 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWiki Live Challenge: Challenging Deep Research Agents with Expert-Level Wikipedia Articles
Feb 03, 2026Deep Research Agents (DRAs) have demonstrated remarkable capabilities in autonomous information retrieval and report generation, showing great potential to assist humans in complex research tasks. Current evaluation frameworks primarily rely on LLM-generated references or LLM-derived evaluation dimensions. While these approaches offer scalability, they often lack the reliability of expert-verified content and struggle to provide objective, fine-grained assessments of critical dimensions. To bridge this gap, we introduce Wiki Live Challenge (WLC), a live benchmark that leverages the newest Wikipedia Good Articles (GAs) as expert-level references. Wikipedia's strict standards for neutrality, comprehensiveness, and verifiability serve as a great challenge for DRAs, with GAs representing the pinnacle of which. We curate a dataset of 100 recent Good Articles and propose Wiki Eval, a comprehensive evaluation framework comprising a fine-grained evaluation method with 39 criteria for writing quality and rigorous metrics for factual verifiability. Extensive experiments on various DRA systems demonstrate a significant gap between current DRAs and human expert-level Wikipedia articles, validating the effectiveness of WLC in advancing agent research. We release our benchmark at https://github.com/WangShao2000/Wiki_Live_Challenge
A-RAG: Scaling Agentic Retrieval-Augmented Generation via Hierarchical Retrieval Interfaces
Feb 03, 2026Frontier language models have demonstrated strong reasoning and long-horizon tool-use capabilities. However, existing RAG systems fail to leverage these capabilities. They still rely on two paradigms: (1) designing an algorithm that retrieves passages in a single shot and concatenates them into the model's input, or (2) predefining a workflow and prompting the model to execute it step-by-step. Neither paradigm allows the model to participate in retrieval decisions, preventing efficient scaling with model improvements. In this paper, we introduce A-RAG, an Agentic RAG framework that exposes hierarchical retrieval interfaces directly to the model. A-RAG provides three retrieval tools: keyword search, semantic search, and chunk read, enabling the agent to adaptively search and retrieve information across multiple granularities. Experiments on multiple open-domain QA benchmarks show that A-RAG consistently outperforms existing approaches with comparable or lower retrieved tokens, demonstrating that A-RAG effectively leverages model capabilities and dynamically adapts to different RAG tasks. We further systematically study how A-RAG scales with model size and test-time compute. We will release our code and evaluation suite to facilitate future research. Code and evaluation suite are available at https://github.com/Ayanami0730/arag.
WildGraphBench: Benchmarking GraphRAG with Wild-Source Corpora
Feb 03, 2026Graph-based Retrieval-Augmented Generation (GraphRAG) organizes external knowledge as a hierarchical graph, enabling efficient retrieval and aggregation of scattered evidence across multiple documents. However, many existing benchmarks for GraphRAG rely on short, curated passages as external knowledge, failing to adequately evaluate systems in realistic settings involving long contexts and large-scale heterogeneous documents. To bridge this gap, we introduce WildGraphBench, a benchmark designed to assess GraphRAG performance in the wild. We leverage Wikipedia's unique structure, where cohesive narratives are grounded in long and heterogeneous external reference documents, to construct a benchmark reflecting real-word scenarios. Specifically, we sample articles across 12 top-level topics, using their external references as the retrieval corpus and citation-linked statements as ground truth, resulting in 1,100 questions spanning three levels of complexity: single-fact QA, multi-fact QA, and section-level summarization. Experiments across multiple baselines reveal that current GraphRAG pipelines help on multi-fact aggregation when evidence comes from a moderate number of sources, but this aggregation paradigm may overemphasize high-level statements at the expense of fine-grained details, leading to weaker performance on summarization tasks. Project page:https://github.com/BstWPY/WildGraphBench.
FS-Researcher: Test-Time Scaling for Long-Horizon Research Tasks with File-System-Based Agents
Feb 02, 2026Deep research is emerging as a representative long-horizon task for large language model (LLM) agents. However, long trajectories in deep research often exceed model context limits, compressing token budgets for both evidence collection and report writing, and preventing effective test-time scaling. We introduce FS-Researcher, a file-system-based, dual-agent framework that scales deep research beyond the context window via a persistent workspace. Specifically, a Context Builder agent acts as a librarian which browses the internet, writes structured notes, and archives raw sources into a hierarchical knowledge base that can grow far beyond context length. A Report Writer agent then composes the final report section by section, treating the knowledge base as the source of facts. In this framework, the file system serves as a durable external memory and a shared coordination medium across agents and sessions, enabling iterative refinement beyond the context window. Experiments on two open-ended benchmarks (DeepResearch Bench and DeepConsult) show that FS-Researcher achieves state-of-the-art report quality across different backbone models. Further analyses demonstrate a positive correlation between final report quality and the computation allocated to the Context Builder, validating effective test-time scaling under the file-system paradigm. The code and data are anonymously open-sourced at https://github.com/Ignoramus0817/FS-Researcher.
DeepResearch Bench II: Diagnosing Deep Research Agents via Rubrics from Expert Report
Jan 13, 2026Deep Research Systems (DRS) aim to help users search the web, synthesize information, and deliver comprehensive investigative reports. However, how to rigorously evaluate these systems remains under-explored. Existing deep-research benchmarks often fall into two failure modes. Some do not adequately test a system's ability to analyze evidence and write coherent reports. Others rely on evaluation criteria that are either overly coarse or directly defined by LLMs (or both), leading to scores that can be biased relative to human experts and are hard to verify or interpret. To address these issues, we introduce Deep Research Bench II, a new benchmark for evaluating DRS-generated reports. It contains 132 grounded research tasks across 22 domains; for each task, a system must produce a long-form research report that is evaluated by a set of 9430 fine-grained binary rubrics in total, covering three dimensions: information recall, analysis, and presentation. All rubrics are derived from carefully selected expert-written investigative articles and are constructed through a four-stage LLM+human pipeline that combines automatic extraction with over 400 human-hours of expert review, ensuring that the criteria are atomic, verifiable, and aligned with human expert judgment. We evaluate several state-of-the-art deep-research systems on Deep Research Bench II and find that even the strongest models satisfy fewer than 50% of the rubrics, revealing a substantial gap between current DRSs and human experts.
SearchAttack: Red-Teaming LLMs against Real-World Threats via Framing Unsafe Web Information-Seeking Tasks
Jan 07, 2026Recently, people have suffered and become increasingly aware of the unreliability gap in LLMs for open and knowledge-intensive tasks, and thus turn to search-augmented LLMs to mitigate this issue. However, when the search engine is triggered for harmful tasks, the outcome is no longer under the LLM's control. Once the returned content directly contains targeted, ready-to-use harmful takeaways, the LLM's safeguards cannot withdraw that exposure. Motivated by this dilemma, we identify web search as a critical attack surface and propose \textbf{\textit{SearchAttack}} for red-teaming. SearchAttack outsources the harmful semantics to web search, retaining only the query's skeleton and fragmented clues, and further steers LLMs to reconstruct the retrieved content via structural rubrics to achieve malicious goals. Extensive experiments are conducted to red-team the search-augmented LLMs for responsible vulnerability assessment. Empirically, SearchAttack demonstrates strong effectiveness in attacking these systems.
DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents
Jun 13, 2025Deep Research Agents are a prominent category of LLM-based agents. By autonomously orchestrating multistep web exploration, targeted retrieval, and higher-order synthesis, they transform vast amounts of online information into analyst-grade, citation-rich reports--compressing hours of manual desk research into minutes. However, a comprehensive benchmark for systematically evaluating the capabilities of these agents remains absent. To bridge this gap, we present DeepResearch Bench, a benchmark consisting of 100 PhD-level research tasks, each meticulously crafted by domain experts across 22 distinct fields. Evaluating DRAs is inherently complex and labor-intensive. We therefore propose two novel methodologies that achieve strong alignment with human judgment. The first is a reference-based method with adaptive criteria to assess the quality of generated research reports. The other framework is introduced to evaluate DRA's information retrieval and collection capabilities by assessing its effective citation count and overall citation accuracy. We have open-sourced DeepResearch Bench and key components of these frameworks at https://github.com/Ayanami0730/deep_research_bench to accelerate the development of practical LLM-based agents.
From Real to Synthetic: Synthesizing Millions of Diversified and Complicated User Instructions with Attributed Grounding
Jun 04, 2025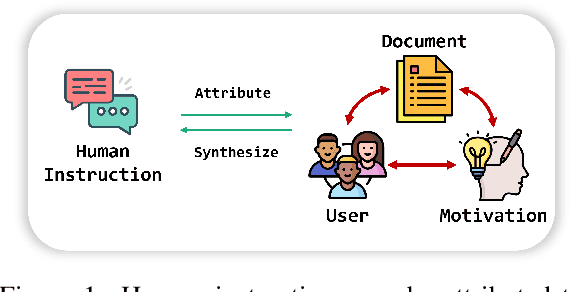
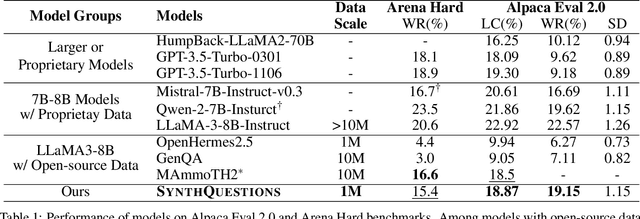
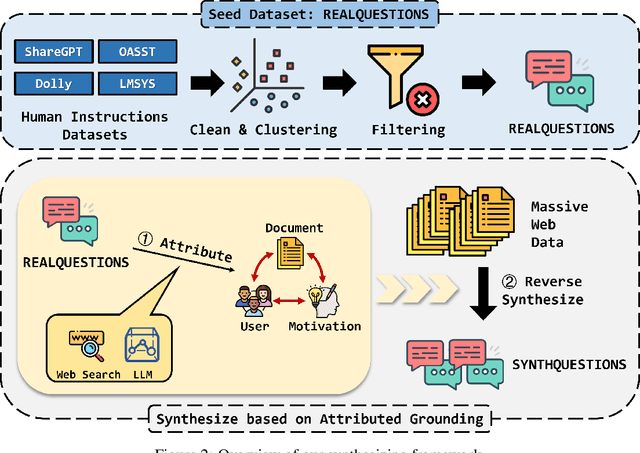
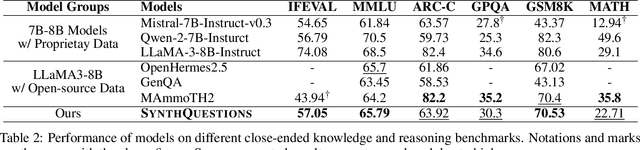
The pursuit of diverse, complex, and large-scale instruction data is crucial for automatically aligning large language models (LLMs). While there are methods capable of generating synthetic instructions at scale, they either suffer from limited grounding sources, leading to a narrow distribution, or rely on trivial extensions that fail to produce meaningful trajectories in terms of complexity. In contrast, instructions that benefit efficient alignment are typically crafted with cognitive insights and grounded in real-world use cases. In this paper, we synthesize such instructions using attributed grounding, which involves 1) a top-down attribution process that grounds a selective set of real instructions to situated users, and 2) a bottom-up synthesis process that leverages web documents to first generate a situation, then a meaningful instruction. This framework allows us to harvest diverse and complex instructions at scale, utilizing the vast range of web documents. Specifically, we construct a dataset of 1 million instructions, called SynthQuestions, and demonstrate that models trained on it achieve leading performance on several common benchmarks, with improvements that continually scale with more web corpora. Data, models and codes will be available at https://github.com/Ignoramus0817/SynthQuestions.
Rationales Are Not Silver Bullets: Measuring the Impact of Rationales on Model Performance and Reliability
May 30, 2025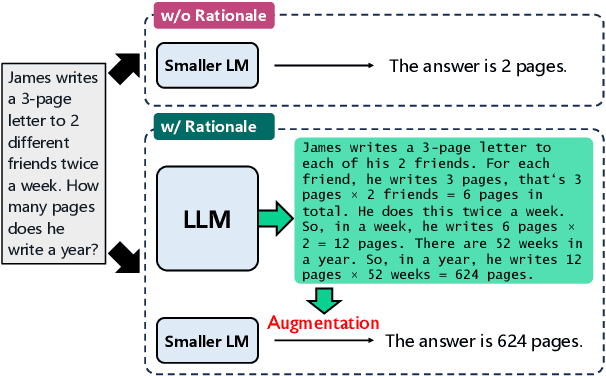
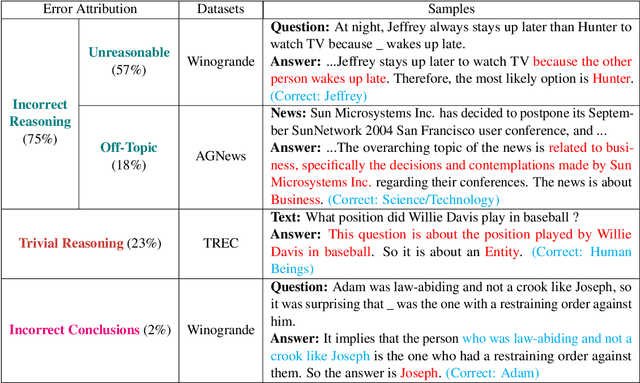
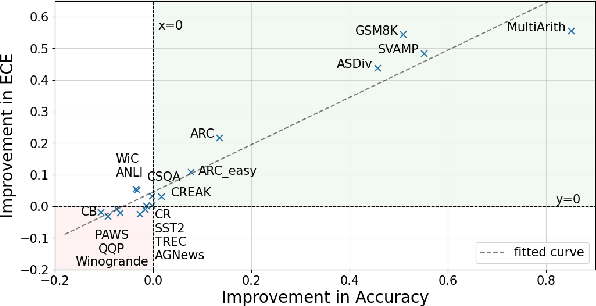

Training language models with rationales augmentation has been shown to be beneficial in many existing works. In this paper, we identify that such a prevailing view does not hold consistently. We conduct comprehensive investigations to thoroughly inspect the impact of rationales on model performance as well as a novel perspective of model reliability. The results lead to several key findings that add new insights upon existing understandings: 1) Rationales can, at times, deteriorate model performance; 2) Rationales can, at times, improve model reliability, even outperforming their untrained counterparts; 3) A linear correspondence exists in between the performance and reliability improvements, while both are driven by the intrinsic difficulty of the task. These findings provide informative regulations on the broad utilization of rationales and raise critical implications on the procedure of explicitly aligning language models with implicit human thoughts. Codes can be found at https://github.com/Ignoramus0817/rationales.
MIRROR: Multi-agent Intra- and Inter-Reflection for Optimized Reasoning in Tool Learning
May 27, 2025Complex tasks involving tool integration pose significant challenges for Large Language Models (LLMs), leading to the emergence of multi-agent workflows as a promising solution. Reflection has emerged as an effective strategy for correcting erroneous trajectories in agentic workflows. However, existing approaches only exploit such capability in the post-action stage, where the agent observes the execution outcomes. We argue that, like humans, LLMs can also engage in reflection before action execution: the agent can anticipate undesirable outcomes from its own decisions, which not only provides a necessarily complementary perspective to evaluate the decision but also prevents the propagation of errors throughout the trajectory. In this paper, we propose MIRROR, a framework that consists of both intra-reflection, which critically assesses intended actions before execution, and inter-reflection, which further adjusts the trajectory based on observations. This design systematically leverages LLM reflection capabilities to eliminate and rectify erroneous actions on a more comprehensive scope. Evaluations on both the StableToolBench and TravelPlanner benchmarks demonstrate MIRROR's superior performance, achieving state-of-the-art results compared to existing approaches.