 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining LLM-Based Agents with Synthetic Self-Reflected Trajectories and Partial Masking
May 26, 2025Autonomous agents, which perceive environments and take actions to achieve goals, have become increasingly feasible with the advancements in large language models (LLMs). However, current powerful agents often depend on sophisticated prompt engineering combined with closed-source LLMs like GPT-4. Although training open-source LLMs using expert trajectories from teacher models has yielded some improvements in agent capabilities, this approach still faces limitations such as performance plateauing and error propagation. To mitigate these challenges, we propose STeP, a novel method for improving LLM-based agent training. We synthesize self-reflected trajectories that include reflections and corrections of error steps, which enhance the effectiveness of LLM agents in learning from teacher models, enabling them to become agents capable of self-reflecting and correcting. We also introduce partial masking strategy that prevents the LLM from internalizing incorrect or suboptimal steps. Experiments demonstrate that our method improves agent performance across three representative tasks: ALFWorld, WebShop, and SciWorld. For the open-source model LLaMA2-7B-Chat, when trained using self-reflected trajectories constructed with Qwen1.5-110B-Chat as the teacher model, it achieves comprehensive improvements with less training data compared to agents trained exclusively on expert trajectories.
Structure-Aware Correspondence Learning for Relative Pose Estimation
Mar 24, 2025Relative pose estimation provides a promising way for achieving object-agnostic pose estimation. Despite the success of existing 3D correspondence-based methods, the reliance on explicit feature matching suffers from small overlaps in visible regions and unreliable feature estimation for invisible regions. Inspired by humans' ability to assemble two object parts that have small or no overlapping regions by considering object structure, we propose a novel Structure-Aware Correspondence Learning method for Relative Pose Estimation, which consists of two key modules. First, a structure-aware keypoint extraction module is designed to locate a set of kepoints that can represent the structure of objects with different shapes and appearance, under the guidance of a keypoint based image reconstruction loss. Second, a structure-aware correspondence estimation module is designed to model the intra-image and inter-image relationships between keypoints to extract structure-aware features for correspondence estimation. By jointly leveraging these two modules, the proposed method can naturally estimate 3D-3D correspondences for unseen objects without explicit feature matching for precise relative pose estimation. Experimental results on the CO3D, Objaverse and LineMOD datasets demonstrate that the proposed method significantly outperforms prior methods, i.e., with 5.7{\deg}reduction in mean angular error on the CO3D dataset.
Benchmarking Large Language Models on Controllable Generation under Diversified Instructions
Jan 01, 2024

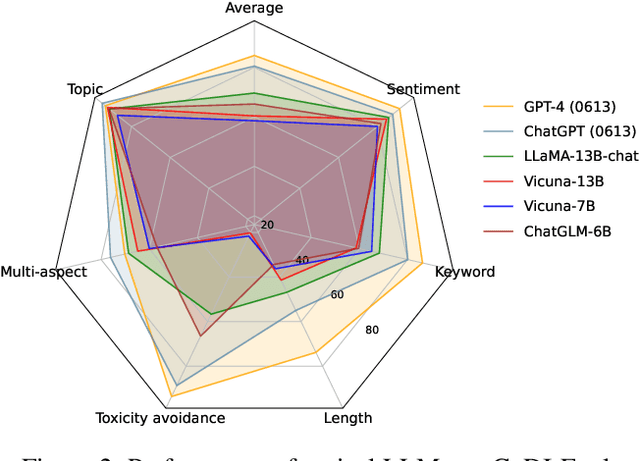

While large language models (LLMs) have exhibited impressive instruction-following capabilities, it is still unclear whether and to what extent they can respond to explicit constraints that might be entailed in various instructions. As a significant aspect of LLM alignment, it is thus important to formulate such a specialized set of instructions as well as investigate the resulting behavior of LLMs. To address this vacancy, we propose a new benchmark CoDI-Eval to systematically and comprehensively evaluate LLMs' responses to instructions with various constraints. We construct a large collection of constraints-attributed instructions as a test suite focused on both generalization and coverage. Specifically, we advocate an instruction diversification process to synthesize diverse forms of constraint expression and also deliberate the candidate task taxonomy with even finer-grained sub-categories. Finally, we automate the entire evaluation process to facilitate further developments. Different from existing studies on controllable text generation, CoDI-Eval extends the scope to the prevalent instruction-following paradigm for the first time. We provide extensive evaluations of representative LLMs (e.g., ChatGPT, Vicuna) on CoDI-Eval, revealing their limitations in following instructions with specific constraints and there is still a significant gap between open-source and commercial closed-source LLMs. We believe this benchmark will facilitate research into improving the controllability of LLMs' responses to instructions. Our data and code are available at https://github.com/Xt-cyh/CoDI-Eval.