 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSKANMixer: Kolmogorov-Arnold Networks with MLP-Mixer Model for Time Series Forecasting
Feb 25, 2025



Time series forecasting has long been a focus of research across diverse fields, including economics, energy, healthcare, and traffic management. Recent works have introduced innovative architectures for time series models, such as the Time-Series Mixer (TSMixer), which leverages multi-layer perceptrons (MLPs) to enhance prediction accuracy by effectively capturing both spatial and temporal dependencies within the data. In this paper, we investigate the capabilities of the Kolmogorov-Arnold Networks (KANs) for time-series forecasting by modifying TSMixer with a KAN layer (TSKANMixer). Experimental results demonstrate that TSKANMixer tends to improve prediction accuracy over the original TSMixer across multiple datasets, ranking among the top-performing models compared to other time series approaches. Our results show that the KANs are promising alternatives to improve the performance of time series forecasting by replacing or extending traditional MLPs.
Unveiling Language Competence Neurons: A Psycholinguistic Approach to Model Interpretability
Sep 24, 2024As large language models (LLMs) become advance in their linguistic capacity, understanding how they capture aspects of language competence remains a significant challenge. This study therefore employs psycholinguistic paradigms, which are well-suited for probing deeper cognitive aspects of language processing, to explore neuron-level representations in language model across three tasks: sound-shape association, sound-gender association, and implicit causality. Our findings indicate that while GPT-2-XL struggles with the sound-shape task, it demonstrates human-like abilities in both sound-gender association and implicit causality. Targeted neuron ablation and activation manipulation reveal a crucial relationship: when GPT-2-XL displays a linguistic ability, specific neurons correspond to that competence; conversely, the absence of such an ability indicates a lack of specialized neurons. This study is the first to utilize psycholinguistic experiments to investigate deep language competence at the neuron level, providing a new level of granularity in model interpretability and insights into the internal mechanisms driving language ability in transformer based LLMs.
HLB: Benchmarking LLMs' Humanlikeness in Language Use
Sep 24, 2024
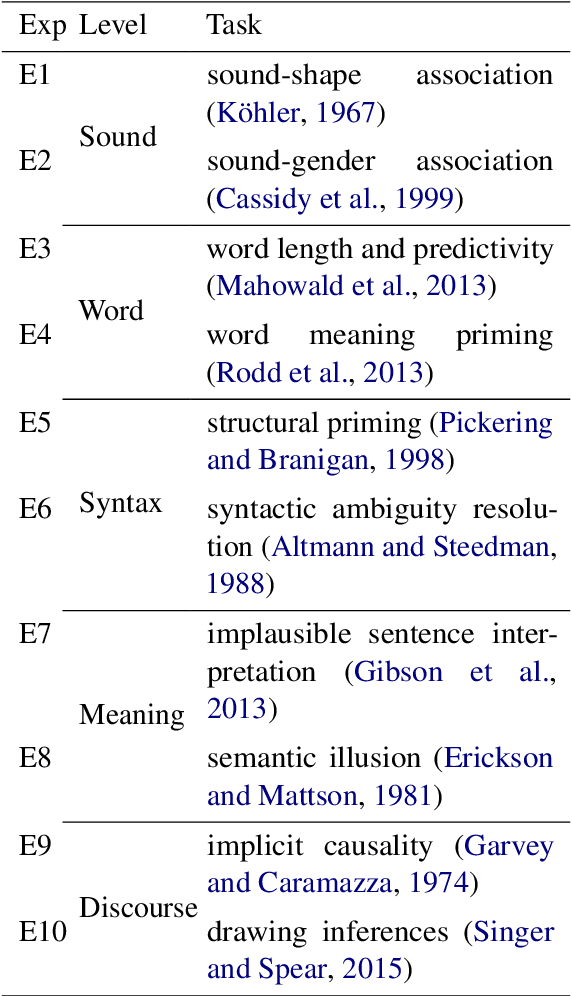
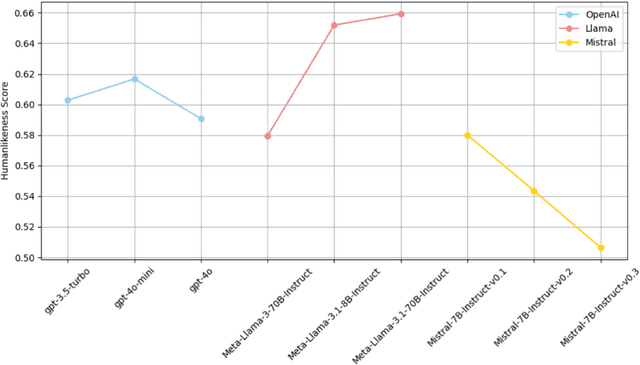
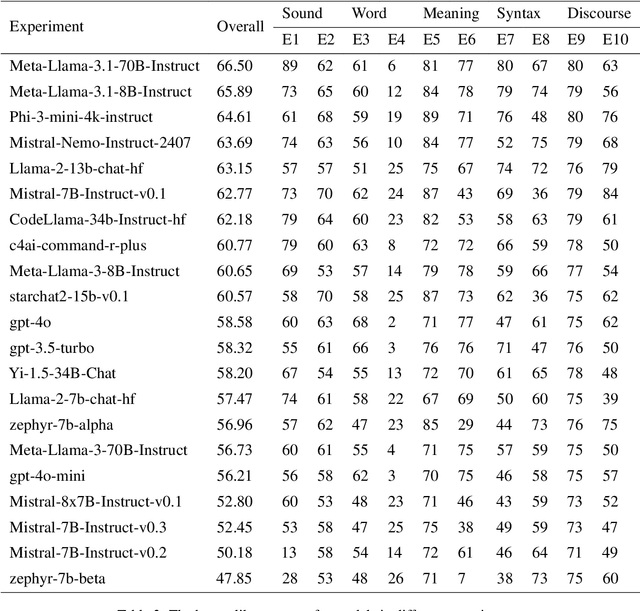
As synthetic data becomes increasingly prevalent in training language models, particularly through generated dialogue, concerns have emerged that these models may deviate from authentic human language patterns, potentially losing the richness and creativity inherent in human communication. This highlights the critical need to assess the humanlikeness of language models in real-world language use. In this paper, we present a comprehensive humanlikeness benchmark (HLB) evaluating 20 large language models (LLMs) using 10 psycholinguistic experiments designed to probe core linguistic aspects, including sound, word, syntax, semantics, and discourse (see https://huggingface.co/spaces/XufengDuan/HumanLikeness). To anchor these comparisons, we collected responses from over 2,000 human participants and compared them to outputs from the LLMs in these experiments. For rigorous evaluation, we developed a coding algorithm that accurately identified language use patterns, enabling the extraction of response distributions for each task. By comparing the response distributions between human participants and LLMs, we quantified humanlikeness through distributional similarity. Our results reveal fine-grained differences in how well LLMs replicate human responses across various linguistic levels. Importantly, we found that improvements in other performance metrics did not necessarily lead to greater humanlikeness, and in some cases, even resulted in a decline. By introducing psycholinguistic methods to model evaluation, this benchmark offers the first framework for systematically assessing the humanlikeness of LLMs in language use.
CTP-LLM: Clinical Trial Phase Transition Prediction Using Large Language Models
Aug 20, 2024New medical treatment development requires multiple phases of clinical trials. Despite the significant human and financial costs of bringing a drug to market, less than 20% of drugs in testing will make it from the first phase to final approval. Recent literature indicates that the design of the trial protocols significantly contributes to trial performance. We investigated Clinical Trial Outcome Prediction (CTOP) using trial design documents to predict phase transitions automatically. We propose CTP-LLM, the first Large Language Model (LLM) based model for CTOP. We also introduce the PhaseTransition (PT) Dataset; which labels trials based on their progression through the regulatory process and serves as a benchmark for CTOP evaluation. Our fine-tuned GPT-3.5-based model (CTP-LLM) predicts clinical trial phase transition by analyzing the trial's original protocol texts without requiring human-selected features. CTP-LLM achieves a 67% accuracy rate in predicting trial phase transitions across all phases and a 75% accuracy rate specifically in predicting the transition from Phase~III to final approval. Our experimental performance highlights the potential of LLM-powered applications in forecasting clinical trial outcomes and assessing trial design.
Semantic Editing On Segmentation Map Via Multi-Expansion Loss
Oct 16, 2020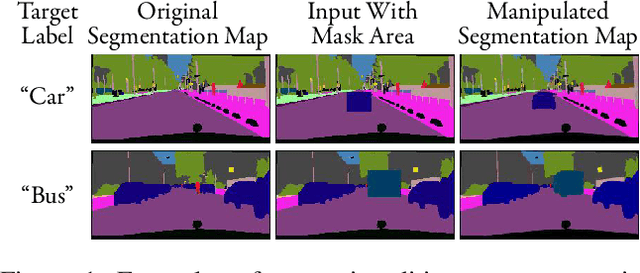

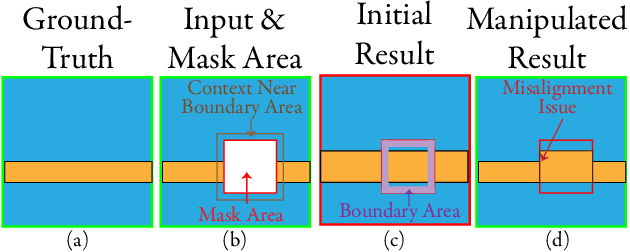
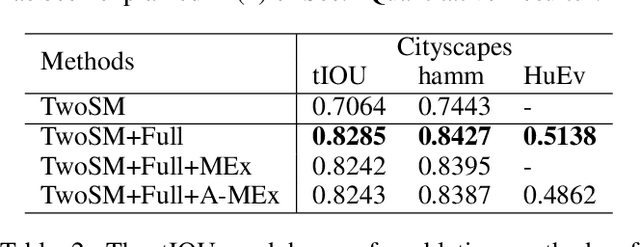
Semantic editing on segmentation map has been proposed as an intermediate interface for image generation, because it provides flexible and strong assistance in various image generation tasks. This paper aims to improve quality of edited segmentation map conditioned on semantic inputs. Even though recent studies apply global and local adversarial losses extensively to generate images for higher image quality, we find that they suffer from the misalignment of the boundary area in the mask area. To address this, we propose MExGAN for semantic editing on segmentation map, which uses a novel Multi-Expansion (MEx) loss implemented by adversarial losses on MEx areas. Each MEx area has the mask area of the generation as the majority and the boundary of original context as the minority. To boost convenience and stability of MEx loss, we further propose an Approximated MEx (A-MEx) loss. Besides, in contrast to previous model that builds training data for semantic editing on segmentation map with part of the whole image, which leads to model performance degradation, MExGAN applies the whole image to build the training data. Extensive experiments on semantic editing on segmentation map and natural image inpainting show competitive results on four datasets.