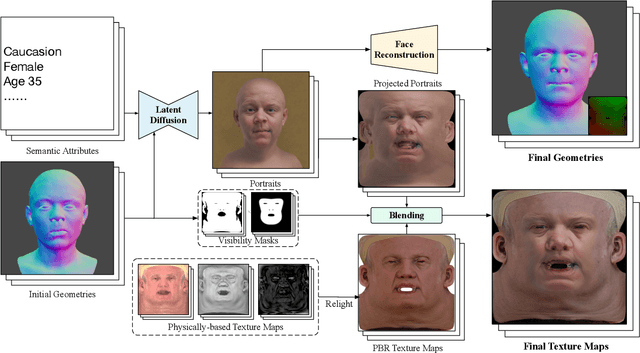

Digital modeling and reconstruction of human faces serve various applications. However, its availability is often hindered by the requirements of data capturing devices, manual labor, and suitable actors. This situation restricts the diversity, expressiveness, and control over the resulting models. This work aims to demonstrate that a semantically controllable generative network can provide enhanced control over the digital face modeling process. To enhance diversity beyond the limited human faces scanned in a controlled setting, we introduce a novel data generation pipeline that creates a high-quality 3D face database using a pre-trained diffusion model. Our proposed normalization module converts synthesized data from the diffusion model into high-quality scanned data. Using the 44,000 face models we obtained, we further developed an efficient GAN-based generator. This generator accepts semantic attributes as input, and generates geometry and albedo. It also allows continuous post-editing of attributes in the latent space. Our asset refinement component subsequently creates physically-based facial assets. We introduce a comprehensive system designed for creating and editing high-quality face assets. Our proposed model has undergone extensive experiment, comparison and evaluation. We also integrate everything into a web-based interactive tool. We aim to make this tool publicly available with the release of the paper.
Open-Sora Plan: Open-Source Large Video Generation Model
Nov 28, 2024



We introduce Open-Sora Plan, an open-source project that aims to contribute a large generation model for generating desired high-resolution videos with long durations based on various user inputs. Our project comprises multiple components for the entire video generation process, including a Wavelet-Flow Variational Autoencoder, a Joint Image-Video Skiparse Denoiser, and various condition controllers. Moreover, many assistant strategies for efficient training and inference are designed, and a multi-dimensional data curation pipeline is proposed for obtaining desired high-quality data. Benefiting from efficient thoughts, our Open-Sora Plan achieves impressive video generation results in both qualitative and quantitative evaluations. We hope our careful design and practical experience can inspire the video generation research community. All our codes and model weights are publicly available at \url{https://github.com/PKU-YuanGroup/Open-Sora-Plan}.
WF-VAE: Enhancing Video VAE by Wavelet-Driven Energy Flow for Latent Video Diffusion Model
Nov 26, 2024Video Variational Autoencoder (VAE) encodes videos into a low-dimensional latent space, becoming a key component of most Latent Video Diffusion Models (LVDMs) to reduce model training costs. However, as the resolution and duration of generated videos increase, the encoding cost of Video VAEs becomes a limiting bottleneck in training LVDMs. Moreover, the block-wise inference method adopted by most LVDMs can lead to discontinuities of latent space when processing long-duration videos. The key to addressing the computational bottleneck lies in decomposing videos into distinct components and efficiently encoding the critical information. Wavelet transform can decompose videos into multiple frequency-domain components and improve the efficiency significantly, we thus propose Wavelet Flow VAE (WF-VAE), an autoencoder that leverages multi-level wavelet transform to facilitate low-frequency energy flow into latent representation. Furthermore, we introduce a method called Causal Cache, which maintains the integrity of latent space during block-wise inference. Compared to state-of-the-art video VAEs, WF-VAE demonstrates superior performance in both PSNR and LPIPS metrics, achieving 2x higher throughput and 4x lower memory consumption while maintaining competitive reconstruction quality. Our code and models are available at https://github.com/PKU-YuanGroup/WF-VAE.
OD-VAE: An Omni-dimensional Video Compressor for Improving Latent Video Diffusion Model
Sep 02, 2024Variational Autoencoder (VAE), compressing videos into latent representations, is a crucial preceding component of Latent Video Diffusion Models (LVDMs). With the same reconstruction quality, the more sufficient the VAE's compression for videos is, the more efficient the LVDMs are. However, most LVDMs utilize 2D image VAE, whose compression for videos is only in the spatial dimension and often ignored in the temporal dimension. How to conduct temporal compression for videos in a VAE to obtain more concise latent representations while promising accurate reconstruction is seldom explored. To fill this gap, we propose an omni-dimension compression VAE, named OD-VAE, which can temporally and spatially compress videos. Although OD-VAE's more sufficient compression brings a great challenge to video reconstruction, it can still achieve high reconstructed accuracy by our fine design. To obtain a better trade-off between video reconstruction quality and compression speed, four variants of OD-VAE are introduced and analyzed. In addition, a novel tail initialization is designed to train OD-VAE more efficiently, and a novel inference strategy is proposed to enable OD-VAE to handle videos of arbitrary length with limited GPU memory. Comprehensive experiments on video reconstruction and LVDM-based video generation demonstrate the effectiveness and efficiency of our proposed methods.
AGFSync: Leveraging AI-Generated Feedback for Preference Optimization in Text-to-Image Generation
Mar 24, 2024
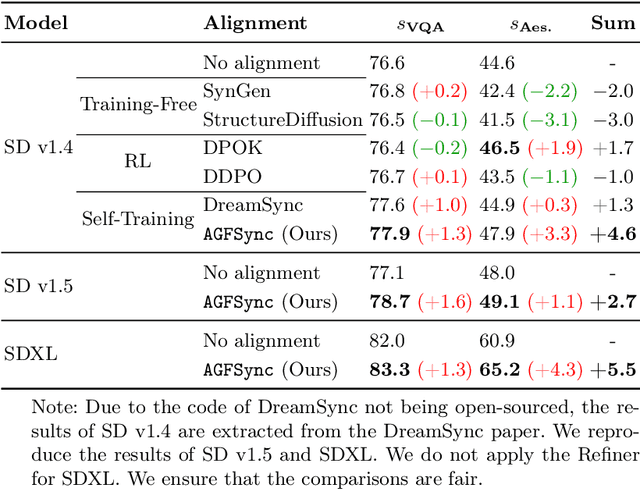
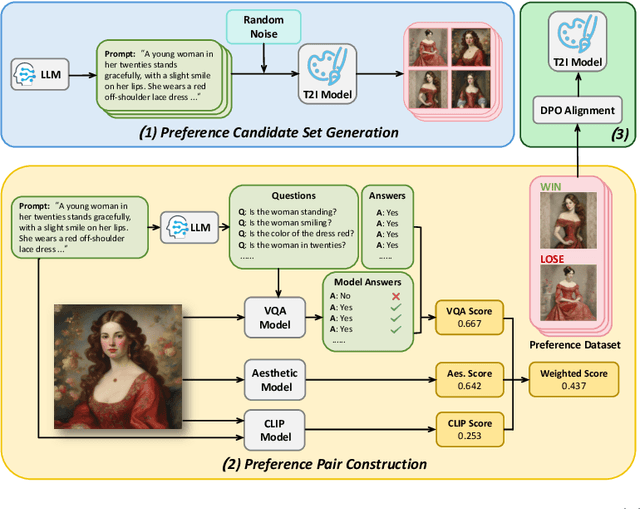
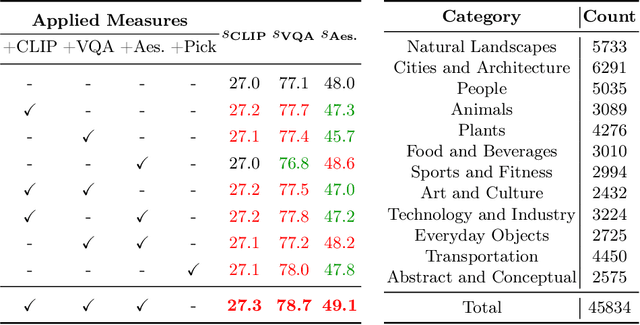
Text-to-Image (T2I) diffusion models have achieved remarkable success in image generation. Despite their progress, challenges remain in both prompt-following ability, image quality and lack of high-quality datasets, which are essential for refining these models. As acquiring labeled data is costly, we introduce AGFSync, a framework that enhances T2I diffusion models through Direct Preference Optimization (DPO) in a fully AI-driven approach. AGFSync utilizes Vision-Language Models (VLM) to assess image quality across style, coherence, and aesthetics, generating feedback data within an AI-driven loop. By applying AGFSync to leading T2I models such as SD v1.4, v1.5, and SDXL, our extensive experiments on the TIFA dataset demonstrate notable improvements in VQA scores, aesthetic evaluations, and performance on the HPSv2 benchmark, consistently outperforming the base models. AGFSync's method of refining T2I diffusion models paves the way for scalable alignment techniques.
LibreFace: An Open-Source Toolkit for Deep Facial Expression Analysis
Aug 24, 2023



Facial expression analysis is an important tool for human-computer interaction. In this paper, we introduce LibreFace, an open-source toolkit for facial expression analysis. This open-source toolbox offers real-time and offline analysis of facial behavior through deep learning models, including facial action unit (AU) detection, AU intensity estimation, and facial expression recognition. To accomplish this, we employ several techniques, including the utilization of a large-scale pre-trained network, feature-wise knowledge distillation, and task-specific fine-tuning. These approaches are designed to effectively and accurately analyze facial expressions by leveraging visual information, thereby facilitating the implementation of real-time interactive applications. In terms of Action Unit (AU) intensity estimation, we achieve a Pearson Correlation Coefficient (PCC) of 0.63 on DISFA, which is 7% higher than the performance of OpenFace 2.0 while maintaining highly-efficient inference that runs two times faster than OpenFace 2.0. Despite being compact, our model also demonstrates competitive performance to state-of-the-art facial expression analysis methods on AffecNet, FFHQ, and RAF-DB. Our code will be released at https://github.com/ihp-lab/LibreFace
ChatLaw: Open-Source Legal Large Language Model with Integrated External Knowledge Bases
Jun 28, 2023Large Language Models (LLMs) have shown the potential to revolutionize natural language processing tasks in various domains, sparking great interest in vertical-specific large models. However, unlike proprietary models such as BloombergGPT and FinGPT, which have leveraged their unique data accumulations to make strides in the finance domain, there hasn't not many similar large language models in the Chinese legal domain to facilitate its digital transformation. In this paper, we propose an open-source legal large language model named ChatLaw. Due to the importance of data quality, we carefully designed a legal domain fine-tuning dataset. Additionally, to overcome the problem of model hallucinations in legal data screening during reference data retrieval, we introduce a method that combines vector database retrieval with keyword retrieval to effectively reduce the inaccuracy of relying solely on vector database retrieval. Furthermore, we propose a self-attention method to enhance the ability of large models to overcome errors present in reference data, further optimizing the issue of model hallucinations at the model level and improving the problem-solving capabilities of large models. We also open-sourced our model and part of the data at https://github.com/PKU-YuanGroup/ChatLaw.