 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending AI for Research to the Humanities: A Multi-Agent Framework for Evidence-Grounded Scholarship
May 29, 2026LLM-based research agents have advanced rapidly in science and engineering, where research is organized around executable experiments, code, and quantitative signals. Humanities scholarship, however, requires a different mode of reasoning: interpretive, evidence-grounded argument over primary sources, where scholarly value depends on faithful quotation, verifiable provenance, and close reading. Existing research agents remain largely optimized for execution and retrieval, not evidence-grounded interpretive reasoning. To address this gap, we introduce SPIRE (Scholarly-Primitives-Inspired Research Engine), a multi-agent framework for evidence-grounded humanities scholarship. Drawing on Scholarly Primitives theory, SPIRE casts recurring humanities operations as cooperating agent roles (source discovery, evidence annotation, comparison, provenance checking, sampling, citation binding, and argumentative synthesis) over a multi-scale close-reading substrate of passages, intra-context graph communities, and cross-context semantic clusters. On a peer-reviewed-paper benchmark over classical Chinese and Greco-Roman Latin scholarship, SPIRE recovers cited primary-source evidence more reliably than Naive LLM, Text RAG, and GraphRAG, and receives higher blind-judge scores on answer accuracy, depth, coverage, and evidence quality. Ablations show that both the scholarly-operation agents and close-reading retrieval contribute to evidence-grounded essays. Code, data catalogues, and reproduction scripts are released at https://github.com/YatingPan/SPIRE.
LitSeg: Narrative-Aware Document Segmentation for Literary RAG
May 26, 2026Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by incorporating external knowledge, particularly for long-tail domains such as literary works. However, the critical step of document segmentation in RAG remains largely underexplored. Existing strategies are typically semantically blind and overlook the complicated narrative structures of literary works, often resulting in fragmented plots and unclear references that severely hinder retrieval and generation performance. To address this, we propose LitSeg, a novel narrative-theory-guided segmentation framework. By employing multi-stage prompting, LitSeg explicitly extracts valid events, untangles narrative threads, clarifies narrative structures, and locates turning points to inform segmentation. To alleviate the computational overhead of multi-stage inference with large-scale models, we further introduce LitSeg-Lite, a lightweight single-pass chunker fine-tuned on LitSeg-generated data via a two-stage training strategy, distilling the complex process into a single inference pass. Extensive experiments demonstrate that with structurally independent text chunks, our methods significantly improve retrieval accuracy and context relevance over baselines, ultimately enhancing downstream QA performance, while ablation studies validate the efficacy of narratological guidance and data distillation.
AnySlot: Goal-Conditioned Vision-Language-Action Policies for Zero-Shot Slot-Level Placement
Apr 14, 2026Vision-Language-Action (VLA) policies have emerged as a versatile paradigm for generalist robotic manipulation. However, precise object placement under compositional language instructions remains a major challenge for modern monolithic VLA policies. Slot-level tasks require both reliable slot grounding and sub-centimeter execution accuracy. To this end, we propose AnySlot, a framework that reduces compositional complexity by introducing an explicit spatial visual goal as an intermediate representation between language grounding and control. AnySlot turns language into an explicit visual goal by generating a scene marker, then executes this goal with a goal-conditioned VLA policy. This hierarchical design effectively decouples high-level slot selection from low-level execution, ensuring both semantic accuracy and spatial robustness. Furthermore, recognizing the lack of existing benchmarks for such precision-demanding tasks, we introduce SlotBench, a comprehensive simulation benchmark featuring nine task categories tailored to evaluate structured spatial reasoning in slot-level placement. Extensive experiments show that AnySlot significantly outperforms flat VLA baselines and previous modular grounding methods in zero-shot slot-level placement.
SPAN-Nav: Generalized Spatial Awareness for Versatile Vision-Language Navigation
Mar 10, 2026Recent embodied navigation approaches leveraging Vision-Language Models (VLMs) demonstrate strong generalization in versatile Vision-Language Navigation (VLN). However, reliable path planning in complex environments remains challenging due to insufficient spatial awareness. In this work, we introduce SPAN-Nav, an end-to-end foundation model designed to infuse embodied navigation with universal 3D spatial awareness using RGB video streams. SPAN-Nav extracts spatial priors across diverse scenes through an occupancy prediction task on extensive indoor and outdoor environments. To mitigate the computational burden, we introduce a compact representation for spatial priors, finding that a single token is sufficient to encapsulate the coarse-grained cues essential for navigation tasks. Furthermore, inspired by the Chain-of-Thought (CoT) mechanism, SPAN-Nav utilizes this single spatial token to explicitly inject spatial cues into action reasoning through an end-to end framework. Leveraging multi-task co-training, SPAN-Nav captures task-adaptive cues from generalized spatial priors, enabling robust spatial awareness to generalize even to the task lacking explicit spatial supervision. To support comprehensive spatial learning, we present a massive dataset of 4.2 million occupancy annotations that covers both indoor and outdoor scenes across multi-type navigation tasks. SPAN-Nav achieves state-of-the-art performance across three benchmarks spanning diverse scenarios and varied navigation tasks. Finally, real-world experiments validate the robust generalization and practical reliability of our approach across complex physical scenarios.
Mechanistic Knobs in LLMs: Retrieving and Steering High-Order Semantic Features via Sparse Autoencoders
Jan 06, 2026Recent work in Mechanistic Interpretability (MI) has enabled the identification and intervention of internal features in Large Language Models (LLMs). However, a persistent challenge lies in linking such internal features to the reliable control of complex, behavior-level semantic attributes in language generation. In this paper, we propose a Sparse Autoencoder-based framework for retrieving and steering semantically interpretable internal features associated with high-level linguistic behaviors. Our method employs a contrastive feature retrieval pipeline based on controlled semantic oppositions, combing statistical activation analysis and generation-based validation to distill monosemantic functional features from sparse activation spaces. Using the Big Five personality traits as a case study, we demonstrate that our method enables precise, bidirectional steering of model behavior while maintaining superior stability and performance compared to existing activation steering methods like Contrastive Activation Addition (CAA). We further identify an empirical effect, which we term Functional Faithfulness, whereby intervening on a specific internal feature induces coherent and predictable shifts across multiple linguistic dimensions aligned with the target semantic attribute. Our findings suggest that LLMs internalize deeply integrated representations of high-order concepts, and provide a novel, robust mechanistic path for the regulation of complex AI behaviors.
Driving in Spikes: An Entropy-Guided Object Detector for Spike Cameras
Nov 19, 2025Object detection in autonomous driving suffers from motion blur and saturation under fast motion and extreme lighting. Spike cameras, offer microsecond latency and ultra high dynamic range for object detection by using per pixel asynchronous integrate and fire. However, their sparse, discrete output cannot be processed by standard image-based detectors, posing a critical challenge for end to end spike stream detection. We propose EASD, an end to end spike camera detector with a dual branch design: a Temporal Based Texture plus Feature Fusion branch for global cross slice semantics, and an Entropy Selective Attention branch for object centric details. To close the data gap, we introduce DSEC Spike, the first driving oriented simulated spike detection benchmark.
Code-as-Monitor: Constraint-aware Visual Programming for Reactive and Proactive Robotic Failure Detection
Dec 05, 2024



Automatic detection and prevention of open-set failures are crucial in closed-loop robotic systems. Recent studies often struggle to simultaneously identify unexpected failures reactively after they occur and prevent foreseeable ones proactively. To this end, we propose Code-as-Monitor (CaM), a novel paradigm leveraging the vision-language model (VLM) for both open-set reactive and proactive failure detection. The core of our method is to formulate both tasks as a unified set of spatio-temporal constraint satisfaction problems and use VLM-generated code to evaluate them for real-time monitoring. To enhance the accuracy and efficiency of monitoring, we further introduce constraint elements that abstract constraint-related entities or their parts into compact geometric elements. This approach offers greater generality, simplifies tracking, and facilitates constraint-aware visual programming by leveraging these elements as visual prompts. Experiments show that CaM achieves a 28.7% higher success rate and reduces execution time by 31.8% under severe disturbances compared to baselines across three simulators and a real-world setting. Moreover, CaM can be integrated with open-loop control policies to form closed-loop systems, enabling long-horizon tasks in cluttered scenes with dynamic environments.
CHisIEC: An Information Extraction Corpus for Ancient Chinese History
Mar 22, 2024

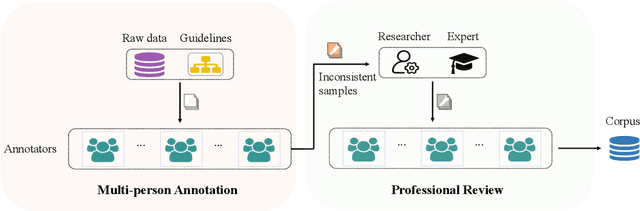

Natural Language Processing (NLP) plays a pivotal role in the realm of Digital Humanities (DH) and serves as the cornerstone for advancing the structural analysis of historical and cultural heritage texts. This is particularly true for the domains of named entity recognition (NER) and relation extraction (RE). In our commitment to expediting ancient history and culture, we present the ``Chinese Historical Information Extraction Corpus''(CHisIEC). CHisIEC is a meticulously curated dataset designed to develop and evaluate NER and RE tasks, offering a resource to facilitate research in the field. Spanning a remarkable historical timeline encompassing data from 13 dynasties spanning over 1830 years, CHisIEC epitomizes the extensive temporal range and text heterogeneity inherent in Chinese historical documents. The dataset encompasses four distinct entity types and twelve relation types, resulting in a meticulously labeled dataset comprising 14,194 entities and 8,609 relations. To establish the robustness and versatility of our dataset, we have undertaken comprehensive experimentation involving models of various sizes and paradigms. Additionally, we have evaluated the capabilities of Large Language Models (LLMs) in the context of tasks related to ancient Chinese history. The dataset and code are available at \url{https://github.com/tangxuemei1995/CHisIEC}.
Restoring Ancient Ideograph: A Multimodal Multitask Neural Network Approach
Mar 11, 2024



Cultural heritage serves as the enduring record of human thought and history. Despite significant efforts dedicated to the preservation of cultural relics, many ancient artefacts have been ravaged irreversibly by natural deterioration and human actions. Deep learning technology has emerged as a valuable tool for restoring various kinds of cultural heritages, including ancient text restoration. Previous research has approached ancient text restoration from either visual or textual perspectives, often overlooking the potential of synergizing multimodal information. This paper proposes a novel Multimodal Multitask Restoring Model (MMRM) to restore ancient texts, particularly emphasising the ideograph. This model combines context understanding with residual visual information from damaged ancient artefacts, enabling it to predict damaged characters and generate restored images simultaneously. We tested the MMRM model through experiments conducted on both simulated datasets and authentic ancient inscriptions. The results show that the proposed method gives insightful restoration suggestions in both simulation experiments and real-world scenarios. To the best of our knowledge, this work represents the pioneering application of multimodal deep learning in ancient text restoration, which will contribute to the understanding of ancient society and culture in digital humanities fields.
Small Language Model Is a Good Guide for Large Language Model in Chinese Entity Relation Extraction
Feb 22, 2024



Recently, large language models (LLMs) have been successful in relational extraction (RE) tasks, especially in the few-shot learning. An important problem in the field of RE is long-tailed data, while not much attention is currently paid to this problem using LLM approaches. Therefore, in this paper, we propose SLCoLM, a model collaboration framework, to mitigate the data long-tail problem. In our framework, We use the ``\textit{Training-Guide-Predict}'' strategy to combine the strengths of pre-trained language models (PLMs) and LLMs, where a task-specific PLM framework acts as a tutor, transfers task knowledge to the LLM, and guides the LLM in performing RE tasks. Our experiments on a RE dataset rich in relation types show that the approach in this paper facilitates RE of long-tail relation types.