 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoila: Voice-Language Foundation Models for Real-Time Autonomous Interaction and Voice Role-Play
May 05, 2025A voice AI agent that blends seamlessly into daily life would interact with humans in an autonomous, real-time, and emotionally expressive manner. Rather than merely reacting to commands, it would continuously listen, reason, and respond proactively, fostering fluid, dynamic, and emotionally resonant interactions. We introduce Voila, a family of large voice-language foundation models that make a step towards this vision. Voila moves beyond traditional pipeline systems by adopting a new end-to-end architecture that enables full-duplex, low-latency conversations while preserving rich vocal nuances such as tone, rhythm, and emotion. It achieves a response latency of just 195 milliseconds, surpassing the average human response time. Its hierarchical multi-scale Transformer integrates the reasoning capabilities of large language models (LLMs) with powerful acoustic modeling, enabling natural, persona-aware voice generation -- where users can simply write text instructions to define the speaker's identity, tone, and other characteristics. Moreover, Voila supports over one million pre-built voices and efficient customization of new ones from brief audio samples as short as 10 seconds. Beyond spoken dialogue, Voila is designed as a unified model for a wide range of voice-based applications, including automatic speech recognition (ASR), Text-to-Speech (TTS), and, with minimal adaptation, multilingual speech translation. Voila is fully open-sourced to support open research and accelerate progress toward next-generation human-machine interactions.
Pandora: Towards General World Model with Natural Language Actions and Video States
Jun 12, 2024



World models simulate future states of the world in response to different actions. They facilitate interactive content creation and provides a foundation for grounded, long-horizon reasoning. Current foundation models do not fully meet the capabilities of general world models: large language models (LLMs) are constrained by their reliance on language modality and their limited understanding of the physical world, while video models lack interactive action control over the world simulations. This paper makes a step towards building a general world model by introducing Pandora, a hybrid autoregressive-diffusion model that simulates world states by generating videos and allows real-time control with free-text actions. Pandora achieves domain generality, video consistency, and controllability through large-scale pretraining and instruction tuning. Crucially, Pandora bypasses the cost of training-from-scratch by integrating a pretrained LLM (7B) and a pretrained video model, requiring only additional lightweight finetuning. We illustrate extensive outputs by Pandora across diverse domains (indoor/outdoor, natural/urban, human/robot, 2D/3D, etc.). The results indicate great potential of building stronger general world models with larger-scale training.
VISION2UI: A Real-World Dataset with Layout for Code Generation from UI Designs
Apr 09, 2024Automatically generating UI code from webpage design visions can significantly alleviate the burden of developers, enabling beginner developers or designers to directly generate Web pages from design diagrams. Currently, prior research has accomplished the objective of generating UI code from rudimentary design visions or sketches through designing deep neural networks. Inspired by the groundbreaking advancements achieved by Multimodal Large Language Models (MLLMs), the automatic generation of UI code from high-fidelity design images is now emerging as a viable possibility. Nevertheless, our investigation reveals that existing MLLMs are hampered by the scarcity of authentic, high-quality, and large-scale datasets, leading to unsatisfactory performance in automated UI code generation. To mitigate this gap, we present a novel dataset, termed VISION2UI, extracted from real-world scenarios, augmented with comprehensive layout information, tailored specifically for finetuning MLLMs in UI code generation. Specifically, this dataset is derived through a series of operations, encompassing collecting, cleaning, and filtering of the open-source Common Crawl dataset. In order to uphold its quality, a neural scorer trained on labeled samples is utilized to refine the data, retaining higher-quality instances. Ultimately, this process yields a dataset comprising 2,000 (Much more is coming soon) parallel samples encompassing design visions and UI code. The dataset is available at https://huggingface.co/datasets/xcodemind/vision2ui.
AGFSync: Leveraging AI-Generated Feedback for Preference Optimization in Text-to-Image Generation
Mar 24, 2024
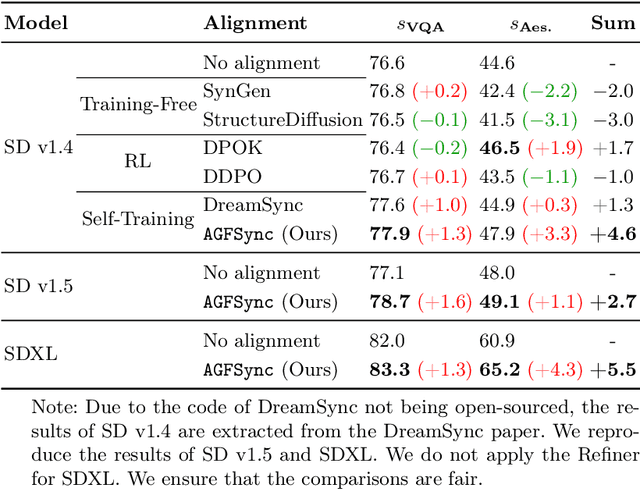
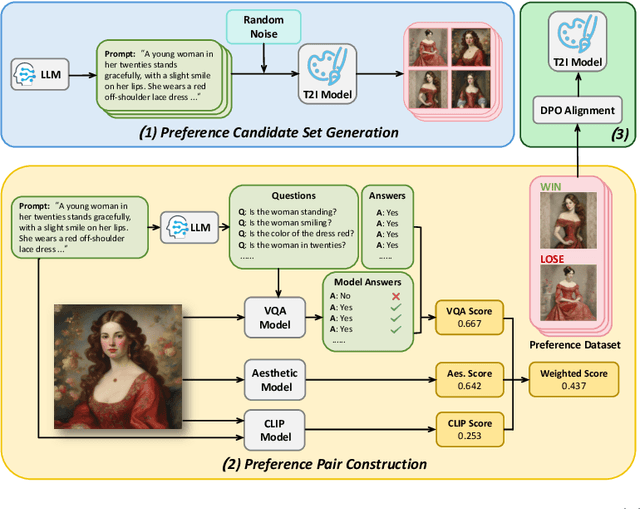
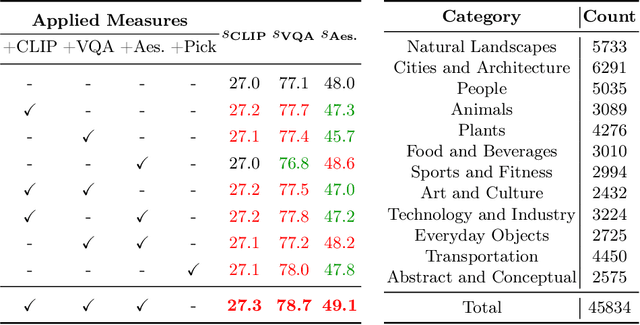
Text-to-Image (T2I) diffusion models have achieved remarkable success in image generation. Despite their progress, challenges remain in both prompt-following ability, image quality and lack of high-quality datasets, which are essential for refining these models. As acquiring labeled data is costly, we introduce AGFSync, a framework that enhances T2I diffusion models through Direct Preference Optimization (DPO) in a fully AI-driven approach. AGFSync utilizes Vision-Language Models (VLM) to assess image quality across style, coherence, and aesthetics, generating feedback data within an AI-driven loop. By applying AGFSync to leading T2I models such as SD v1.4, v1.5, and SDXL, our extensive experiments on the TIFA dataset demonstrate notable improvements in VQA scores, aesthetic evaluations, and performance on the HPSv2 benchmark, consistently outperforming the base models. AGFSync's method of refining T2I diffusion models paves the way for scalable alignment techniques.
AutoAgents: A Framework for Automatic Agent Generation
Oct 15, 2023



Large language models (LLMs) have enabled remarkable advances in automated task-solving with multi-agent systems. However, most existing LLM-based multi-agent approaches rely on predefined agents to handle simple tasks, limiting the adaptability of multi-agent collaboration to different scenarios. Therefore, we introduce AutoAgents, an innovative framework that adaptively generates and coordinates multiple specialized agents to build an AI team according to different tasks. Specifically, AutoAgents couples the relationship between tasks and roles by dynamically generating multiple required agents based on task content and planning solutions for the current task based on the generated expert agents. Multiple specialized agents collaborate with each other to efficiently accomplish tasks. Concurrently, an observer role is incorporated into the framework to reflect on the designated plans and agents' responses and improve upon them. Our experiments on various benchmarks demonstrate that AutoAgents generates more coherent and accurate solutions than the existing multi-agent methods. This underscores the significance of assigning different roles to different tasks and of team cooperation, offering new perspectives for tackling complex tasks. The repository of this project is available at https://github.com/Link-AGI/AutoAgents.
LLaSM: Large Language and Speech Model
Sep 16, 2023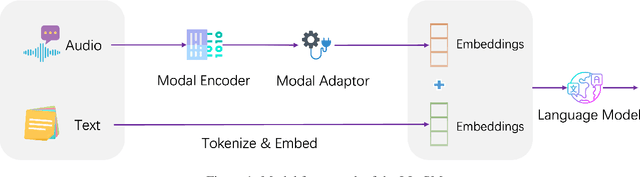

Multi-modal large language models have garnered significant interest recently. Though, most of the works focus on vision-language multi-modal models providing strong capabilities in following vision-and-language instructions. However, we claim that speech is also an important modality through which humans interact with the world. Hence, it is crucial for a general-purpose assistant to be able to follow multi-modal speech-and-language instructions. In this work, we propose Large Language and Speech Model (LLaSM). LLaSM is an end-to-end trained large multi-modal speech-language model with cross-modal conversational abilities, capable of following speech-and-language instructions. Our early experiments show that LLaSM demonstrates a more convenient and natural way for humans to interact with artificial intelligence. Specifically, we also release a large Speech Instruction Following dataset LLaSM-Audio-Instructions. Code and demo are available at https://github.com/LinkSoul-AI/LLaSM and https://huggingface.co/spaces/LinkSoul/LLaSM. The LLaSM-Audio-Instructions dataset is available at https://huggingface.co/datasets/LinkSoul/LLaSM-Audio-Instructions.
MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training
Jun 06, 2023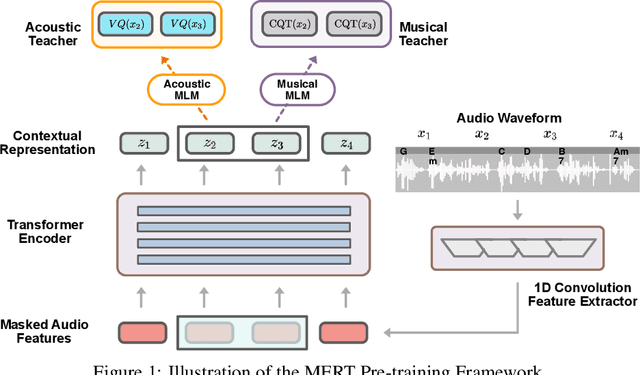
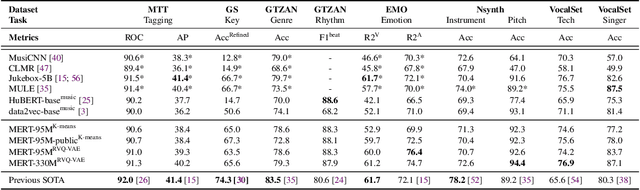
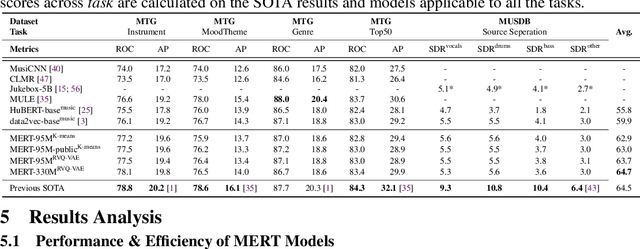
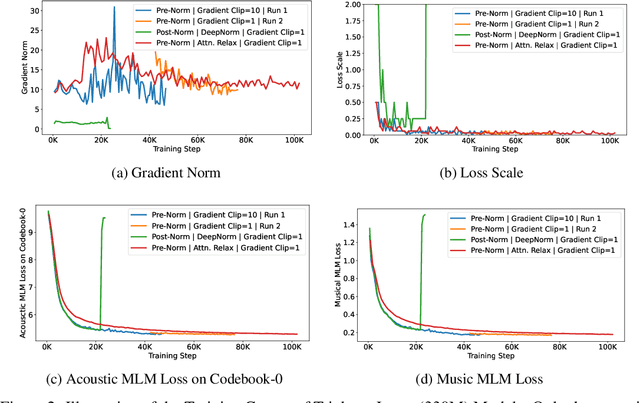
Self-supervised learning (SSL) has recently emerged as a promising paradigm for training generalisable models on large-scale data in the fields of vision, text, and speech. Although SSL has been proven effective in speech and audio, its application to music audio has yet to be thoroughly explored. This is primarily due to the distinctive challenges associated with modelling musical knowledge, particularly its tonal and pitched characteristics of music. To address this research gap, we propose an acoustic Music undERstanding model with large-scale self-supervised Training (MERT), which incorporates teacher models to provide pseudo labels in the masked language modelling (MLM) style acoustic pre-training. In our exploration, we identified a superior combination of teacher models, which outperforms conventional speech and audio approaches in terms of performance. This combination includes an acoustic teacher based on Residual Vector Quantization - Variational AutoEncoder (RVQ-VAE) and a musical teacher based on the Constant-Q Transform (CQT). These teachers effectively guide our student model, a BERT-style transformer encoder, to better model music audio. In addition, we introduce an in-batch noise mixture augmentation to enhance the representation robustness. Furthermore, we explore a wide range of settings to overcome the instability in acoustic language model pre-training, which allows our designed paradigm to scale from 95M to 330M parameters. Experimental results indicate that our model can generalise and perform well on 14 music understanding tasks and attains state-of-the-art (SOTA) overall scores. The code and models are online: https://github.com/yizhilll/MERT.
Chinese Open Instruction Generalist: A Preliminary Release
Apr 25, 2023



Instruction tuning is widely recognized as a key technique for building generalist language models, which has attracted the attention of researchers and the public with the release of InstructGPT~\citep{ouyang2022training} and ChatGPT\footnote{\url{https://chat.openai.com/}}. Despite impressive progress in English-oriented large-scale language models (LLMs), it is still under-explored whether English-based foundation LLMs can perform similarly on multilingual tasks compared to English tasks with well-designed instruction tuning and how we can construct the corpora needed for the tuning. To remedy this gap, we propose the project as an attempt to create a Chinese instruction dataset by various methods adapted to the intrinsic characteristics of 4 sub-tasks. We collect around 200k Chinese instruction tuning samples, which have been manually checked to guarantee high quality. We also summarize the existing English and Chinese instruction corpora and briefly describe some potential applications of the newly constructed Chinese instruction corpora. The resulting \textbf{C}hinese \textbf{O}pen \textbf{I}nstruction \textbf{G}eneralist (\textbf{COIG}) corpora are available in Huggingface\footnote{\url{https://huggingface.co/datasets/BAAI/COIG}} and Github\footnote{\url{https://github.com/BAAI-Zlab/COIG}}, and will be continuously updated.
Identification of Pediatric Respiratory Diseases Using Fine-grained Diagnosis System
Aug 24, 2021
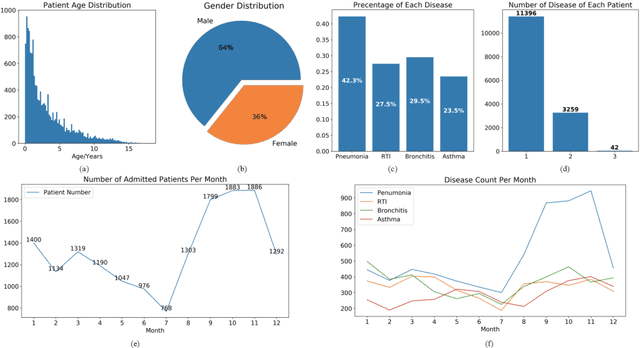
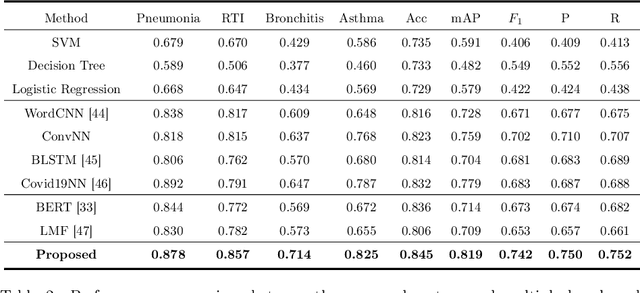
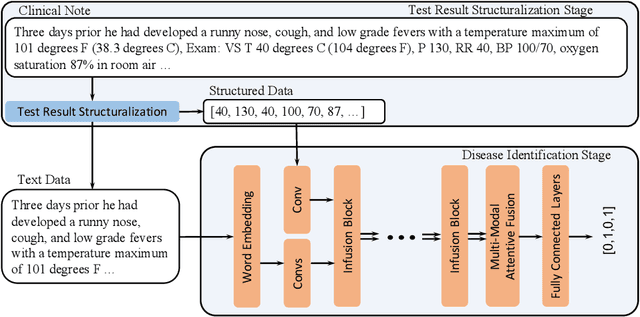
Respiratory diseases, including asthma, bronchitis, pneumonia, and upper respiratory tract infection (RTI), are among the most common diseases in clinics. The similarities among the symptoms of these diseases precludes prompt diagnosis upon the patients' arrival. In pediatrics, the patients' limited ability in expressing their situation makes precise diagnosis even harder. This becomes worse in primary hospitals, where the lack of medical imaging devices and the doctors' limited experience further increase the difficulty of distinguishing among similar diseases. In this paper, a pediatric fine-grained diagnosis-assistant system is proposed to provide prompt and precise diagnosis using solely clinical notes upon admission, which would assist clinicians without changing the diagnostic process. The proposed system consists of two stages: a test result structuralization stage and a disease identification stage. The first stage structuralizes test results by extracting relevant numerical values from clinical notes, and the disease identification stage provides a diagnosis based on text-form clinical notes and the structured data obtained from the first stage. A novel deep learning algorithm was developed for the disease identification stage, where techniques including adaptive feature infusion and multi-modal attentive fusion were introduced to fuse structured and text data together. Clinical notes from over 12000 patients with respiratory diseases were used to train a deep learning model, and clinical notes from a non-overlapping set of about 1800 patients were used to evaluate the performance of the trained model. The average precisions (AP) for pneumonia, RTI, bronchitis and asthma are 0.878, 0.857, 0.714, and 0.825, respectively, achieving a mean AP (mAP) of 0.819.
Cross-Domain Adaptive Clustering for Semi-Supervised Domain Adaptation
Apr 19, 2021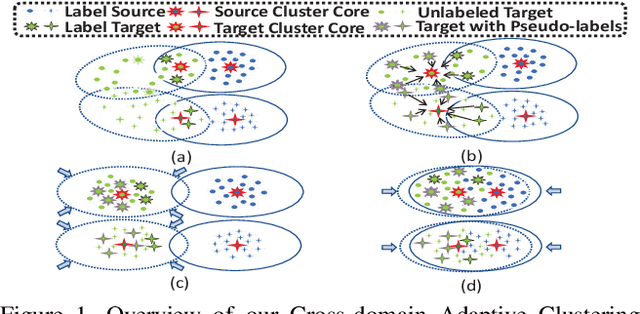
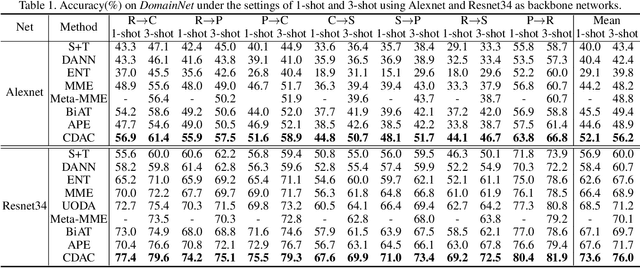
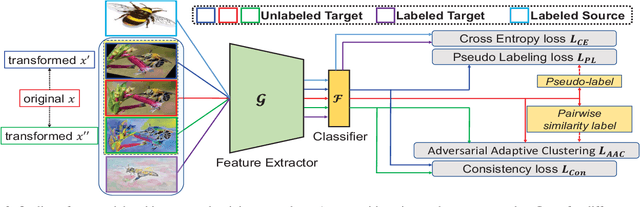
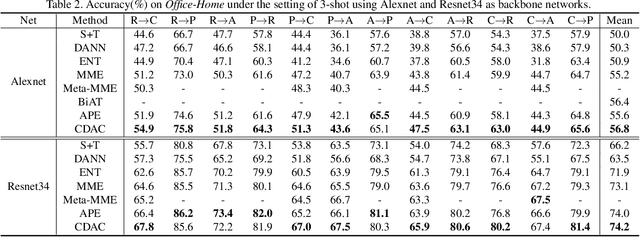
In semi-supervised domain adaptation, a few labeled samples per class in the target domain guide features of the remaining target samples to aggregate around them. However, the trained model cannot produce a highly discriminative feature representation for the target domain because the training data is dominated by labeled samples from the source domain. This could lead to disconnection between the labeled and unlabeled target samples as well as misalignment between unlabeled target samples and the source domain. In this paper, we propose a novel approach called Cross-domain Adaptive Clustering to address this problem. To achieve both inter-domain and intra-domain adaptation, we first introduce an adversarial adaptive clustering loss to group features of unlabeled target data into clusters and perform cluster-wise feature alignment across the source and target domains. We further apply pseudo labeling to unlabeled samples in the target domain and retain pseudo-labels with high confidence. Pseudo labeling expands the number of ``labeled" samples in each class in the target domain, and thus produces a more robust and powerful cluster core for each class to facilitate adversarial learning. Extensive experiments on benchmark datasets, including DomainNet, Office-Home and Office, demonstrate that our proposed approach achieves the state-of-the-art performance in semi-supervised domain adaptation.