 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHisIEC: An Information Extraction Corpus for Ancient Chinese History
Paper and Code


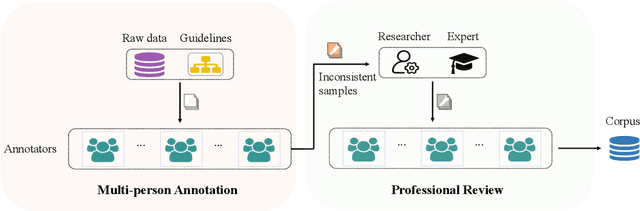

Natural Language Processing (NLP) plays a pivotal role in the realm of Digital Humanities (DH) and serves as the cornerstone for advancing the structural analysis of historical and cultural heritage texts. This is particularly true for the domains of named entity recognition (NER) and relation extraction (RE). In our commitment to expediting ancient history and culture, we present the ``Chinese Historical Information Extraction Corpus''(CHisIEC). CHisIEC is a meticulously curated dataset designed to develop and evaluate NER and RE tasks, offering a resource to facilitate research in the field. Spanning a remarkable historical timeline encompassing data from 13 dynasties spanning over 1830 years, CHisIEC epitomizes the extensive temporal range and text heterogeneity inherent in Chinese historical documents. The dataset encompasses four distinct entity types and twelve relation types, resulting in a meticulously labeled dataset comprising 14,194 entities and 8,609 relations. To establish the robustness and versatility of our dataset, we have undertaken comprehensive experimentation involving models of various sizes and paradigms. Additionally, we have evaluated the capabilities of Large Language Models (LLMs) in the context of tasks related to ancient Chinese history. The dataset and code are available at \url{https://github.com/tangxuemei1995/CHisIEC}.