 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCALPEL: Selective Capability Ablation via Low-rank Parameter Editing for Large Language Model Interpretability Analysis
Jan 12, 2026Large language models excel across diverse domains, yet their deployment in healthcare, legal systems, and autonomous decision-making remains limited by incomplete understanding of their internal mechanisms. As these models integrate into high-stakes systems, understanding how they encode capabilities has become fundamental to interpretability research. Traditional approaches identify important modules through gradient attribution or activation analysis, assuming specific capabilities map to specific components. However, this oversimplifies neural computation: modules may contribute to multiple capabilities simultaneously, while single capabilities may distribute across multiple modules. These coarse-grained analyses fail to capture fine-grained, distributed capability encoding. We present SCALPEL (Selective Capability Ablation via Low-rank Parameter Editing for Large language models), a framework representing capabilities as low-rank parameter subspaces rather than discrete modules. Our key insight is that capabilities can be characterized by low-rank modifications distributed across layers and modules, enabling precise capability removal without affecting others. By training LoRA adapters to reduce distinguishing correct from incorrect answers while preserving general language modeling quality, SCALPEL identifies low-rank representations responsible for particular capabilities while remaining disentangled from others. Experiments across diverse capability and linguistic tasks from BLiMP demonstrate that SCALPEL successfully removes target capabilities while preserving general capabilities, providing fine-grained insights into capability distribution across parameter space. Results reveal that capabilities exhibit low-rank structure and can be selectively ablated through targeted parameter-space interventions, offering nuanced understanding of capability encoding in LLMs.
CAST: Compositional Analysis via Spectral Tracking for Understanding Transformer Layer Functions
Oct 16, 2025Large language models have achieved remarkable success but remain largely black boxes with poorly understood internal mechanisms. To address this limitation, many researchers have proposed various interpretability methods including mechanistic analysis, probing classifiers, and activation visualization, each providing valuable insights from different perspectives. Building upon this rich landscape of complementary approaches, we introduce CAST (Compositional Analysis via Spectral Tracking), a probe-free framework that contributes a novel perspective by analyzing transformer layer functions through direct transformation matrix estimation and comprehensive spectral analysis. CAST offers complementary insights to existing methods by estimating the realized transformation matrices for each layer using Moore-Penrose pseudoinverse and applying spectral analysis with six interpretable metrics characterizing layer behavior. Our analysis reveals distinct behaviors between encoder-only and decoder-only models, with decoder models exhibiting compression-expansion cycles while encoder models maintain consistent high-rank processing. Kernel analysis further demonstrates functional relationship patterns between layers, with CKA similarity matrices clearly partitioning layers into three phases: feature extraction, compression, and specialization.
How Syntax Specialization Emerges in Language Models
May 26, 2025Large language models (LLMs) have been found to develop surprising internal specializations: Individual neurons, attention heads, and circuits become selectively sensitive to syntactic structure, reflecting patterns observed in the human brain. While this specialization is well-documented, how it emerges during training and what influences its development remains largely unknown. In this work, we tap into the black box of specialization by tracking its formation over time. By quantifying internal syntactic consistency across minimal pairs from various syntactic phenomena, we identify a clear developmental trajectory: Syntactic sensitivity emerges gradually, concentrates in specific layers, and exhibits a 'critical period' of rapid internal specialization. This process is consistent across architectures and initialization parameters (e.g., random seeds), and is influenced by model scale and training data. We therefore reveal not only where syntax arises in LLMs but also how some models internalize it during training. To support future research, we will release the code, models, and training checkpoints upon acceptance.
Probabilistic adaptation of language comprehension for individual speakers: Evidence from neural oscillations
Feb 03, 2025Listeners adapt language comprehension based on their mental representations of speakers, but how these representations are dynamically updated remains unclear. We investigated whether listeners probabilistically adapt their comprehension based on the likelihood of speakers producing stereotype-incongruent utterances. Our findings reveal two potential mechanisms: a speaker-general mechanism that adjusts overall expectations about speaker-content relationships, and a speaker-specific mechanism that updates individual speaker models. In two EEG experiments, participants heard speakers make stereotype-congruent or incongruent utterances, with incongruency base rate manipulated between blocks. In Experiment 1, speaker incongruency modulated both high-beta (21-30 Hz) and theta (4-6 Hz) oscillations: incongruent utterances decreased oscillatory power in low base rate condition but increased it in high base rate condition. The theta effect varied with listeners' openness trait: less open participants showed theta increases to speaker-incongruencies, suggesting maintenance of speaker-specific information, while more open participants showed theta decreases, indicating flexible model updating. In Experiment 2, we dissociated base rate from the target speaker by manipulating the overall base rate using an alternative non-target speaker. Only the high-beta effect persisted, showing power decrease for speaker-incongruencies in low base rate condition but no effect in high base rate condition. The high-beta oscillations might reflect the speaker-general adjustment, while theta oscillations may index the speaker-specific model updating. These findings provide evidence for how language processing is shaped by social cognition in real time.
Are LLMs Good Literature Review Writers? Evaluating the Literature Review Writing Ability of Large Language Models
Dec 18, 2024



The literature review is a crucial form of academic writing that involves complex processes of literature collection, organization, and summarization. The emergence of large language models (LLMs) has introduced promising tools to automate these processes. However, their actual capabilities in writing comprehensive literature reviews remain underexplored, such as whether they can generate accurate and reliable references. To address this gap, we propose a framework to assess the literature review writing ability of LLMs automatically. We evaluate the performance of LLMs across three tasks: generating references, writing abstracts, and writing literature reviews. We employ external tools for a multidimensional evaluation, which includes assessing hallucination rates in references, semantic coverage, and factual consistency with human-written context. By analyzing the experimental results, we find that, despite advancements, even the most sophisticated models still cannot avoid generating hallucinated references. Additionally, different models exhibit varying performance in literature review writing across different disciplines.
Speaker effects in spoken language comprehension
Dec 10, 2024The identity of a speaker significantly influences spoken language comprehension by affecting both perception and expectation. This review explores speaker effects, focusing on how speaker information impacts language processing. We propose an integrative model featuring the interplay between bottom-up perception-based processes driven by acoustic details and top-down expectation-based processes driven by a speaker model. The acoustic details influence lower-level perception, while the speaker model modulates both lower-level and higher-level processes such as meaning interpretation and pragmatic inferences. We define speaker-idiosyncrasy and speaker-demographics effects and demonstrate how bottom-up and top-down processes interact at various levels in different scenarios. This framework contributes to psycholinguistic theory by offering a comprehensive account of how speaker information interacts with linguistic content to shape message construction. We suggest that speaker effects can serve as indices of a language learner's proficiency and an individual's characteristics of social cognition. We encourage future research to extend these findings to AI speakers, probing the universality of speaker effects across humans and artificial agents.
When A Man Says He Is Pregnant: ERP Evidence for A Rational Account of Speaker-contextualized Language Comprehension
Sep 26, 2024



Spoken language is often, if not always, understood in a context that includes the identities of speakers. For instance, we can easily make sense of an utterance such as "I'm going to have a manicure this weekend" or "The first time I got pregnant I had a hard time" when the utterance is spoken by a woman, but it would be harder to understand when it is spoken by a man. Previous event-related potential (ERP) studies have shown mixed results regarding the neurophysiological responses to such speaker-mismatched utterances, with some reporting an N400 effect and others a P600 effect. In an experiment involving 64 participants, we showed that these different ERP effects reflect distinct cognitive processes employed to resolve the speaker-message mismatch. When possible, the message is integrated with the speaker context to arrive at an interpretation, as in the case of violations of social stereotypes (e.g., men getting a manicure), resulting in an N400 effect. However, when such integration is impossible due to violations of biological knowledge (e.g., men getting pregnant), listeners engage in an error correction process to revise either the perceived utterance or the speaker context, resulting in a P600 effect. Additionally, we found that the social N400 effect decreased as a function of the listener's personality trait of openness, while the biological P600 effect remained robust. Our findings help to reconcile the empirical inconsistencies in the literature and provide a rational account of speaker-contextualized language comprehension.
Unveiling Language Competence Neurons: A Psycholinguistic Approach to Model Interpretability
Sep 24, 2024As large language models (LLMs) become advance in their linguistic capacity, understanding how they capture aspects of language competence remains a significant challenge. This study therefore employs psycholinguistic paradigms, which are well-suited for probing deeper cognitive aspects of language processing, to explore neuron-level representations in language model across three tasks: sound-shape association, sound-gender association, and implicit causality. Our findings indicate that while GPT-2-XL struggles with the sound-shape task, it demonstrates human-like abilities in both sound-gender association and implicit causality. Targeted neuron ablation and activation manipulation reveal a crucial relationship: when GPT-2-XL displays a linguistic ability, specific neurons correspond to that competence; conversely, the absence of such an ability indicates a lack of specialized neurons. This study is the first to utilize psycholinguistic experiments to investigate deep language competence at the neuron level, providing a new level of granularity in model interpretability and insights into the internal mechanisms driving language ability in transformer based LLMs.
HLB: Benchmarking LLMs' Humanlikeness in Language Use
Sep 24, 2024
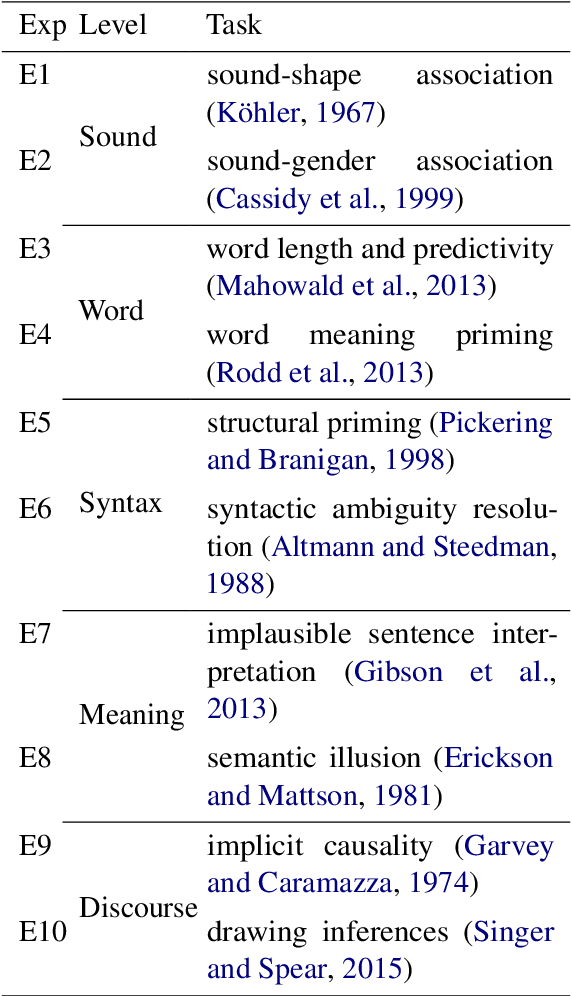
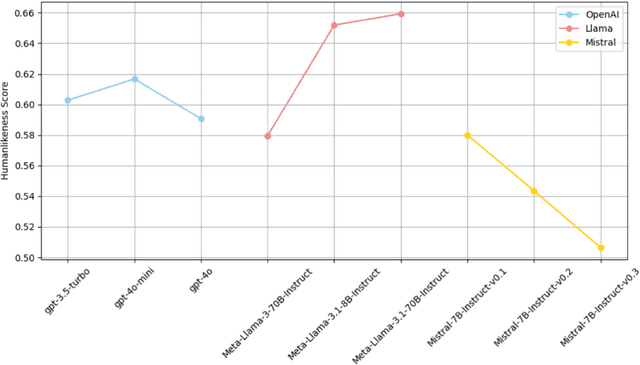
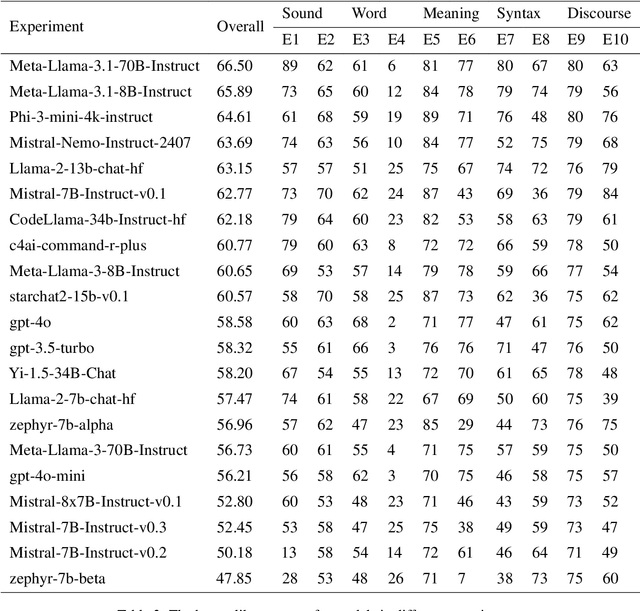
As synthetic data becomes increasingly prevalent in training language models, particularly through generated dialogue, concerns have emerged that these models may deviate from authentic human language patterns, potentially losing the richness and creativity inherent in human communication. This highlights the critical need to assess the humanlikeness of language models in real-world language use. In this paper, we present a comprehensive humanlikeness benchmark (HLB) evaluating 20 large language models (LLMs) using 10 psycholinguistic experiments designed to probe core linguistic aspects, including sound, word, syntax, semantics, and discourse (see https://huggingface.co/spaces/XufengDuan/HumanLikeness). To anchor these comparisons, we collected responses from over 2,000 human participants and compared them to outputs from the LLMs in these experiments. For rigorous evaluation, we developed a coding algorithm that accurately identified language use patterns, enabling the extraction of response distributions for each task. By comparing the response distributions between human participants and LLMs, we quantified humanlikeness through distributional similarity. Our results reveal fine-grained differences in how well LLMs replicate human responses across various linguistic levels. Importantly, we found that improvements in other performance metrics did not necessarily lead to greater humanlikeness, and in some cases, even resulted in a decline. By introducing psycholinguistic methods to model evaluation, this benchmark offers the first framework for systematically assessing the humanlikeness of LLMs in language use.
Grammaticality Representation in ChatGPT as Compared to Linguists and Laypeople
Jun 17, 2024



Large language models (LLMs) have demonstrated exceptional performance across various linguistic tasks. However, it remains uncertain whether LLMs have developed human-like fine-grained grammatical intuition. This preregistered study (https://osf.io/t5nes) presents the first large-scale investigation of ChatGPT's grammatical intuition, building upon a previous study that collected laypeople's grammatical judgments on 148 linguistic phenomena that linguists judged to be grammatical, ungrammatical, or marginally grammatical (Sprouse, Schutze, & Almeida, 2013). Our primary focus was to compare ChatGPT with both laypeople and linguists in the judgement of these linguistic constructions. In Experiment 1, ChatGPT assigned ratings to sentences based on a given reference sentence. Experiment 2 involved rating sentences on a 7-point scale, and Experiment 3 asked ChatGPT to choose the more grammatical sentence from a pair. Overall, our findings demonstrate convergence rates ranging from 73% to 95% between ChatGPT and linguists, with an overall point-estimate of 89%. Significant correlations were also found between ChatGPT and laypeople across all tasks, though the correlation strength varied by task. We attribute these results to the psychometric nature of the judgment tasks and the differences in language processing styles between humans and LLMs.