 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Large Language Models Plan Answer Positions? Position Bias in Multiple-Choice Question Generation
May 03, 2026Large language models (LLMs) are increasingly used to generate multiple-choice questions (MCQs), where correct answers should ideally be uniformly distributed across options. However, we observe that LLMs exhibit systematic position biases during generation. Through extensive experiments with 10 LLMs and 5 vision-language models (VLMs) on three MCQ generation tasks, we show that these biases are structured, with similar patterns emerging within model families. To investigate the underlying mechanisms, we conduct probing experiments and find that hidden representations in the question stem encode predictive signals of the correct answer position, suggesting that answer position may be implicitly planned during generation. Building on this insight, we apply activation steering to manipulate internal representations and influence answer position. Our results show that steering can partially control positional preferences and substantially shift answer position distributions. Our findings provide a practical framework for studying implicit positional planning in LLMs and highlight the importance of controllable generation for reliable MCQ construction and evaluation.
Are LLMs Good Literature Review Writers? Evaluating the Literature Review Writing Ability of Large Language Models
Dec 18, 2024



The literature review is a crucial form of academic writing that involves complex processes of literature collection, organization, and summarization. The emergence of large language models (LLMs) has introduced promising tools to automate these processes. However, their actual capabilities in writing comprehensive literature reviews remain underexplored, such as whether they can generate accurate and reliable references. To address this gap, we propose a framework to assess the literature review writing ability of LLMs automatically. We evaluate the performance of LLMs across three tasks: generating references, writing abstracts, and writing literature reviews. We employ external tools for a multidimensional evaluation, which includes assessing hallucination rates in references, semantic coverage, and factual consistency with human-written context. By analyzing the experimental results, we find that, despite advancements, even the most sophisticated models still cannot avoid generating hallucinated references. Additionally, different models exhibit varying performance in literature review writing across different disciplines.
Privacy-Preserving Federated Foundation Model for Generalist Ultrasound Artificial Intelligence
Nov 25, 2024



Ultrasound imaging is widely used in clinical diagnosis due to its non-invasive nature and real-time capabilities. However, conventional ultrasound diagnostics face several limitations, including high dependence on physician expertise and suboptimal image quality, which complicates interpretation and increases the likelihood of diagnostic errors. Artificial intelligence (AI) has emerged as a promising solution to enhance clinical diagnosis, particularly in detecting abnormalities across various biomedical imaging modalities. Nonetheless, current AI models for ultrasound imaging face critical challenges. First, these models often require large volumes of labeled medical data, raising concerns over patient privacy breaches. Second, most existing models are task-specific, which restricts their broader clinical utility. To overcome these challenges, we present UltraFedFM, an innovative privacy-preserving ultrasound foundation model. UltraFedFM is collaboratively pre-trained using federated learning across 16 distributed medical institutions in 9 countries, leveraging a dataset of over 1 million ultrasound images covering 19 organs and 10 ultrasound modalities. This extensive and diverse data, combined with a secure training framework, enables UltraFedFM to exhibit strong generalization and diagnostic capabilities. It achieves an average area under the receiver operating characteristic curve of 0.927 for disease diagnosis and a dice similarity coefficient of 0.878 for lesion segmentation. Notably, UltraFedFM surpasses the diagnostic accuracy of mid-level ultrasonographers and matches the performance of expert-level sonographers in the joint diagnosis of 8 common systemic diseases. These findings indicate that UltraFedFM can significantly enhance clinical diagnostics while safeguarding patient privacy, marking an advancement in AI-driven ultrasound imaging for future clinical applications.
HLB: Benchmarking LLMs' Humanlikeness in Language Use
Sep 24, 2024
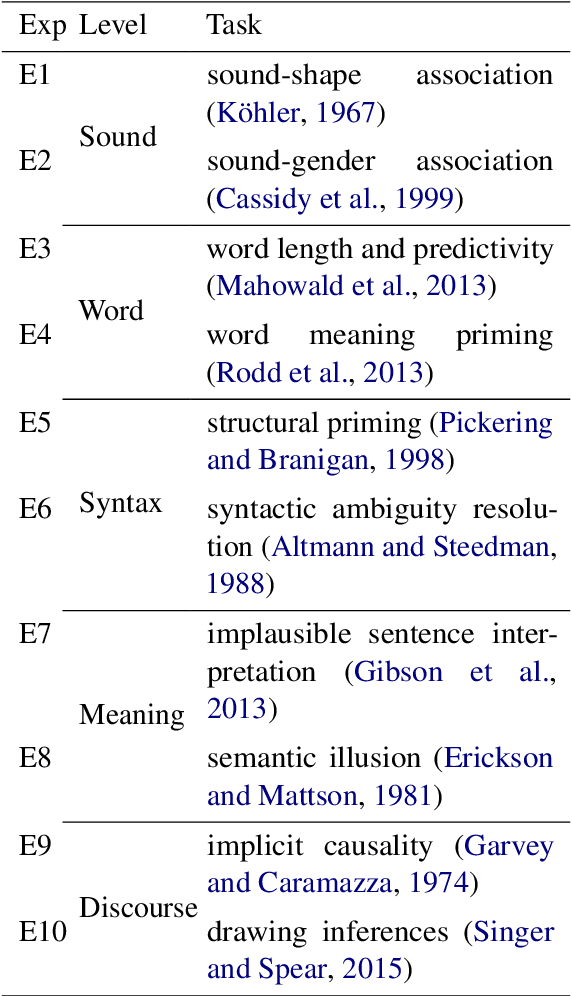
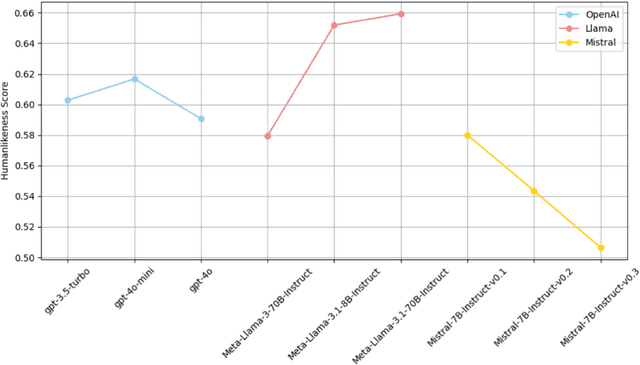
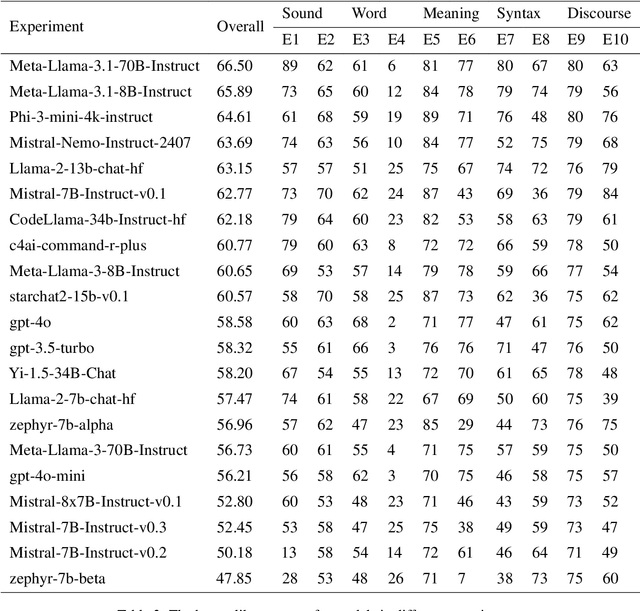
As synthetic data becomes increasingly prevalent in training language models, particularly through generated dialogue, concerns have emerged that these models may deviate from authentic human language patterns, potentially losing the richness and creativity inherent in human communication. This highlights the critical need to assess the humanlikeness of language models in real-world language use. In this paper, we present a comprehensive humanlikeness benchmark (HLB) evaluating 20 large language models (LLMs) using 10 psycholinguistic experiments designed to probe core linguistic aspects, including sound, word, syntax, semantics, and discourse (see https://huggingface.co/spaces/XufengDuan/HumanLikeness). To anchor these comparisons, we collected responses from over 2,000 human participants and compared them to outputs from the LLMs in these experiments. For rigorous evaluation, we developed a coding algorithm that accurately identified language use patterns, enabling the extraction of response distributions for each task. By comparing the response distributions between human participants and LLMs, we quantified humanlikeness through distributional similarity. Our results reveal fine-grained differences in how well LLMs replicate human responses across various linguistic levels. Importantly, we found that improvements in other performance metrics did not necessarily lead to greater humanlikeness, and in some cases, even resulted in a decline. By introducing psycholinguistic methods to model evaluation, this benchmark offers the first framework for systematically assessing the humanlikeness of LLMs in language use.
Towards a Benchmark for Colorectal Cancer Segmentation in Endorectal Ultrasound Videos: Dataset and Model Development
Aug 19, 2024Endorectal ultrasound (ERUS) is an important imaging modality that provides high reliability for diagnosing the depth and boundary of invasion in colorectal cancer. However, the lack of a large-scale ERUS dataset with high-quality annotations hinders the development of automatic ultrasound diagnostics. In this paper, we collected and annotated the first benchmark dataset that covers diverse ERUS scenarios, i.e. colorectal cancer segmentation, detection, and infiltration depth staging. Our ERUS-10K dataset comprises 77 videos and 10,000 high-resolution annotated frames. Based on this dataset, we further introduce a benchmark model for colorectal cancer segmentation, named the Adaptive Sparse-context TRansformer (ASTR). ASTR is designed based on three considerations: scanning mode discrepancy, temporal information, and low computational complexity. For generalizing to different scanning modes, the adaptive scanning-mode augmentation is proposed to convert between raw sector images and linear scan ones. For mining temporal information, the sparse-context transformer is incorporated to integrate inter-frame local and global features. For reducing computational complexity, the sparse-context block is introduced to extract contextual features from auxiliary frames. Finally, on the benchmark dataset, the proposed ASTR model achieves a 77.6% Dice score in rectal cancer segmentation, largely outperforming previous state-of-the-art methods.
CHisIEC: An Information Extraction Corpus for Ancient Chinese History
Mar 22, 2024

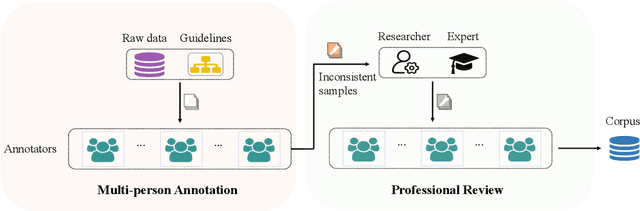

Natural Language Processing (NLP) plays a pivotal role in the realm of Digital Humanities (DH) and serves as the cornerstone for advancing the structural analysis of historical and cultural heritage texts. This is particularly true for the domains of named entity recognition (NER) and relation extraction (RE). In our commitment to expediting ancient history and culture, we present the ``Chinese Historical Information Extraction Corpus''(CHisIEC). CHisIEC is a meticulously curated dataset designed to develop and evaluate NER and RE tasks, offering a resource to facilitate research in the field. Spanning a remarkable historical timeline encompassing data from 13 dynasties spanning over 1830 years, CHisIEC epitomizes the extensive temporal range and text heterogeneity inherent in Chinese historical documents. The dataset encompasses four distinct entity types and twelve relation types, resulting in a meticulously labeled dataset comprising 14,194 entities and 8,609 relations. To establish the robustness and versatility of our dataset, we have undertaken comprehensive experimentation involving models of various sizes and paradigms. Additionally, we have evaluated the capabilities of Large Language Models (LLMs) in the context of tasks related to ancient Chinese history. The dataset and code are available at \url{https://github.com/tangxuemei1995/CHisIEC}.
Small Language Model Is a Good Guide for Large Language Model in Chinese Entity Relation Extraction
Feb 22, 2024



Recently, large language models (LLMs) have been successful in relational extraction (RE) tasks, especially in the few-shot learning. An important problem in the field of RE is long-tailed data, while not much attention is currently paid to this problem using LLM approaches. Therefore, in this paper, we propose SLCoLM, a model collaboration framework, to mitigate the data long-tail problem. In our framework, We use the ``\textit{Training-Guide-Predict}'' strategy to combine the strengths of pre-trained language models (PLMs) and LLMs, where a task-specific PLM framework acts as a tutor, transfers task knowledge to the LLM, and guides the LLM in performing RE tasks. Our experiments on a RE dataset rich in relation types show that the approach in this paper facilitates RE of long-tail relation types.
An Effective Incorporating Heterogeneous Knowledge Curriculum Learning for Sequence Labeling
Feb 21, 2024Sequence labeling models often benefit from incorporating external knowledge. However, this practice introduces data heterogeneity and complicates the model with additional modules, leading to increased expenses for training a high-performing model. To address this challenge, we propose a two-stage curriculum learning (TCL) framework specifically designed for sequence labeling tasks. The TCL framework enhances training by gradually introducing data instances from easy to hard, aiming to improve both performance and training speed. Furthermore, we explore different metrics for assessing the difficulty levels of sequence labeling tasks. Through extensive experimentation on six Chinese word segmentation (CWS) and Part-of-speech tagging (POS) datasets, we demonstrate the effectiveness of our model in enhancing the performance of sequence labeling models. Additionally, our analysis indicates that TCL accelerates training and alleviates the slow training problem associated with complex models.
Incorporating Deep Syntactic and Semantic Knowledge for Chinese Sequence Labeling with GCN
Jun 03, 2023



Recently, it is quite common to integrate Chinese sequence labeling results to enhance syntactic and semantic parsing. However, little attention has been paid to the utility of hierarchy and structure information encoded in syntactic and semantic features for Chinese sequence labeling tasks. In this paper, we propose a novel framework to encode syntactic structure features and semantic information for Chinese sequence labeling tasks with graph convolutional networks (GCN). Experiments on five benchmark datasets, including Chinese word segmentation and part-of-speech tagging, demonstrate that our model can effectively improve the performance of Chinese labeling tasks.
That Slepen Al the Nyght with Open Ye! Cross-era Sequence Segmentation with Switch-memory
Sep 07, 2022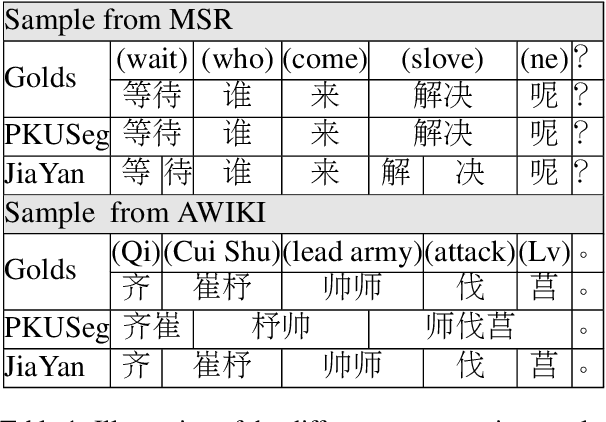


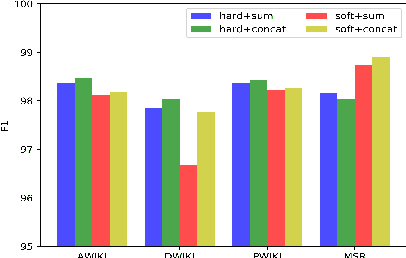
The evolution of language follows the rule of gradual change. Grammar, vocabulary, and lexical semantic shifts take place over time, resulting in a diachronic linguistic gap. As such, a considerable amount of texts are written in languages of different eras, which creates obstacles for natural language processing tasks, such as word segmentation and machine translation. Although the Chinese language has a long history, previous Chinese natural language processing research has primarily focused on tasks within a specific era. Therefore, we propose a cross-era learning framework for Chinese word segmentation (CWS), CROSSWISE, which uses the Switch-memory (SM) module to incorporate era-specific linguistic knowledge. Experiments on four corpora from different eras show that the performance of each corpus significantly improves. Further analyses also demonstrate that the SM can effectively integrate the knowledge of the eras into the neural network.