 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Stepless Super-Resolution of Remote Sensing Images via Saliency-Aware Dynamic Routing Strategy
Oct 14, 2022
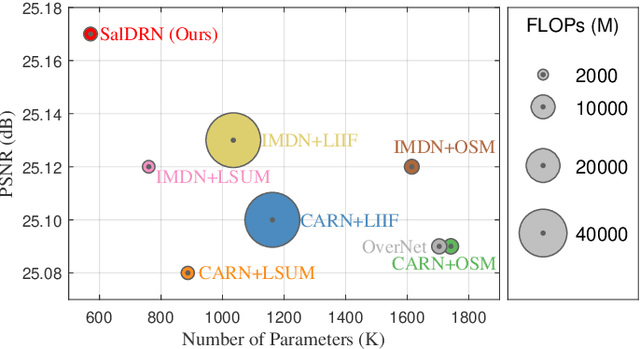


Deep learning-based algorithms have greatly improved the performance of remote sensing image (RSI) super-resolution (SR). However, increasing network depth and parameters cause a huge burden of computing and storage. Directly reducing the depth or width of existing models results in a large performance drop. We observe that the SR difficulty of different regions in an RSI varies greatly, and existing methods use the same deep network to process all regions in an image, resulting in a waste of computing resources. In addition, existing SR methods generally predefine integer scale factors and cannot perform stepless SR, i.e., a single model can deal with any potential scale factor. Retraining the model on each scale factor wastes considerable computing resources and model storage space. To address the above problems, we propose a saliency-aware dynamic routing network (SalDRN) for lightweight and stepless SR of RSIs. First, we introduce visual saliency as an indicator of region-level SR difficulty and integrate a lightweight saliency detector into the SalDRN to capture pixel-level visual characteristics. Then, we devise a saliency-aware dynamic routing strategy that employs path selection switches to adaptively select feature extraction paths of appropriate depth according to the SR difficulty of sub-image patches. Finally, we propose a novel lightweight stepless upsampling module whose core is an implicit feature function for realizing mapping from low-resolution feature space to high-resolution feature space. Comprehensive experiments verify that the SalDRN can achieve a good trade-off between performance and complexity. The code is available at \url{https://github.com/hanlinwu/SalDRN}.
Blind Super-Resolution for Remote Sensing Images via Conditional Stochastic Normalizing Flows
Oct 14, 2022
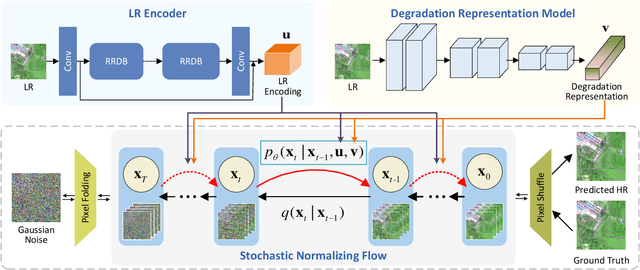
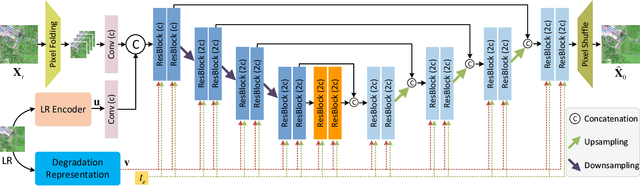
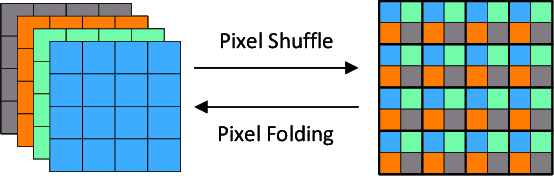
Remote sensing images (RSIs) in real scenes may be disturbed by multiple factors such as optical blur, undersampling, and additional noise, resulting in complex and diverse degradation models. At present, the mainstream SR algorithms only consider a single and fixed degradation (such as bicubic interpolation) and cannot flexibly handle complex degradations in real scenes. Therefore, designing a super-resolution (SR) model that can cope with various degradations is gradually attracting the attention of researchers. Some studies first estimate the degradation kernels and then perform degradation-adaptive SR but face the problems of estimation error amplification and insufficient high-frequency details in the results. Although blind SR algorithms based on generative adversarial networks (GAN) have greatly improved visual quality, they still suffer from pseudo-texture, mode collapse, and poor training stability. In this article, we propose a novel blind SR framework based on the stochastic normalizing flow (BlindSRSNF) to address the above problems. BlindSRSNF learns the conditional probability distribution over the high-resolution image space given a low-resolution (LR) image by explicitly optimizing the variational bound on the likelihood. BlindSRSNF is easy to train and can generate photo-realistic SR results that outperform GAN-based models. Besides, we introduce a degradation representation strategy based on contrastive learning to avoid the error amplification problem caused by the explicit degradation estimation. Comprehensive experiments show that the proposed algorithm can obtain SR results with excellent visual perception quality on both simulated LR and real-world RSIs.
Scale-Aware Dynamic Network for Continuous-Scale Super-Resolution
Oct 29, 2021
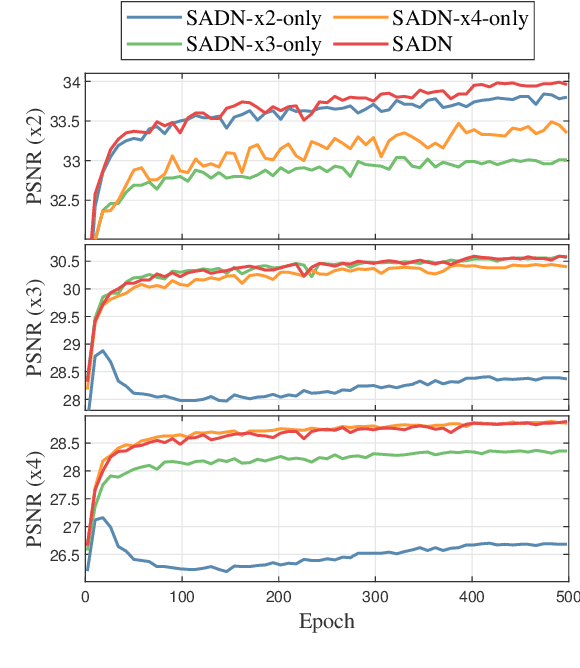


Single-image super-resolution (SR) with fixed and discrete scale factors has achieved great progress due to the development of deep learning technology. However, the continuous-scale SR, which aims to use a single model to process arbitrary (integer or non-integer) scale factors, is still a challenging task. The existing SR models generally adopt static convolution to extract features, and thus unable to effectively perceive the change of scale factor, resulting in limited generalization performance on multi-scale SR tasks. Moreover, the existing continuous-scale upsampling modules do not make full use of multi-scale features and face problems such as checkerboard artifacts in the SR results and high computational complexity. To address the above problems, we propose a scale-aware dynamic network (SADN) for continuous-scale SR. First, we propose a scale-aware dynamic convolutional (SAD-Conv) layer for the feature learning of multiple SR tasks with various scales. The SAD-Conv layer can adaptively adjust the attention weights of multiple convolution kernels based on the scale factor, which enhances the expressive power of the model with a negligible extra computational cost. Second, we devise a continuous-scale upsampling module (CSUM) with the multi-bilinear local implicit function (MBLIF) for any-scale upsampling. The CSUM constructs multiple feature spaces with gradually increasing scales to approximate the continuous feature representation of an image, and then the MBLIF makes full use of multi-scale features to map arbitrary coordinates to RGB values in high-resolution space. We evaluate our SADN using various benchmarks. The experimental results show that the CSUM can replace the previous fixed-scale upsampling layers and obtain a continuous-scale SR network while maintaining performance. Our SADN uses much fewer parameters and outperforms the state-of-the-art SR methods.