 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Evolution Under Zeroth-Order Optimization: A Neural Tangent Kernel Perspective
Mar 22, 2026Zeroth-order (ZO) optimization enables memory-efficient training of neural networks by estimating gradients via forward passes only, eliminating the need for backpropagation. However, the stochastic nature of gradient estimation significantly obscures the training dynamics, in contrast to the well-characterized behavior of first-order methods under Neural Tangent Kernel (NTK) theory. To address this, we introduce the Neural Zeroth-order Kernel (NZK) to describe model evolution in function space under ZO updates. For linear models, we prove that the expected NZK remains constant throughout training and depends explicitly on the first and second moments of the random perturbation directions. This invariance yields a closed-form expression for model evolution under squared loss. We further extend the analysis to linearized neural networks. Interpreting ZO updates as kernel gradient descent via NZK provides a novel perspective for potentially accelerating convergence. Extensive experiments across synthetic and real-world datasets (including MNIST, CIFAR-10, and Tiny ImageNet) validate our theoretical results and demonstrate acceleration when using a single shared random vector.
Developing Foundation Models for Universal Segmentation from 3D Whole-Body Positron Emission Tomography
Mar 12, 2026Positron emission tomography (PET) is a key nuclear medicine imaging modality that visualizes radiotracer distributions to quantify in vivo physiological and metabolic processes, playing an irreplaceable role in disease management. Despite its clinical importance, the development of deep learning models for quantitative PET image analysis remains severely limited, driven by both the inherent segmentation challenge from PET's paucity of anatomical contrast and the high costs of data acquisition and annotation. To bridge this gap, we develop generalist foundational models for universal segmentation from 3D whole-body PET imaging. We first build the largest and most comprehensive PET dataset to date, comprising 11041 3D whole-body PET scans with 59831 segmentation masks for model development. Based on this dataset, we present SegAnyPET, an innovative foundational model with general-purpose applicability to diverse segmentation tasks. Built on a 3D architecture with a prompt engineering strategy for mask generation, SegAnyPET enables universal and scalable organ and lesion segmentation, supports efficient human correction with minimal effort, and enables a clinical human-in-the-loop workflow. Extensive evaluations on multi-center, multi-tracer, multi-disease datasets demonstrate that SegAnyPET achieves strong zero-shot performance across a wide range of segmentation tasks, highlighting its potential to advance the clinical applications of molecular imaging.
PET2Rep: Towards Vision-Language Model-Drived Automated Radiology Report Generation for Positron Emission Tomography
Aug 06, 2025Positron emission tomography (PET) is a cornerstone of modern oncologic and neurologic imaging, distinguished by its unique ability to illuminate dynamic metabolic processes that transcend the anatomical focus of traditional imaging technologies. Radiology reports are essential for clinical decision making, yet their manual creation is labor-intensive and time-consuming. Recent advancements of vision-language models (VLMs) have shown strong potential in medical applications, presenting a promising avenue for automating report generation. However, existing applications of VLMs in the medical domain have predominantly focused on structural imaging modalities, while the unique characteristics of molecular PET imaging have largely been overlooked. To bridge the gap, we introduce PET2Rep, a large-scale comprehensive benchmark for evaluation of general and medical VLMs for radiology report generation for PET images. PET2Rep stands out as the first dedicated dataset for PET report generation with metabolic information, uniquely capturing whole-body image-report pairs that cover dozens of organs to fill the critical gap in existing benchmarks and mirror real-world clinical comprehensiveness. In addition to widely recognized natural language generation metrics, we introduce a series of clinical efficiency metrics to evaluate the quality of radiotracer uptake pattern description in key organs in generated reports. We conduct a head-to-head comparison of 30 cutting-edge general-purpose and medical-specialized VLMs. The results show that the current state-of-the-art VLMs perform poorly on PET report generation task, falling considerably short of fulfilling practical needs. Moreover, we identify several key insufficiency that need to be addressed to advance the development in medical applications.
Towards Holistic Visual Quality Assessment of AI-Generated Videos: A LLM-Based Multi-Dimensional Evaluation Model
Jun 05, 2025



The development of AI-Generated Video (AIGV) technology has been remarkable in recent years, significantly transforming the paradigm of video content production. However, AIGVs still suffer from noticeable visual quality defects, such as noise, blurriness, frame jitter and low dynamic degree, which severely impact the user's viewing experience. Therefore, an effective automatic visual quality assessment is of great importance for AIGV content regulation and generative model improvement. In this work, we decompose the visual quality of AIGVs into three dimensions: technical quality, motion quality, and video semantics. For each dimension, we design corresponding encoder to achieve effective feature representation. Moreover, considering the outstanding performance of large language models (LLMs) in various vision and language tasks, we introduce a LLM as the quality regression module. To better enable the LLM to establish reasoning associations between multi-dimensional features and visual quality, we propose a specially designed multi-modal prompt engineering framework. Additionally, we incorporate LoRA fine-tuning technology during the training phase, allowing the LLM to better adapt to specific tasks. Our proposed method achieved \textbf{second place} in the NTIRE 2025 Quality Assessment of AI-Generated Content Challenge: Track 2 AI Generated video, demonstrating its effectiveness. Codes can be obtained at https://github.com/QiZelu/AIGVEval.
HaLoRA: Hardware-aware Low-Rank Adaptation for Large Language Models Based on Hybrid Compute-in-Memory Architecture
Feb 27, 2025
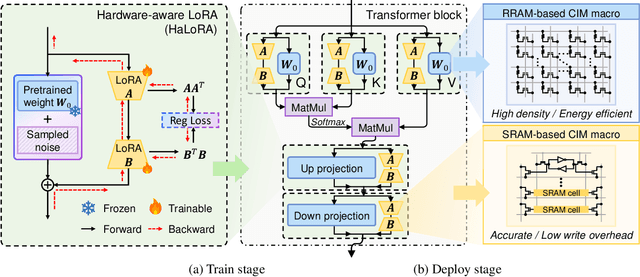
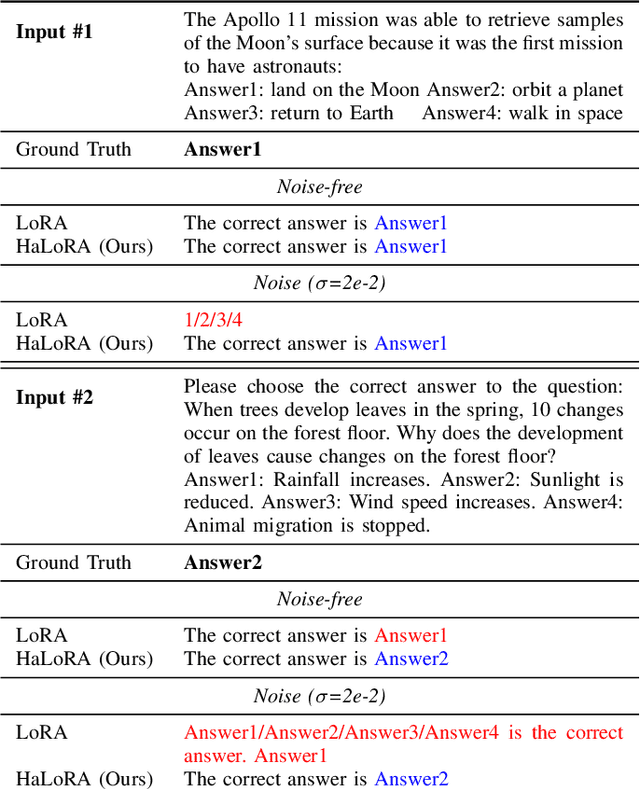
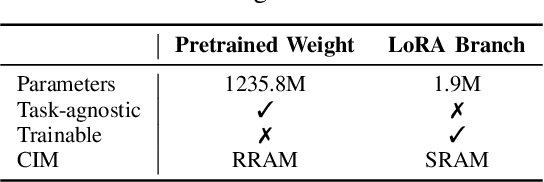
Low-rank adaptation (LoRA) is a predominant parameter-efficient finetuning method to adapt large language models (LLMs) for downstream tasks. In this paper, we first propose to deploy the LoRA-finetuned LLMs on the hybrid compute-in-memory (CIM) architecture (i.e., pretrained weights onto RRAM and LoRA onto SRAM). To address performance degradation from RRAM's inherent noise, we design a novel Hardware-aware Low-rank Adaption (HaLoRA) method, aiming to train a LoRA branch that is both robust and accurate by aligning the training objectives under both ideal and noisy conditions. Experiments finetuning LLaMA 3.2 1B and 3B demonstrate HaLoRA's effectiveness across multiple reasoning tasks, achieving up to 22.7 improvement in average score while maintaining robustness at various noise levels.
Comprehensive Subjective and Objective Evaluation Method for Text-generated Video
Jan 15, 2025



Recent text-to-video (T2V) technology advancements, as demonstrated by models such as Gen3, Pika, and Sora, have significantly broadened its applicability and popularity. This progress has created a growing demand for accurate quality assessment metrics to evaluate the perceptual quality of text-generated videos and optimize video generation models. However, assessing the quality of text-generated videos remains challenging due to the presence of highly complex distortions, such as unnatural actions and phenomena that defy human cognition. To address these challenges, we constructed a large-scale benchmark dataset for \textbf{T}ext-generated \textbf{V}ideo \textbf{eval}uation, \textbf{T2VEval-Bench}, comprising 148 textual words and 1,783 videos generated by 12 models. During the subjective evaluation, we collected five key scores: overall impression, video quality, aesthetic quality, realness, and text-video consistency. For objective evaluation, we developed the \textbf{T2VEval} model, which assesses videos across three branches: quality, authenticity, and consistency. Using an attention-based fusion module, T2VEval effectively integrates features from each branch and predicts scores with the aid of a large oracle model. Additionally, we implemented a progressive training strategy, enabling each branch to learn targeted knowledge while maintaining synergy with the others. Experimental results demonstrate that T2VEval achieves state-of-the-art performance across multiple metrics. The dataset and code will be open-sourced upon completion of the follow-up work.
Does ChatGPT resemble humans in language use?
Mar 10, 2023


Large language models (LLMs) and LLM-driven chatbots such as ChatGPT have shown remarkable capacities in comprehending and producing language. However, their internal workings remain a black box in cognitive terms, and it is unclear whether LLMs and chatbots can develop humanlike characteristics in language use. Cognitive scientists have devised many experiments that probe, and have made great progress in explaining, how people process language. We subjected ChatGPT to 12 of these experiments, pre-registered and with 1,000 runs per experiment. In 10 of them, ChatGPT replicated the human pattern of language use. It associated unfamiliar words with different meanings depending on their forms, continued to access recently encountered meanings of ambiguous words, reused recent sentence structures, reinterpreted implausible sentences that were likely to have been corrupted by noise, glossed over errors, drew reasonable inferences, associated causality with different discourse entities according to verb semantics, and accessed different meanings and retrieved different words depending on the identity of its interlocutor. However, unlike humans, it did not prefer using shorter words to convey less informative content and it did not use context to disambiguate syntactic ambiguities. We discuss how these convergences and divergences may occur in the transformer architecture. Overall, these experiments demonstrate that LLM-driven chatbots like ChatGPT are capable of mimicking human language processing to a great extent, and that they have the potential to provide insights into how people learn and use language.
Mesoscopic modeling of hidden spiking neurons
May 26, 2022

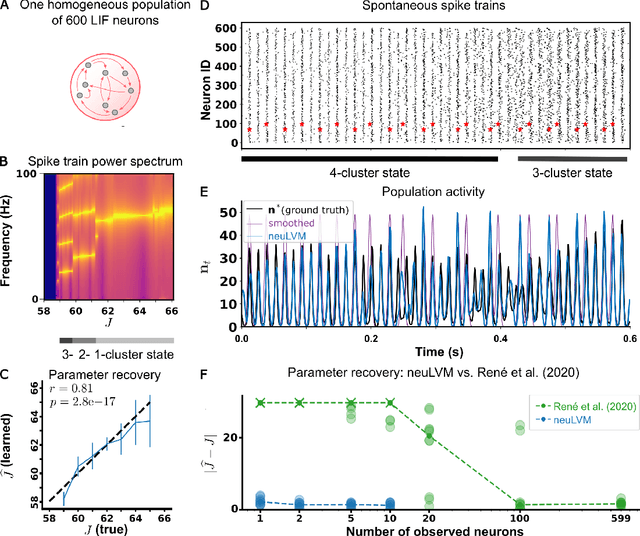

Can we use spiking neural networks (SNN) as generative models of multi-neuronal recordings, while taking into account that most neurons are unobserved? Modeling the unobserved neurons with large pools of hidden spiking neurons leads to severely underconstrained problems that are hard to tackle with maximum likelihood estimation. In this work, we use coarse-graining and mean-field approximations to derive a bottom-up, neuronally-grounded latent variable model (neuLVM), where the activity of the unobserved neurons is reduced to a low-dimensional mesoscopic description. In contrast to previous latent variable models, neuLVM can be explicitly mapped to a recurrent, multi-population SNN, giving it a transparent biological interpretation. We show, on synthetic spike trains, that a few observed neurons are sufficient for neuLVM to perform efficient model inversion of large SNNs, in the sense that it can recover connectivity parameters, infer single-trial latent population activity, reproduce ongoing metastable dynamics, and generalize when subjected to perturbations mimicking photo-stimulation.
Multilayer Perceptron Based Stress Evolution Analysis under DC Current Stressing for Multi-segment Wires
May 17, 2022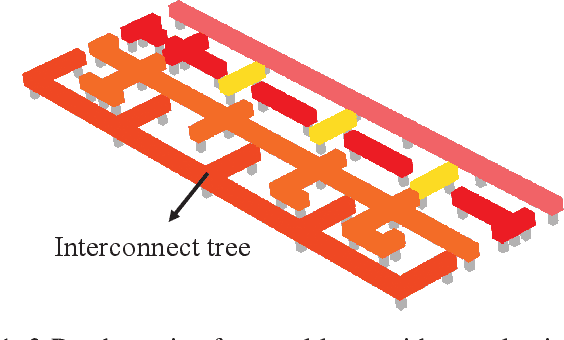
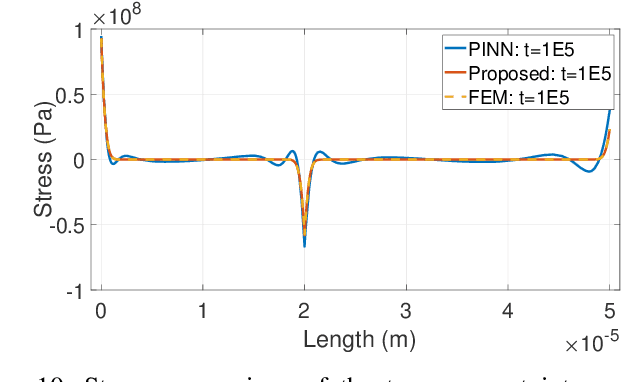
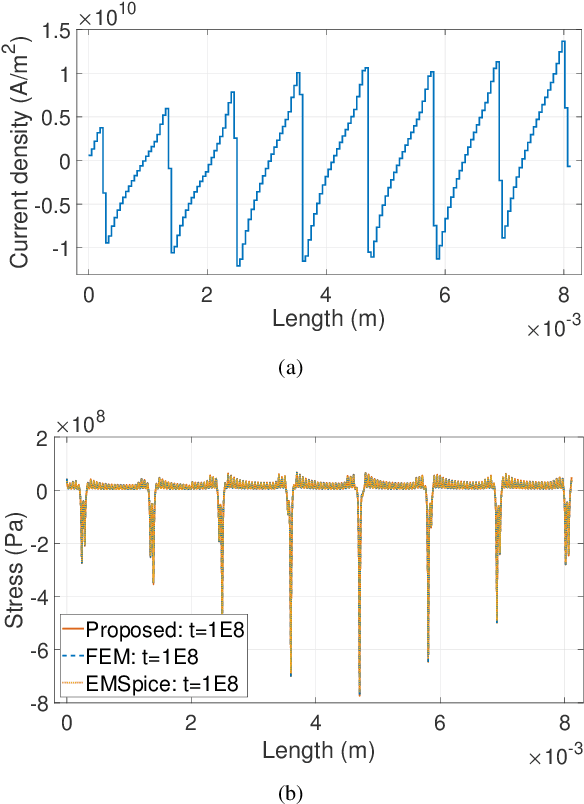
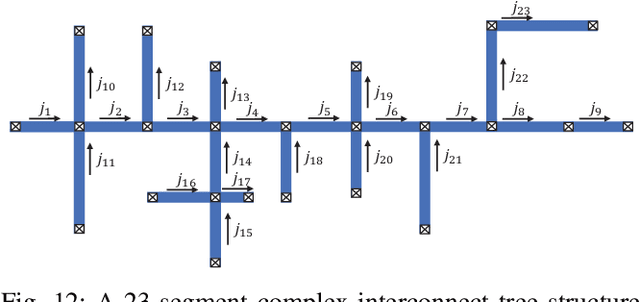
Electromigration (EM) is one of the major concerns in the reliability analysis of very large scale integration (VLSI) systems due to the continuous technology scaling. Accurately predicting the time-to-failure of integrated circuits (IC) becomes increasingly important for modern IC design. However, traditional methods are often not sufficiently accurate, leading to undesirable over-design especially in advanced technology nodes. In this paper, we propose an approach using multilayer perceptrons (MLP) to compute stress evolution in the interconnect trees during the void nucleation phase. The availability of a customized trial function for neural network training holds the promise of finding dynamic mesh-free stress evolution on complex interconnect trees under time-varying temperatures. Specifically, we formulate a new objective function considering the EM-induced coupled partial differential equations (PDEs), boundary conditions (BCs), and initial conditions to enforce the physics-based constraints in the spatial-temporal domain. The proposed model avoids meshing and reduces temporal iterations compared with conventional numerical approaches like FEM. Numerical results confirm its advantages on accuracy and computational performance.
Fitting summary statistics of neural data with a differentiable spiking network simulator
Jun 18, 2021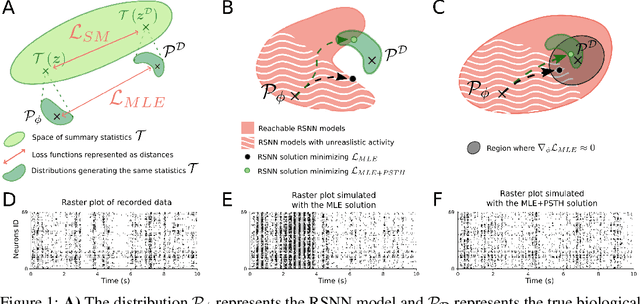
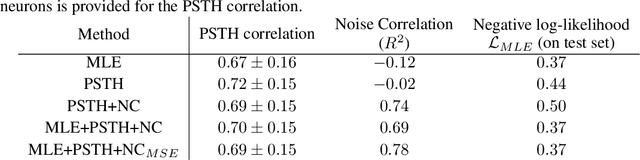
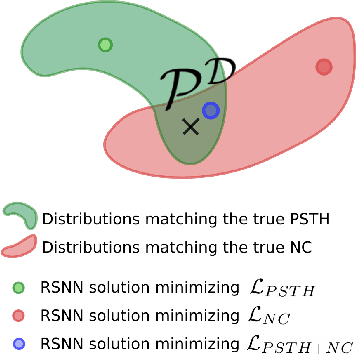

Fitting network models to neural activity is becoming an important tool in neuroscience. A popular approach is to model a brain area with a probabilistic recurrent spiking network whose parameters maximize the likelihood of the recorded activity. Although this is widely used, we show that the resulting model does not produce realistic neural activity and wrongly estimates the connectivity matrix when neurons that are not recorded have a substantial impact on the recorded network. To correct for this, we suggest to augment the log-likelihood with terms that measure the dissimilarity between simulated and recorded activity. This dissimilarity is defined via summary statistics commonly used in neuroscience, and the optimization is efficient because it relies on back-propagation through the stochastically simulated spike trains. We analyze this method theoretically and show empirically that it generates more realistic activity statistics and recovers the connectivity matrix better than other methods.