 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-based Gaussian Splatting for Continuous-Scale Remote Sensing Image Super-Resolution
May 21, 2026High-resolution remote sensing images (RSIs) are crucial for Earth observation applications, yet acquiring them is often limited by sensor constraints and costs. In recent years, generative super-resolution (SR) methods, particularly diffusion models, have made significant progress. However, they typically require slow iterative inference with 40--1000 steps and exhibit limited flexibility in continuous-scale SR settings. To address these issues, we propose FlowGS, a generative reconstruction framework for arbitrary-scale SR of RSIs. FlowGS models the high-frequency detail representations between high- and low-resolution images and learns a continuous probability flow from noise to detail priors via flow matching (FM) constrained by shortcut consistency, thereby reducing generative complexity and improving inference efficiency. Additionally, we employ 2D Gaussian splatting to construct a continuous feature field, thereby enabling flexible reconstruction at arbitrary query locations. Experimental results show that FlowGS delivers competitive perceptual quality compared with existing methods in both continuous-scale and fixed-scale SR settings, with substantially improved inference efficiency.
MapSR: Prompt-Driven Land Cover Map Super-Resolution via Vision Foundation Models
Apr 16, 2026High-resolution (HR) land-cover mapping is often constrained by the high cost of dense HR annotations. We revisit this problem from the perspective of map super-resolution, which enhances coarse low-resolution (LR) land-cover products into HR maps at the resolution of the input imagery. Existing weakly supervised methods can leverage LR labels, but they typically use them to retrain dense predictors with substantial computational cost. We propose MapSR, a prompt-driven framework that decouples supervision from model training. MapSR uses LR labels once to extract class prompts from frozen vision foundation model features through a lightweight linear probe, after which HR mapping proceeds via training-free metric inference and graph-based prediction refinement. Specifically, class prompts are estimated by aggregating high-confidence HR features identified by the linear probe, and HR predictions are obtained by cosine-similarity matching followed by graph-based propagation for spatial refinement. Experiments on the Chesapeake Bay dataset show that MapSR achieves 59.64% mIoU without any HR labels, remaining competitive with the strongest weakly supervised baseline and surpassing a fully supervised baseline. Notably, MapSR reduces trainable parameters by four orders of magnitude and shortens training time from hours to minutes, enabling scalable HR mapping under limited annotation and compute budgets. The code is available at https://github.com/rikirikirikiriki/MapSR.
One-Step Face Restoration via Shortcut-Enhanced Coupling Flow
Mar 04, 2026Face restoration has advanced significantly with generative models like diffusion models and flow matching (FM), which learn continuous-time mappings between distributions. However, existing FM-based approaches often start from Gaussian noise, ignoring the inherent dependency between low-quality (LQ) and high-quality (HQ) data, resulting in path crossovers, curved trajectories, and multi-step sampling requirements. To address these issues, we propose Shortcut-enhanced Coupling flow for Face Restoration (SCFlowFR). First, it establishes a \textit{data-dependent coupling} that explicitly models the LQ--HQ dependency, minimizing path crossovers and promoting near-linear transport. Second, we employ conditional mean estimation to obtain a coarse prediction that refines the source anchor to tighten coupling and conditions the velocity field to stabilize large-step updates. Third, a shortcut constraint supervises average velocities over arbitrary time intervals, enabling accurate one-step inference. Experiments demonstrate that SCFlowFR achieves state-of-the-art one-step face restoration quality with inference speed comparable to traditional non-diffusion methods.
CUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation
Feb 27, 2026GPU kernel optimization is fundamental to modern deep learning but remains a highly specialized task requiring deep hardware expertise. Despite strong performance in general programming, large language models (LLMs) remain uncompetitive with compiler-based systems such as torch.compile for CUDA kernel generation. Existing CUDA code generation approaches either rely on training-free refinement or fine-tune models within fixed multi-turn execution-feedback loops, but both paradigms fail to fundamentally improve the model's intrinsic CUDA optimization ability, resulting in limited performance gains. We present CUDA Agent, a large-scale agentic reinforcement learning system that develops CUDA kernel expertise through three components: a scalable data synthesis pipeline, a skill-augmented CUDA development environment with automated verification and profiling to provide reliable reward signals, and reinforcement learning algorithmic techniques enabling stable training. CUDA Agent achieves state-of-the-art results on KernelBench, delivering 100\%, 100\%, and 92\% faster rate over torch.compile on KernelBench Level-1, Level-2, and Level-3 splits, outperforming the strongest proprietary models such as Claude Opus 4.5 and Gemini 3 Pro by about 40\% on the hardest Level-3 setting.
SUG-Occ: An Explicit Semantics and Uncertainty Guided Sparse Learning Framework for Real-Time 3D Occupancy Prediction
Jan 16, 2026As autonomous driving moves toward full scene understanding, 3D semantic occupancy prediction has emerged as a crucial perception task, offering voxel-level semantics beyond traditional detection and segmentation paradigms. However, such a refined representation for scene understanding incurs prohibitive computation and memory overhead, posing a major barrier to practical real-time deployment. To address this, we propose SUG-Occ, an explicit Semantics and Uncertainty Guided Sparse Learning Enabled 3D Occupancy Prediction Framework, which exploits the inherent sparsity of 3D scenes to reduce redundant computation while maintaining geometric and semantic completeness. Specifically, we first utilize semantic and uncertainty priors to suppress projections from free space during view transformation while employing an explicit unsigned distance encoding to enhance geometric consistency, producing a structurally consistent sparse 3D representation. Secondly, we design an cascade sparse completion module via hyper cross sparse convolution and generative upsampling to enable efficiently coarse-to-fine reasoning. Finally, we devise an object contextual representation (OCR) based mask decoder that aggregates global semantic context from sparse features and refines voxel-wise predictions via lightweight query-context interactions, avoiding expensive attention operations over volumetric features. Extensive experiments on SemanticKITTI benchmark demonstrate that the proposed approach outperforms the baselines, achieving a 7.34/% improvement in accuracy and a 57.8\% gain in efficiency.
DeltaVLM: Interactive Remote Sensing Image Change Analysis via Instruction-guided Difference Perception
Jul 30, 2025Accurate interpretation of land-cover changes in multi-temporal satellite imagery is critical for real-world scenarios. However, existing methods typically provide only one-shot change masks or static captions, limiting their ability to support interactive, query-driven analysis. In this work, we introduce remote sensing image change analysis (RSICA) as a new paradigm that combines the strengths of change detection and visual question answering to enable multi-turn, instruction-guided exploration of changes in bi-temporal remote sensing images. To support this task, we construct ChangeChat-105k, a large-scale instruction-following dataset, generated through a hybrid rule-based and GPT-assisted process, covering six interaction types: change captioning, classification, quantification, localization, open-ended question answering, and multi-turn dialogues. Building on this dataset, we propose DeltaVLM, an end-to-end architecture tailored for interactive RSICA. DeltaVLM features three innovations: (1) a fine-tuned bi-temporal vision encoder to capture temporal differences; (2) a visual difference perception module with a cross-semantic relation measuring (CSRM) mechanism to interpret changes; and (3) an instruction-guided Q-former to effectively extract query-relevant difference information from visual changes, aligning them with textual instructions. We train DeltaVLM on ChangeChat-105k using a frozen large language model, adapting only the vision and alignment modules to optimize efficiency. Extensive experiments and ablation studies demonstrate that DeltaVLM achieves state-of-the-art performance on both single-turn captioning and multi-turn interactive change analysis, outperforming existing multimodal large language models and remote sensing vision-language models. Code, dataset and pre-trained weights are available at https://github.com/hanlinwu/DeltaVLM.
Distinct social-linguistic processing between humans and large audio-language models: Evidence from model-brain alignment
Mar 25, 2025



Voice-based AI development faces unique challenges in processing both linguistic and paralinguistic information. This study compares how large audio-language models (LALMs) and humans integrate speaker characteristics during speech comprehension, asking whether LALMs process speaker-contextualized language in ways that parallel human cognitive mechanisms. We compared two LALMs' (Qwen2-Audio and Ultravox 0.5) processing patterns with human EEG responses. Using surprisal and entropy metrics from the models, we analyzed their sensitivity to speaker-content incongruency across social stereotype violations (e.g., a man claiming to regularly get manicures) and biological knowledge violations (e.g., a man claiming to be pregnant). Results revealed that Qwen2-Audio exhibited increased surprisal for speaker-incongruent content and its surprisal values significantly predicted human N400 responses, while Ultravox 0.5 showed limited sensitivity to speaker characteristics. Importantly, neither model replicated the human-like processing distinction between social violations (eliciting N400 effects) and biological violations (eliciting P600 effects). These findings reveal both the potential and limitations of current LALMs in processing speaker-contextualized language, and suggest differences in social-linguistic processing mechanisms between humans and LALMs.
Single-Step Latent Consistency Model for Remote Sensing Image Super-Resolution
Mar 25, 2025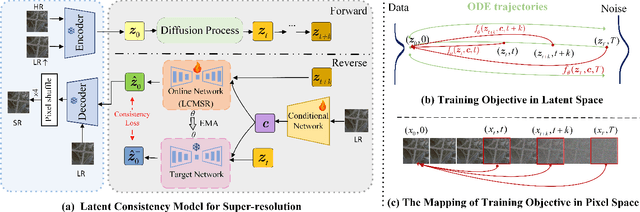
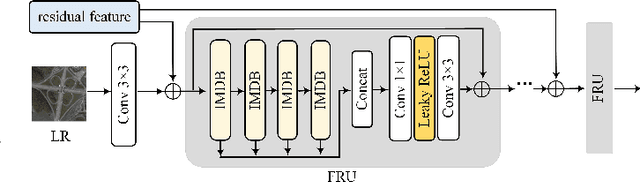

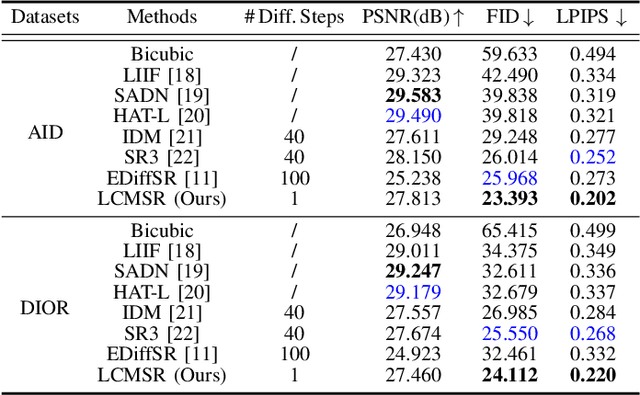
Recent advancements in diffusion models (DMs) have greatly advanced remote sensing image super-resolution (RSISR). However, their iterative sampling processes often result in slow inference speeds, limiting their application in real-time tasks. To address this challenge, we propose the latent consistency model for super-resolution (LCMSR), a novel single-step diffusion approach designed to enhance both efficiency and visual quality in RSISR tasks. Our proposal is structured into two distinct stages. In the first stage, we pretrain a residual autoencoder to encode the differential information between high-resolution (HR) and low-resolution (LR) images, transitioning the diffusion process into a latent space to reduce computational costs. The second stage focuses on consistency diffusion learning, which aims to learn the distribution of residual encodings in the latent space, conditioned on LR images. The consistency constraint enforces that predictions at any two timesteps along the reverse diffusion trajectory remain consistent, enabling direct mapping from noise to data. As a result, the proposed LCMSR reduces the iterative steps of traditional diffusion models from 50-1000 or more to just a single step, significantly improving efficiency. Experimental results demonstrate that LCMSR effectively balances efficiency and performance, achieving inference times comparable to non-diffusion models while maintaining high-quality output.
A Periodic Bayesian Flow for Material Generation
Feb 04, 2025



Generative modeling of crystal data distribution is an important yet challenging task due to the unique periodic physical symmetry of crystals. Diffusion-based methods have shown early promise in modeling crystal distribution. More recently, Bayesian Flow Networks were introduced to aggregate noisy latent variables, resulting in a variance-reduced parameter space that has been shown to be advantageous for modeling Euclidean data distributions with structural constraints (Song et al., 2023). Inspired by this, we seek to unlock its potential for modeling variables located in non-Euclidean manifolds e.g. those within crystal structures, by overcoming challenging theoretical issues. We introduce CrysBFN, a novel crystal generation method by proposing a periodic Bayesian flow, which essentially differs from the original Gaussian-based BFN by exhibiting non-monotonic entropy dynamics. To successfully realize the concept of periodic Bayesian flow, CrysBFN integrates a new entropy conditioning mechanism and empirically demonstrates its significance compared to time-conditioning. Extensive experiments over both crystal ab initio generation and crystal structure prediction tasks demonstrate the superiority of CrysBFN, which consistently achieves new state-of-the-art on all benchmarks. Surprisingly, we found that CrysBFN enjoys a significant improvement in sampling efficiency, e.g., ~100x speedup 10 v.s. 2000 steps network forwards) compared with previous diffusion-based methods on MP-20 dataset. Code is available at https://github.com/wu-han-lin/CrysBFN.
Probabilistic adaptation of language comprehension for individual speakers: Evidence from neural oscillations
Feb 03, 2025Listeners adapt language comprehension based on their mental representations of speakers, but how these representations are dynamically updated remains unclear. We investigated whether listeners probabilistically adapt their comprehension based on the likelihood of speakers producing stereotype-incongruent utterances. Our findings reveal two potential mechanisms: a speaker-general mechanism that adjusts overall expectations about speaker-content relationships, and a speaker-specific mechanism that updates individual speaker models. In two EEG experiments, participants heard speakers make stereotype-congruent or incongruent utterances, with incongruency base rate manipulated between blocks. In Experiment 1, speaker incongruency modulated both high-beta (21-30 Hz) and theta (4-6 Hz) oscillations: incongruent utterances decreased oscillatory power in low base rate condition but increased it in high base rate condition. The theta effect varied with listeners' openness trait: less open participants showed theta increases to speaker-incongruencies, suggesting maintenance of speaker-specific information, while more open participants showed theta decreases, indicating flexible model updating. In Experiment 2, we dissociated base rate from the target speaker by manipulating the overall base rate using an alternative non-target speaker. Only the high-beta effect persisted, showing power decrease for speaker-incongruencies in low base rate condition but no effect in high base rate condition. The high-beta oscillations might reflect the speaker-general adjustment, while theta oscillations may index the speaker-specific model updating. These findings provide evidence for how language processing is shaped by social cognition in real time.