 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$k$NN Prompting: Beyond-Context Learning with Calibration-Free Nearest Neighbor Inference
Mar 24, 2023In-Context Learning (ICL), which formulates target tasks as prompt completion conditioned on in-context demonstrations, has become the prevailing utilization of LLMs. In this paper, we first disclose an actual predicament for this typical usage that it can not scale up with training data due to context length restriction. Besides, existing works have shown that ICL also suffers from various biases and requires delicate calibration treatment. To address both challenges, we advocate a simple and effective solution, $k$NN Prompting, which first queries LLM with training data for distributed representations, then predicts test instances by simply referring to nearest neighbors. We conduct comprehensive experiments to demonstrate its two-fold superiority: 1) Calibration-Free: $k$NN Prompting does not directly align LLM output distribution with task-specific label space, instead leverages such distribution to align test and training instances. It significantly outperforms state-of-the-art calibration-based methods under comparable few-shot scenario. 2) Beyond-Context: $k$NN Prompting can further scale up effectively with as many training data as are available, continually bringing substantial improvements. The scaling trend holds across 10 orders of magnitude ranging from 2 shots to 1024 shots as well as different LLMs scales ranging from 0.8B to 30B. It successfully bridges data scaling into model scaling, and brings new potentials for the gradient-free paradigm of LLM deployment. Code is publicly available.
* ICLR 2023. Code is available at https://github.com/BenfengXu/KNNPrompting
CLOP: Video-and-Language Pre-Training with Knowledge Regularizations
Nov 07, 2022Video-and-language pre-training has shown promising results for learning generalizable representations. Most existing approaches usually model video and text in an implicit manner, without considering explicit structural representations of the multi-modal content. We denote such form of representations as structural knowledge, which express rich semantics of multiple granularities. There are related works that propose object-aware approaches to inject similar knowledge as inputs. However, the existing methods usually fail to effectively utilize such knowledge as regularizations to shape a superior cross-modal representation space. To this end, we propose a Cross-modaL knOwledge-enhanced Pre-training (CLOP) method with Knowledge Regularizations. There are two key designs of ours: 1) a simple yet effective Structural Knowledge Prediction (SKP) task to pull together the latent representations of similar videos; and 2) a novel Knowledge-guided sampling approach for Contrastive Learning (KCL) to push apart cross-modal hard negative samples. We evaluate our method on four text-video retrieval tasks and one multi-choice QA task. The experiments show clear improvements, outperforming prior works by a substantial margin. Besides, we provide ablations and insights of how our methods affect the latent representation space, demonstrating the value of incorporating knowledge regularizations into video-and-language pre-training.
UPainting: Unified Text-to-Image Diffusion Generation with Cross-modal Guidance
Nov 03, 2022



Diffusion generative models have recently greatly improved the power of text-conditioned image generation. Existing image generation models mainly include text conditional diffusion model and cross-modal guided diffusion model, which are good at small scene image generation and complex scene image generation respectively. In this work, we propose a simple yet effective approach, namely UPainting, to unify simple and complex scene image generation, as shown in Figure 1. Based on architecture improvements and diverse guidance schedules, UPainting effectively integrates cross-modal guidance from a pretrained image-text matching model into a text conditional diffusion model that utilizes a pretrained Transformer language model as the text encoder. Our key findings is that combining the power of large-scale Transformer language model in understanding language and image-text matching model in capturing cross-modal semantics and style, is effective to improve sample fidelity and image-text alignment of image generation. In this way, UPainting has a more general image generation capability, which can generate images of both simple and complex scenes more effectively. To comprehensively compare text-to-image models, we further create a more general benchmark, UniBench, with well-written Chinese and English prompts in both simple and complex scenes. We compare UPainting with recent models and find that UPainting greatly outperforms other models in terms of caption similarity and image fidelity in both simple and complex scenes. UPainting project page \url{https://upainting.github.io/}.
HiSMatch: Historical Structure Matching based Temporal Knowledge Graph Reasoning
Oct 18, 2022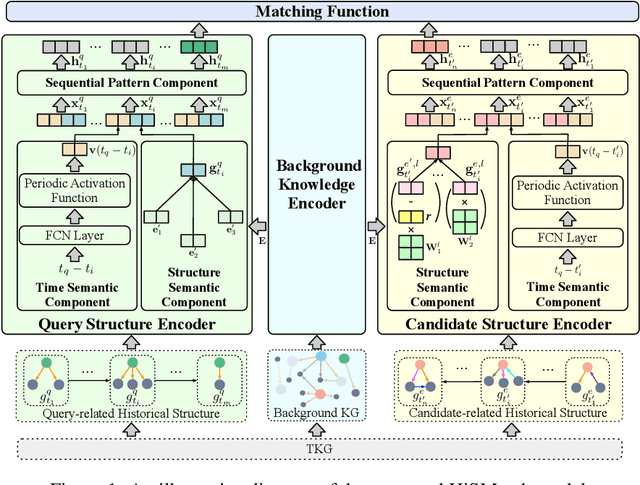
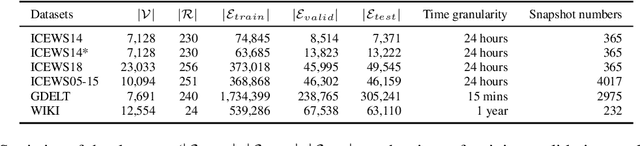
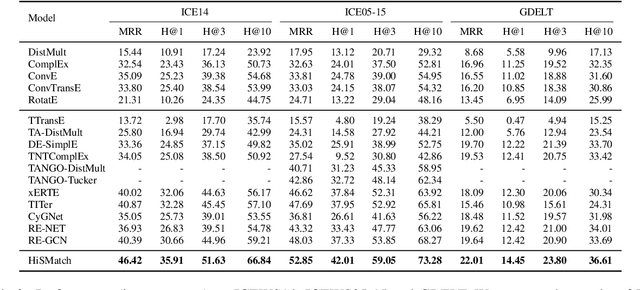
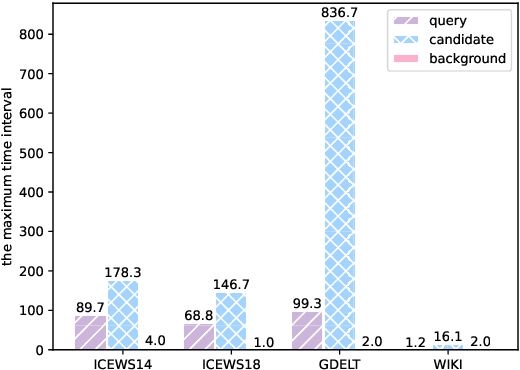
A Temporal Knowledge Graph (TKG) is a sequence of KGs with respective timestamps, which adopts quadruples in the form of (\emph{subject}, \emph{relation}, \emph{object}, \emph{timestamp}) to describe dynamic facts. TKG reasoning has facilitated many real-world applications via answering such queries as (\emph{query entity}, \emph{query relation}, \emph{?}, \emph{future timestamp}) about future. This is actually a matching task between a query and candidate entities based on their historical structures, which reflect behavioral trends of the entities at different timestamps. In addition, recent KGs provide background knowledge of all the entities, which is also helpful for the matching. Thus, in this paper, we propose the \textbf{Hi}storical \textbf{S}tructure \textbf{Match}ing (\textbf{HiSMatch}) model. It applies two structure encoders to capture the semantic information contained in the historical structures of the query and candidate entities. Besides, it adopts another encoder to integrate the background knowledge into the model. TKG reasoning experiments on six benchmark datasets demonstrate the significant improvement of the proposed HiSMatch model, with up to 5.6\% performance improvement in MRR, compared to the state-of-the-art baselines.
Neural Knowledge Bank for Pretrained Transformers
Aug 16, 2022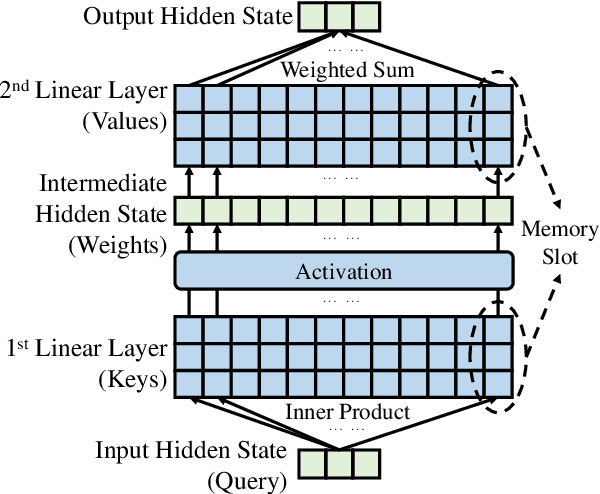
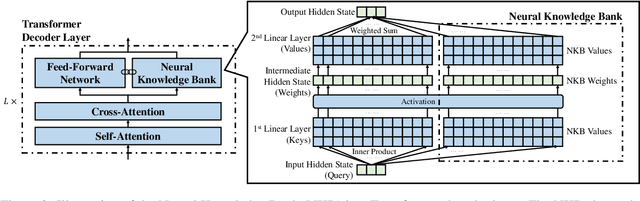
The ability of pretrained Transformers to remember factual knowledge is essential but still limited for existing models. Inspired by existing work that regards Feed-Forward Networks (FFNs) in Transformers as key-value memories, we design a Neural Knowledge Bank (NKB) and a knowledge injection strategy to introduce extra factual knowledge for pretrained Transformers. The NKB is in the form of additional knowledgeable memory slots to the FFN and the memory-like architecture makes it highly interpretable and flexible. When injecting extra knowledge with the Salient Span Masking (SSM) pretraining objective, we fix the original pretrained model and train only the NKB. This training strategy makes sure the general language modeling ability of the original pretrained model is not influenced. By mounting the NKB onto the T5 model, we verify its strong ability to store extra factual knowledge based on three closed-book question answering datasets. Also, we prove that mounting the NKB will not degrade the general language modeling ability of T5 through two representative tasks, summarization and machine translation. Further, we thoroughly analyze the interpretability of the NKB and reveal the meaning of its keys and values in a human-readable way. Finally, we show the flexibility of the NKB by directly modifying its value vectors to update the factual knowledge stored in it.
Mixture of Experts for Biomedical Question Answering
Apr 15, 2022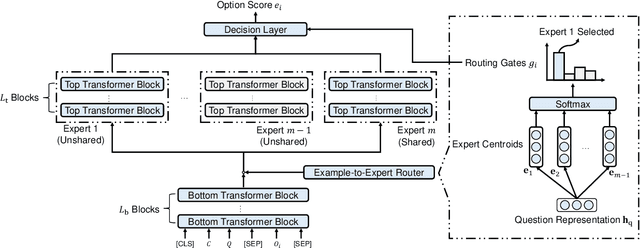
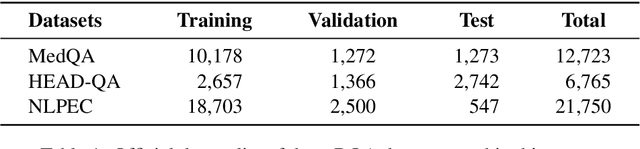

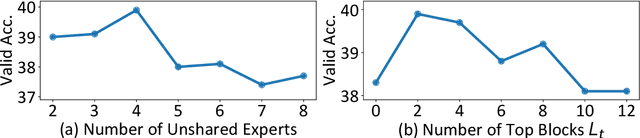
Biomedical Question Answering (BQA) has attracted increasing attention in recent years due to its promising application prospect. It is a challenging task because the biomedical questions are professional and usually vary widely. Existing question answering methods answer all questions with a homogeneous model, leading to various types of questions competing for the shared parameters, which will confuse the model decision for each single type of questions. In this paper, in order to alleviate the parameter competition problem, we propose a Mixture-of-Expert (MoE) based question answering method called MoEBQA that decouples the computation for different types of questions by sparse routing. To be specific, we split a pretrained Transformer model into bottom and top blocks. The bottom blocks are shared by all the examples, aiming to capture the general features. The top blocks are extended to an MoE version that consists of a series of independent experts, where each example is assigned to a few experts according to its underlying question type. MoEBQA automatically learns the routing strategy in an end-to-end manner so that each expert tends to deal with the question types it is expert in. We evaluate MoEBQA on three BQA datasets constructed based on real examinations. The results show that our MoE extension significantly boosts the performance of question answering models and achieves new state-of-the-art performance. In addition, we elaborately analyze our MoE modules to reveal how MoEBQA works and find that it can automatically group the questions into human-readable clusters.
Complex Evolutional Pattern Learning for Temporal Knowledge Graph Reasoning
Mar 20, 2022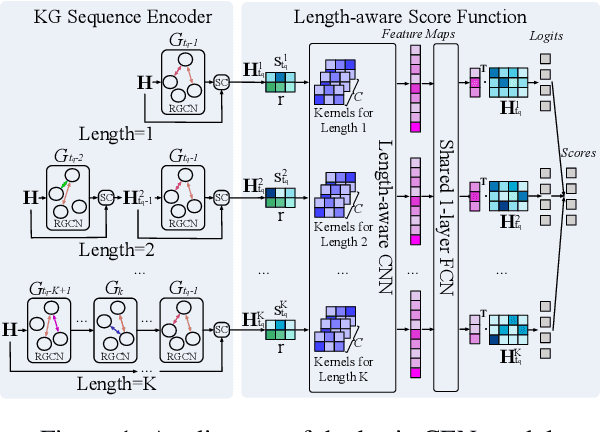
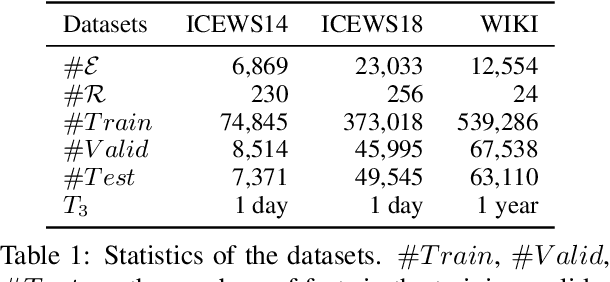
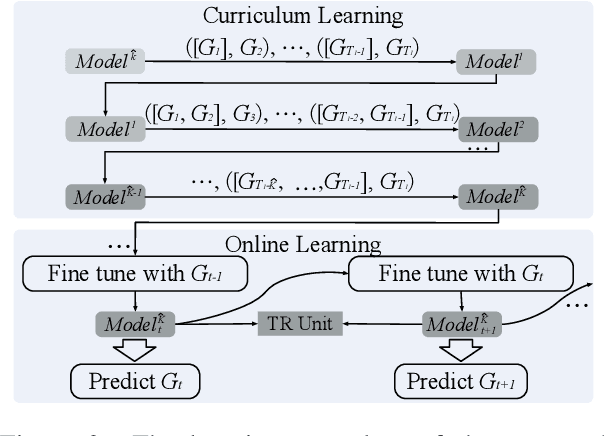
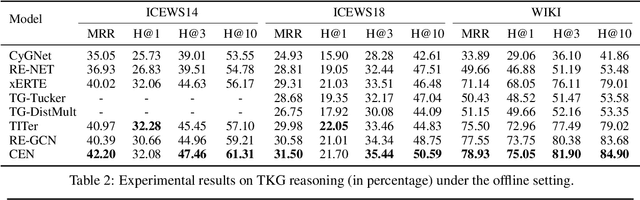
A Temporal Knowledge Graph (TKG) is a sequence of KGs corresponding to different timestamps. TKG reasoning aims to predict potential facts in the future given the historical KG sequences. One key of this task is to mine and understand evolutional patterns of facts from these sequences. The evolutional patterns are complex in two aspects, length-diversity and time-variability. Existing models for TKG reasoning focus on modeling fact sequences of a fixed length, which cannot discover complex evolutional patterns that vary in length. Furthermore, these models are all trained offline, which cannot well adapt to the changes of evolutional patterns from then on. Thus, we propose a new model, called Complex Evolutional Network (CEN), which uses a length-aware Convolutional Neural Network (CNN) to handle evolutional patterns of different lengths via an easy-to-difficult curriculum learning strategy. Besides, we propose to learn the model under the online setting so that it can adapt to the changes of evolutional patterns over time. Extensive experiments demonstrate that CEN obtains substantial performance improvement under both the traditional offline and the proposed online settings.
Building Chinese Biomedical Language Models via Multi-Level Text Discrimination
Oct 14, 2021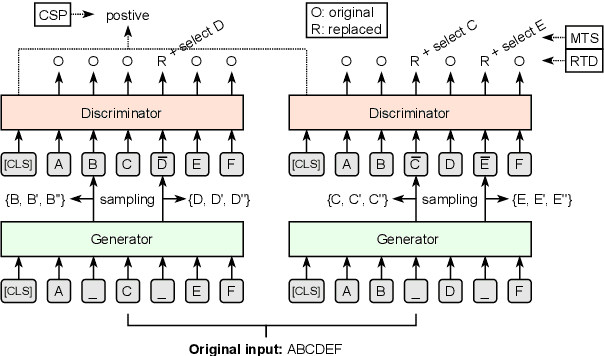

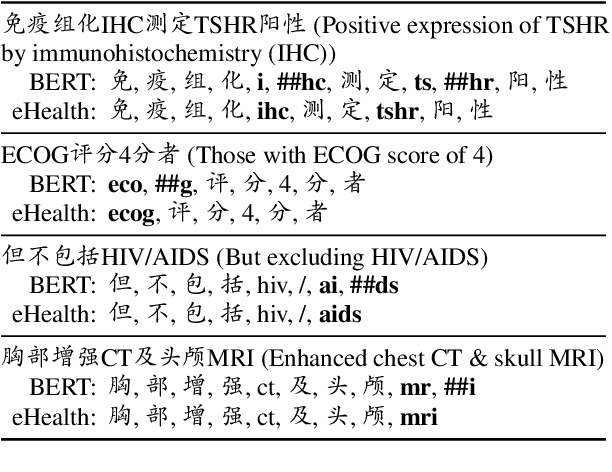
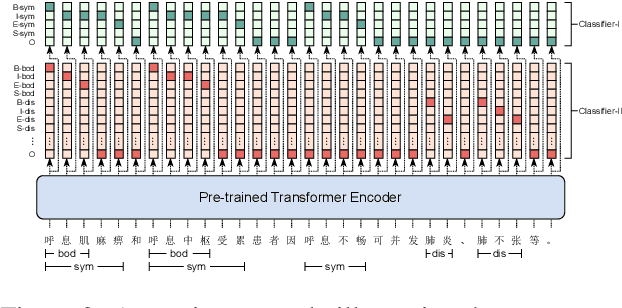
Pre-trained language models (PLMs), such as BERT and GPT, have revolutionized the field of NLP, not only in the general domain but also in the biomedical domain. Most prior efforts in building biomedical PLMs have resorted simply to domain adaptation and focused mainly on English. In this work we introduce eHealth, a biomedical PLM in Chinese built with a new pre-training framework. This new framework trains eHealth as a discriminator through both token-level and sequence-level discrimination. The former is to detect input tokens corrupted by a generator and select their original signals from plausible candidates, while the latter is to further distinguish corruptions of a same original sequence from those of the others. As such, eHealth can learn language semantics at both the token and sequence levels. Extensive experiments on 11 Chinese biomedical language understanding tasks of various forms verify the effectiveness and superiority of our approach. The pre-trained model is available to the public at \url{https://github.com/PaddlePaddle/Research/tree/master/KG/eHealth} and the code will also be released later.
Link Prediction on N-ary Relational Facts: A Graph-based Approach
May 18, 2021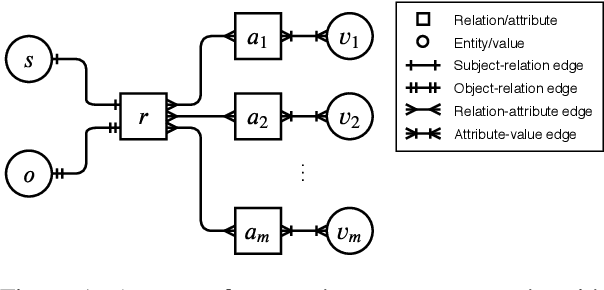
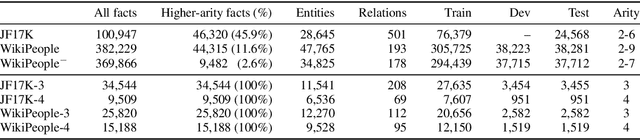
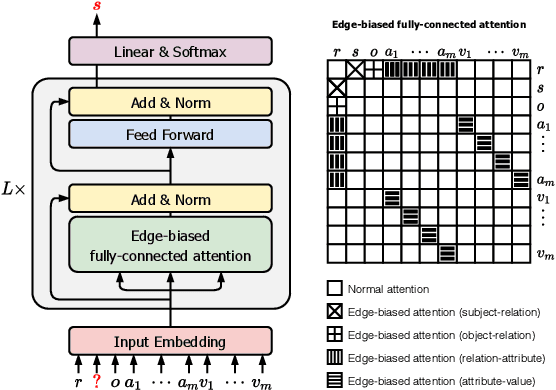

Link prediction on knowledge graphs (KGs) is a key research topic. Previous work mainly focused on binary relations, paying less attention to higher-arity relations although they are ubiquitous in real-world KGs. This paper considers link prediction upon n-ary relational facts and proposes a graph-based approach to this task. The key to our approach is to represent the n-ary structure of a fact as a small heterogeneous graph, and model this graph with edge-biased fully-connected attention. The fully-connected attention captures universal inter-vertex interactions, while with edge-aware attentive biases to particularly encode the graph structure and its heterogeneity. In this fashion, our approach fully models global and local dependencies in each n-ary fact, and hence can more effectively capture associations therein. Extensive evaluation verifies the effectiveness and superiority of our approach. It performs substantially and consistently better than current state-of-the-art across a variety of n-ary relational benchmarks. Our code is publicly available.
Entity Structure Within and Throughout: Modeling Mention Dependencies for Document-Level Relation Extraction
Feb 20, 2021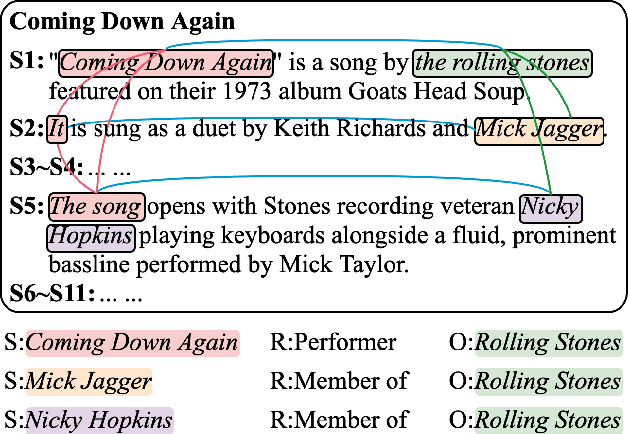


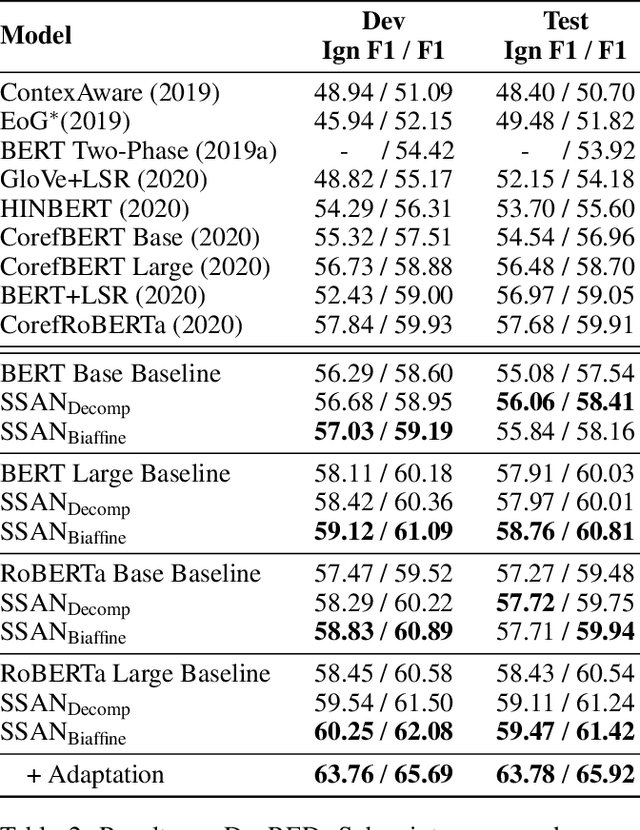
Entities, as the essential elements in relation extraction tasks, exhibit certain structure. In this work, we formulate such structure as distinctive dependencies between mention pairs. We then propose SSAN, which incorporates these structural dependencies within the standard self-attention mechanism and throughout the overall encoding stage. Specifically, we design two alternative transformation modules inside each self-attention building block to produce attentive biases so as to adaptively regularize its attention flow. Our experiments demonstrate the usefulness of the proposed entity structure and the effectiveness of SSAN. It significantly outperforms competitive baselines, achieving new state-of-the-art results on three popular document-level relation extraction datasets. We further provide ablation and visualization to show how the entity structure guides the model for better relation extraction. Our code is publicly available.