 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Large Language Models Plan Answer Positions? Position Bias in Multiple-Choice Question Generation
May 03, 2026Large language models (LLMs) are increasingly used to generate multiple-choice questions (MCQs), where correct answers should ideally be uniformly distributed across options. However, we observe that LLMs exhibit systematic position biases during generation. Through extensive experiments with 10 LLMs and 5 vision-language models (VLMs) on three MCQ generation tasks, we show that these biases are structured, with similar patterns emerging within model families. To investigate the underlying mechanisms, we conduct probing experiments and find that hidden representations in the question stem encode predictive signals of the correct answer position, suggesting that answer position may be implicitly planned during generation. Building on this insight, we apply activation steering to manipulate internal representations and influence answer position. Our results show that steering can partially control positional preferences and substantially shift answer position distributions. Our findings provide a practical framework for studying implicit positional planning in LLMs and highlight the importance of controllable generation for reliable MCQ construction and evaluation.
Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models
Jan 20, 2026Mechanistic Interpretability (MI) has emerged as a vital approach to demystify the opaque decision-making of Large Language Models (LLMs). However, existing reviews primarily treat MI as an observational science, summarizing analytical insights while lacking a systematic framework for actionable intervention. To bridge this gap, we present a practical survey structured around the pipeline: "Locate, Steer, and Improve." We formally categorize Localizing (diagnosis) and Steering (intervention) methods based on specific Interpretable Objects to establish a rigorous intervention protocol. Furthermore, we demonstrate how this framework enables tangible improvements in Alignment, Capability, and Efficiency, effectively operationalizing MI as an actionable methodology for model optimization. The curated paper list of this work is available at https://github.com/rattlesnakey/Awesome-Actionable-MI-Survey.
SCALPEL: Selective Capability Ablation via Low-rank Parameter Editing for Large Language Model Interpretability Analysis
Jan 12, 2026Large language models excel across diverse domains, yet their deployment in healthcare, legal systems, and autonomous decision-making remains limited by incomplete understanding of their internal mechanisms. As these models integrate into high-stakes systems, understanding how they encode capabilities has become fundamental to interpretability research. Traditional approaches identify important modules through gradient attribution or activation analysis, assuming specific capabilities map to specific components. However, this oversimplifies neural computation: modules may contribute to multiple capabilities simultaneously, while single capabilities may distribute across multiple modules. These coarse-grained analyses fail to capture fine-grained, distributed capability encoding. We present SCALPEL (Selective Capability Ablation via Low-rank Parameter Editing for Large language models), a framework representing capabilities as low-rank parameter subspaces rather than discrete modules. Our key insight is that capabilities can be characterized by low-rank modifications distributed across layers and modules, enabling precise capability removal without affecting others. By training LoRA adapters to reduce distinguishing correct from incorrect answers while preserving general language modeling quality, SCALPEL identifies low-rank representations responsible for particular capabilities while remaining disentangled from others. Experiments across diverse capability and linguistic tasks from BLiMP demonstrate that SCALPEL successfully removes target capabilities while preserving general capabilities, providing fine-grained insights into capability distribution across parameter space. Results reveal that capabilities exhibit low-rank structure and can be selectively ablated through targeted parameter-space interventions, offering nuanced understanding of capability encoding in LLMs.
How Syntax Specialization Emerges in Language Models
May 26, 2025Large language models (LLMs) have been found to develop surprising internal specializations: Individual neurons, attention heads, and circuits become selectively sensitive to syntactic structure, reflecting patterns observed in the human brain. While this specialization is well-documented, how it emerges during training and what influences its development remains largely unknown. In this work, we tap into the black box of specialization by tracking its formation over time. By quantifying internal syntactic consistency across minimal pairs from various syntactic phenomena, we identify a clear developmental trajectory: Syntactic sensitivity emerges gradually, concentrates in specific layers, and exhibits a 'critical period' of rapid internal specialization. This process is consistent across architectures and initialization parameters (e.g., random seeds), and is influenced by model scale and training data. We therefore reveal not only where syntax arises in LLMs but also how some models internalize it during training. To support future research, we will release the code, models, and training checkpoints upon acceptance.
Distinct social-linguistic processing between humans and large audio-language models: Evidence from model-brain alignment
Mar 25, 2025



Voice-based AI development faces unique challenges in processing both linguistic and paralinguistic information. This study compares how large audio-language models (LALMs) and humans integrate speaker characteristics during speech comprehension, asking whether LALMs process speaker-contextualized language in ways that parallel human cognitive mechanisms. We compared two LALMs' (Qwen2-Audio and Ultravox 0.5) processing patterns with human EEG responses. Using surprisal and entropy metrics from the models, we analyzed their sensitivity to speaker-content incongruency across social stereotype violations (e.g., a man claiming to regularly get manicures) and biological knowledge violations (e.g., a man claiming to be pregnant). Results revealed that Qwen2-Audio exhibited increased surprisal for speaker-incongruent content and its surprisal values significantly predicted human N400 responses, while Ultravox 0.5 showed limited sensitivity to speaker characteristics. Importantly, neither model replicated the human-like processing distinction between social violations (eliciting N400 effects) and biological violations (eliciting P600 effects). These findings reveal both the potential and limitations of current LALMs in processing speaker-contextualized language, and suggest differences in social-linguistic processing mechanisms between humans and LALMs.
Are LLMs Good Literature Review Writers? Evaluating the Literature Review Writing Ability of Large Language Models
Dec 18, 2024



The literature review is a crucial form of academic writing that involves complex processes of literature collection, organization, and summarization. The emergence of large language models (LLMs) has introduced promising tools to automate these processes. However, their actual capabilities in writing comprehensive literature reviews remain underexplored, such as whether they can generate accurate and reliable references. To address this gap, we propose a framework to assess the literature review writing ability of LLMs automatically. We evaluate the performance of LLMs across three tasks: generating references, writing abstracts, and writing literature reviews. We employ external tools for a multidimensional evaluation, which includes assessing hallucination rates in references, semantic coverage, and factual consistency with human-written context. By analyzing the experimental results, we find that, despite advancements, even the most sophisticated models still cannot avoid generating hallucinated references. Additionally, different models exhibit varying performance in literature review writing across different disciplines.
Unveiling Language Competence Neurons: A Psycholinguistic Approach to Model Interpretability
Sep 24, 2024As large language models (LLMs) become advance in their linguistic capacity, understanding how they capture aspects of language competence remains a significant challenge. This study therefore employs psycholinguistic paradigms, which are well-suited for probing deeper cognitive aspects of language processing, to explore neuron-level representations in language model across three tasks: sound-shape association, sound-gender association, and implicit causality. Our findings indicate that while GPT-2-XL struggles with the sound-shape task, it demonstrates human-like abilities in both sound-gender association and implicit causality. Targeted neuron ablation and activation manipulation reveal a crucial relationship: when GPT-2-XL displays a linguistic ability, specific neurons correspond to that competence; conversely, the absence of such an ability indicates a lack of specialized neurons. This study is the first to utilize psycholinguistic experiments to investigate deep language competence at the neuron level, providing a new level of granularity in model interpretability and insights into the internal mechanisms driving language ability in transformer based LLMs.
HLB: Benchmarking LLMs' Humanlikeness in Language Use
Sep 24, 2024
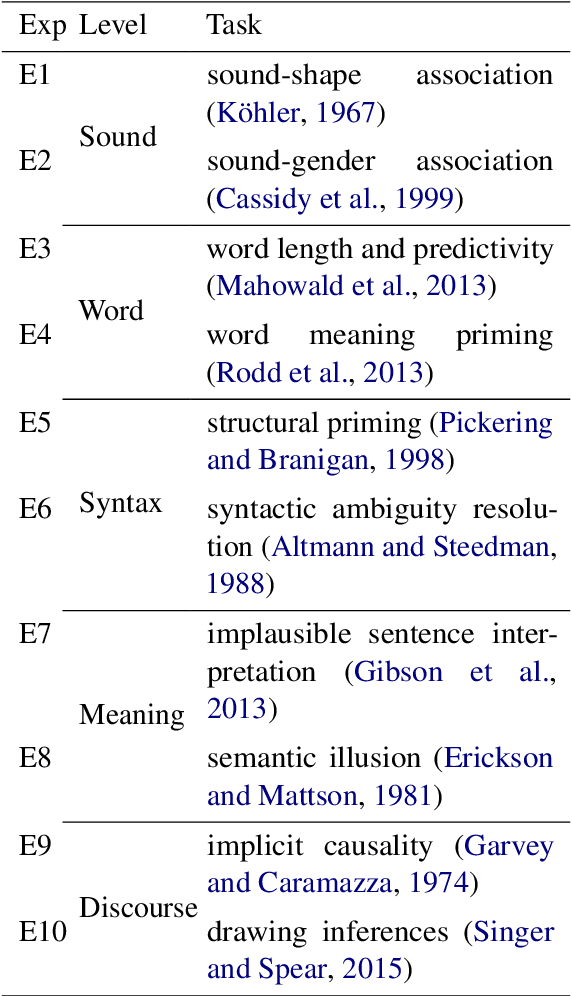
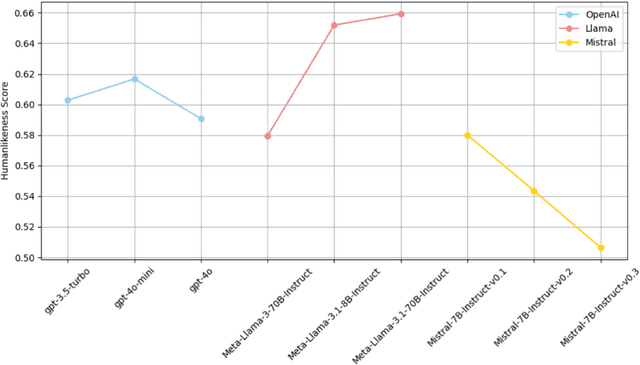
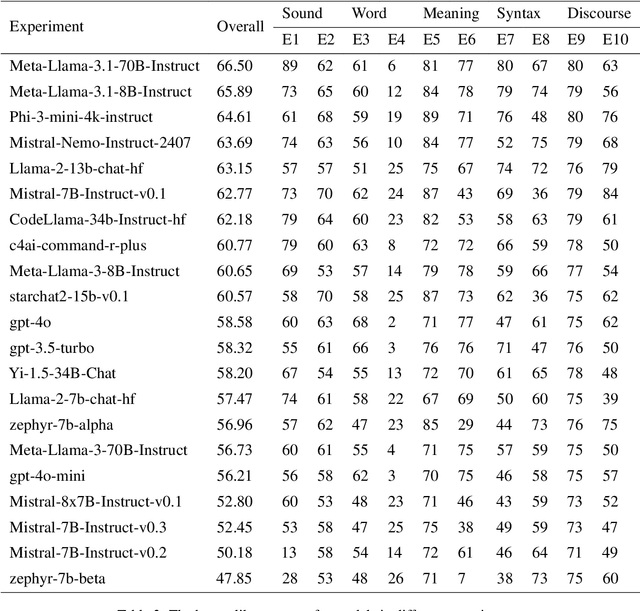
As synthetic data becomes increasingly prevalent in training language models, particularly through generated dialogue, concerns have emerged that these models may deviate from authentic human language patterns, potentially losing the richness and creativity inherent in human communication. This highlights the critical need to assess the humanlikeness of language models in real-world language use. In this paper, we present a comprehensive humanlikeness benchmark (HLB) evaluating 20 large language models (LLMs) using 10 psycholinguistic experiments designed to probe core linguistic aspects, including sound, word, syntax, semantics, and discourse (see https://huggingface.co/spaces/XufengDuan/HumanLikeness). To anchor these comparisons, we collected responses from over 2,000 human participants and compared them to outputs from the LLMs in these experiments. For rigorous evaluation, we developed a coding algorithm that accurately identified language use patterns, enabling the extraction of response distributions for each task. By comparing the response distributions between human participants and LLMs, we quantified humanlikeness through distributional similarity. Our results reveal fine-grained differences in how well LLMs replicate human responses across various linguistic levels. Importantly, we found that improvements in other performance metrics did not necessarily lead to greater humanlikeness, and in some cases, even resulted in a decline. By introducing psycholinguistic methods to model evaluation, this benchmark offers the first framework for systematically assessing the humanlikeness of LLMs in language use.
Grammaticality Representation in ChatGPT as Compared to Linguists and Laypeople
Jun 17, 2024



Large language models (LLMs) have demonstrated exceptional performance across various linguistic tasks. However, it remains uncertain whether LLMs have developed human-like fine-grained grammatical intuition. This preregistered study (https://osf.io/t5nes) presents the first large-scale investigation of ChatGPT's grammatical intuition, building upon a previous study that collected laypeople's grammatical judgments on 148 linguistic phenomena that linguists judged to be grammatical, ungrammatical, or marginally grammatical (Sprouse, Schutze, & Almeida, 2013). Our primary focus was to compare ChatGPT with both laypeople and linguists in the judgement of these linguistic constructions. In Experiment 1, ChatGPT assigned ratings to sentences based on a given reference sentence. Experiment 2 involved rating sentences on a 7-point scale, and Experiment 3 asked ChatGPT to choose the more grammatical sentence from a pair. Overall, our findings demonstrate convergence rates ranging from 73% to 95% between ChatGPT and linguists, with an overall point-estimate of 89%. Significant correlations were also found between ChatGPT and laypeople across all tasks, though the correlation strength varied by task. We attribute these results to the psychometric nature of the judgment tasks and the differences in language processing styles between humans and LLMs.
MacBehaviour: An R package for behavioural experimentation on large language models
May 13, 2024There has been increasing interest in investigating the behaviours of large language models (LLMs) and LLM-powered chatbots by treating an LLM as a participant in a psychological experiment. We therefore developed an R package called "MacBehaviour" that aims to interact with more than 60 language models in one package (e.g., OpenAI's GPT family, the Claude family, Gemini, Llama family, and open-source models) and streamline the experimental process of LLMs behaviour experiments. The package offers a comprehensive set of functions designed for LLM experiments, covering experiment design, stimuli presentation, model behaviour manipulation, logging response and token probability. To demonstrate the utility and effectiveness of "MacBehaviour," we conducted three validation experiments on three LLMs (GPT-3.5, Llama-2 7B, and Vicuna-1.5 13B) to replicate sound-gender association in LLMs. The results consistently showed that they exhibit human-like tendencies to infer gender from novel personal names based on their phonology, as previously demonstrated (Cai et al., 2023). In summary, "MacBehaviour" is an R package for machine behaviour studies which offers a user-friendly interface and comprehensive features to simplify and standardize the experimental process.