 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAFD-INSTRUCTION: A Comprehensive Antibody Instruction Dataset with Functional Annotations for LLM-Based Understanding and Design
Feb 04, 2026Large language models (LLMs) have significantly advanced protein representation learning. However, their capacity to interpret and design antibodies through natural language remains limited. To address this challenge, we present AFD-Instruction, the first large-scale instruction dataset with functional annotations tailored to antibodies. This dataset encompasses two key components: antibody understanding, which infers functional attributes directly from sequences, and antibody design, which enables de novo sequence generation under functional constraints. These components provide explicit sequence-function alignment and support antibody design guided by natural language instructions. Extensive instruction-tuning experiments on general-purpose LLMs demonstrate that AFD-Instruction consistently improves performance across diverse antibody-related tasks. By linking antibody sequences with textual descriptions of function, AFD-Instruction establishes a new foundation for advancing antibody modeling and accelerating therapeutic discovery.
Switchcodec: Adaptive residual-expert sparse quantization for high-fidelity neural audio coding
Jan 28, 2026Recent neural audio compression models often rely on residual vector quantization for high-fidelity coding, but using a fixed number of per-frame codebooks is suboptimal for the wide variability of audio content-especially for signals that are either very simple or highly complex. To address this limitation, we propose SwitchCodec, a neural audio codec based on Residual Experts Vector Quantization (REVQ). REVQ combines a shared quantizer with dynamically routed expert quantizers that are activated according to the input audio, decoupling bitrate from codebook capacity and improving compression efficiency. This design ensures full training and utilization of each quantizer. In addition, a variable-bitrate mechanism adjusts the number of active expert quantizers at inference, enabling multi-bitrate operation without retraining. Experiments demonstrate that SwitchCodec surpasses existing baselines on both objective metrics and subjective listening tests.
SwitchCodec: A High-Fidelity Nerual Audio Codec With Sparse Quantization
May 30, 2025We present a universal high-fidelity neural audio compression algorithm that can compress speech, music, and general audio below 3 kbps bandwidth. Although current state-of-the-art audio codecs excel in audio compression, their effectiveness significantly declines when embedding space is sharply reduced, which corresponds to higher compression. To address this problem, we propose Residual Experts Vector Quantization (REVQ), which significantly expands the available embedding space and improves the performance while hardly sacrificing the bandwidth. Furthermore, we introduce a strategy to ensure that the vast embedding space can be fully utilized. Additionally, we propose a STFT-based discriminator to guide the generator in producing indistinguishable spectrograms. We demonstrate that the proposed approach outperforms baseline methods through detailed ablations.
Problem-Solving Logic Guided Curriculum In-Context Learning for LLMs Complex Reasoning
Feb 21, 2025In-context learning (ICL) can significantly enhance the complex reasoning capabilities of large language models (LLMs), with the key lying in the selection and ordering of demonstration examples. Previous methods typically relied on simple features to measure the relevance between examples. We argue that these features are not sufficient to reflect the intrinsic connections between examples. In this study, we propose a curriculum ICL strategy guided by problem-solving logic. We select demonstration examples by analyzing the problem-solving logic and order them based on curriculum learning. Specifically, we constructed a problem-solving logic instruction set based on the BREAK dataset and fine-tuned a language model to analyze the problem-solving logic of examples. Subsequently, we selected appropriate demonstration examples based on problem-solving logic and assessed their difficulty according to the number of problem-solving steps. In accordance with the principles of curriculum learning, we ordered the examples from easy to hard to serve as contextual prompts. Experimental results on multiple benchmarks indicate that our method outperforms previous ICL approaches in terms of performance and efficiency, effectively enhancing the complex reasoning capabilities of LLMs. Our project will be publicly available subsequently.
Process-Supervised Reinforcement Learning for Code Generation
Feb 03, 2025



Existing reinforcement learning strategies based on outcome supervision have proven effective in enhancing the performance of large language models(LLMs) for code generation. While reinforcement learning based on process supervision has shown great promise in handling multi-step reasoning tasks, its effectiveness in code generation remains largely underexplored and underjustified. The primary obstacle stems from the resource-intensive nature of constructing high-quality process-supervised data, which demands substantial human expertise and computational resources. In response to this challenge, we propose a "statement mutation/refactoring-compile and execution verification" strategy: mutating and refactoring code line-by-line through a teacher model, and utilizing compiler execution results to automatically label each line, resulting in line-by-line process-supervised data, which is pivotal for training a process-supervised reward model. The trained reward model is then integrated into the PRLCoder framework, followed by experimental validation on several benchmarks. Experimental results demonstrate that process-supervised reinforcement learning significantly surpasses methods relying solely on outcome supervision. Notably, in tackling complex code generation tasks, process-supervised reinforcement learning shows a clear advantage, ensuring both the integrity of the code generation process and the correctness of the generation results.
Multimodal Table Understanding
Jun 12, 2024



Although great progress has been made by previous table understanding methods including recent approaches based on large language models (LLMs), they rely heavily on the premise that given tables must be converted into a certain text sequence (such as Markdown or HTML) to serve as model input. However, it is difficult to access such high-quality textual table representations in some real-world scenarios, and table images are much more accessible. Therefore, how to directly understand tables using intuitive visual information is a crucial and urgent challenge for developing more practical applications. In this paper, we propose a new problem, multimodal table understanding, where the model needs to generate correct responses to various table-related requests based on the given table image. To facilitate both the model training and evaluation, we construct a large-scale dataset named MMTab, which covers a wide spectrum of table images, instructions and tasks. On this basis, we develop Table-LLaVA, a generalist tabular multimodal large language model (MLLM), which significantly outperforms recent open-source MLLM baselines on 23 benchmarks under held-in and held-out settings. The code and data is available at this https://github.com/SpursGoZmy/Table-LLaVA
VISION2UI: A Real-World Dataset with Layout for Code Generation from UI Designs
Apr 09, 2024Automatically generating UI code from webpage design visions can significantly alleviate the burden of developers, enabling beginner developers or designers to directly generate Web pages from design diagrams. Currently, prior research has accomplished the objective of generating UI code from rudimentary design visions or sketches through designing deep neural networks. Inspired by the groundbreaking advancements achieved by Multimodal Large Language Models (MLLMs), the automatic generation of UI code from high-fidelity design images is now emerging as a viable possibility. Nevertheless, our investigation reveals that existing MLLMs are hampered by the scarcity of authentic, high-quality, and large-scale datasets, leading to unsatisfactory performance in automated UI code generation. To mitigate this gap, we present a novel dataset, termed VISION2UI, extracted from real-world scenarios, augmented with comprehensive layout information, tailored specifically for finetuning MLLMs in UI code generation. Specifically, this dataset is derived through a series of operations, encompassing collecting, cleaning, and filtering of the open-source Common Crawl dataset. In order to uphold its quality, a neural scorer trained on labeled samples is utilized to refine the data, retaining higher-quality instances. Ultimately, this process yields a dataset comprising 2,000 (Much more is coming soon) parallel samples encompassing design visions and UI code. The dataset is available at https://huggingface.co/datasets/xcodemind/vision2ui.
A Two-Stage Training Framework for Joint Speech Compression and Enhancement
Sep 08, 2023
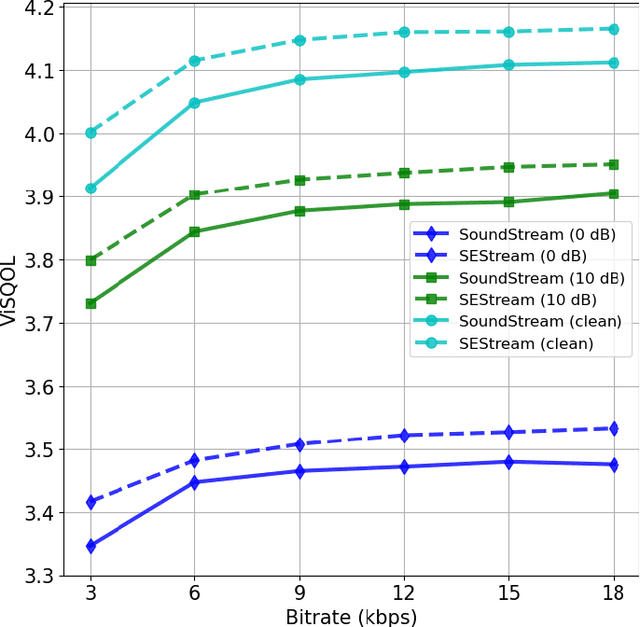
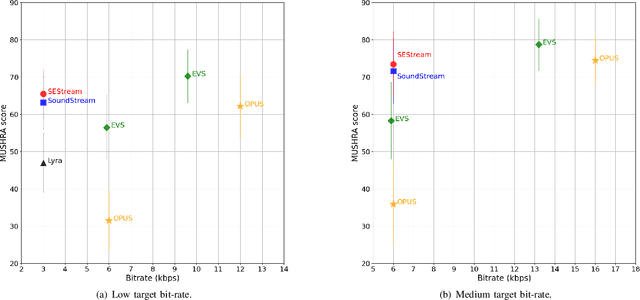
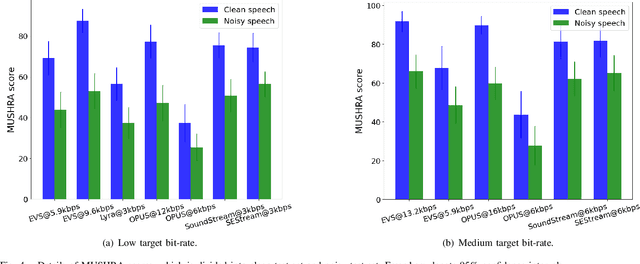
This paper considers the joint compression and enhancement problem for speech signal in the presence of noise. Recently, the SoundStream codec, which relies on end-to-end joint training of an encoder-decoder pair and a residual vector quantizer by a combination of adversarial and reconstruction losses,has shown very promising performance, especially in subjective perception quality. In this work, we provide a theoretical result to show that, to simultaneously achieve low distortion and high perception in the presence of noise, there exist an optimal two-stage optimization procedure for the joint compression and enhancement problem. This procedure firstly optimizes an encoder-decoder pair using only distortion loss and then fixes the encoder to optimize a perceptual decoder using perception loss. Based on this result, we construct a two-stage training framework for joint compression and enhancement of noisy speech signal. Unlike existing training methods which are heuristic, the proposed two-stage training method has a theoretical foundation. Finally, experimental results for various noise and bit-rate conditions are provided. The results demonstrate that a codec trained by the proposed framework can outperform SoundStream and other representative codecs in terms of both objective and subjective evaluation metrics. Code is available at \textit{https://github.com/jscscloris/SEStream}.
Improving Video Retrieval by Adaptive Margin
Mar 09, 2023Video retrieval is becoming increasingly important owing to the rapid emergence of videos on the Internet. The dominant paradigm for video retrieval learns video-text representations by pushing the distance between the similarity of positive pairs and that of negative pairs apart from a fixed margin. However, negative pairs used for training are sampled randomly, which indicates that the semantics between negative pairs may be related or even equivalent, while most methods still enforce dissimilar representations to decrease their similarity. This phenomenon leads to inaccurate supervision and poor performance in learning video-text representations. While most video retrieval methods overlook that phenomenon, we propose an adaptive margin changed with the distance between positive and negative pairs to solve the aforementioned issue. First, we design the calculation framework of the adaptive margin, including the method of distance measurement and the function between the distance and the margin. Then, we explore a novel implementation called "Cross-Modal Generalized Self-Distillation" (CMGSD), which can be built on the top of most video retrieval models with few modifications. Notably, CMGSD adds few computational overheads at train time and adds no computational overhead at test time. Experimental results on three widely used datasets demonstrate that the proposed method can yield significantly better performance than the corresponding backbone model, and it outperforms state-of-the-art methods by a large margin.
Neural Knowledge Bank for Pretrained Transformers
Aug 16, 2022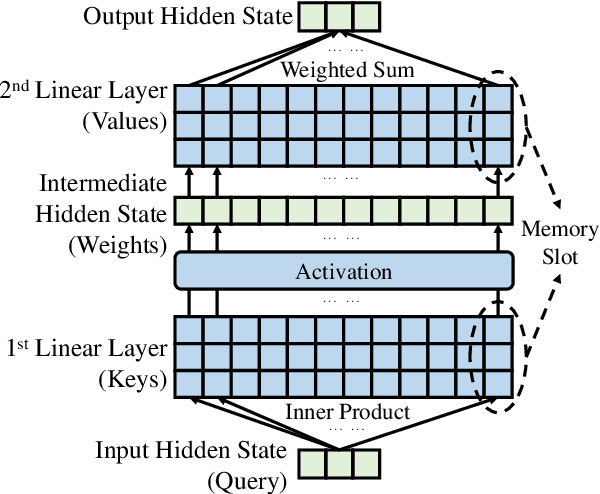
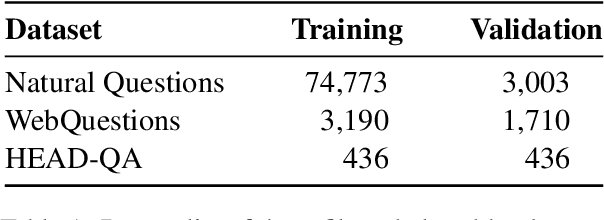
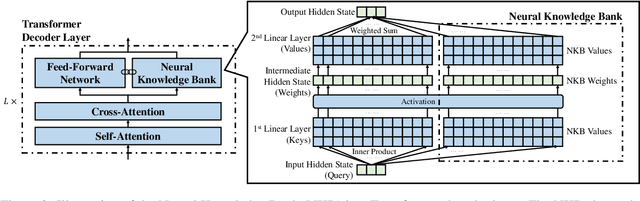
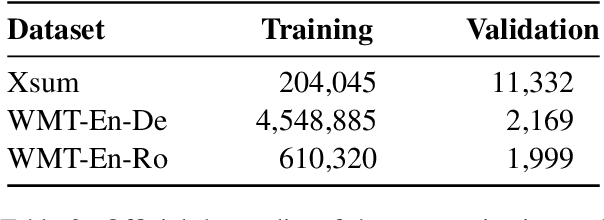
The ability of pretrained Transformers to remember factual knowledge is essential but still limited for existing models. Inspired by existing work that regards Feed-Forward Networks (FFNs) in Transformers as key-value memories, we design a Neural Knowledge Bank (NKB) and a knowledge injection strategy to introduce extra factual knowledge for pretrained Transformers. The NKB is in the form of additional knowledgeable memory slots to the FFN and the memory-like architecture makes it highly interpretable and flexible. When injecting extra knowledge with the Salient Span Masking (SSM) pretraining objective, we fix the original pretrained model and train only the NKB. This training strategy makes sure the general language modeling ability of the original pretrained model is not influenced. By mounting the NKB onto the T5 model, we verify its strong ability to store extra factual knowledge based on three closed-book question answering datasets. Also, we prove that mounting the NKB will not degrade the general language modeling ability of T5 through two representative tasks, summarization and machine translation. Further, we thoroughly analyze the interpretability of the NKB and reveal the meaning of its keys and values in a human-readable way. Finally, we show the flexibility of the NKB by directly modifying its value vectors to update the factual knowledge stored in it.