 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Step Latent Consistency Model for Remote Sensing Image Super-Resolution
Mar 25, 2025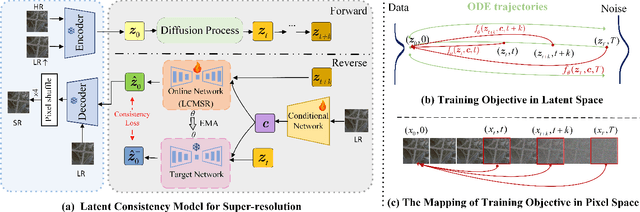

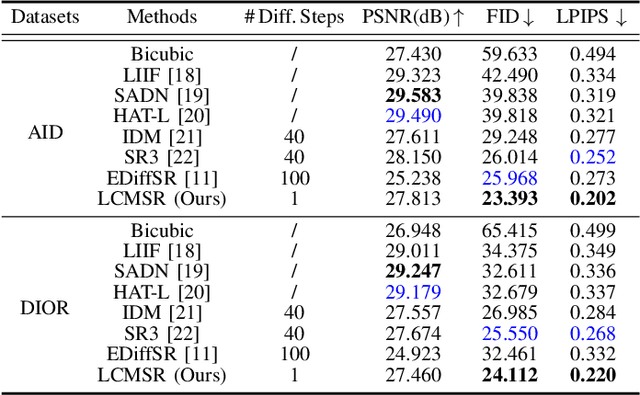
Recent advancements in diffusion models (DMs) have greatly advanced remote sensing image super-resolution (RSISR). However, their iterative sampling processes often result in slow inference speeds, limiting their application in real-time tasks. To address this challenge, we propose the latent consistency model for super-resolution (LCMSR), a novel single-step diffusion approach designed to enhance both efficiency and visual quality in RSISR tasks. Our proposal is structured into two distinct stages. In the first stage, we pretrain a residual autoencoder to encode the differential information between high-resolution (HR) and low-resolution (LR) images, transitioning the diffusion process into a latent space to reduce computational costs. The second stage focuses on consistency diffusion learning, which aims to learn the distribution of residual encodings in the latent space, conditioned on LR images. The consistency constraint enforces that predictions at any two timesteps along the reverse diffusion trajectory remain consistent, enabling direct mapping from noise to data. As a result, the proposed LCMSR reduces the iterative steps of traditional diffusion models from 50-1000 or more to just a single step, significantly improving efficiency. Experimental results demonstrate that LCMSR effectively balances efficiency and performance, achieving inference times comparable to non-diffusion models while maintaining high-quality output.
Latent Diffusion, Implicit Amplification: Efficient Continuous-Scale Super-Resolution for Remote Sensing Images
Oct 30, 2024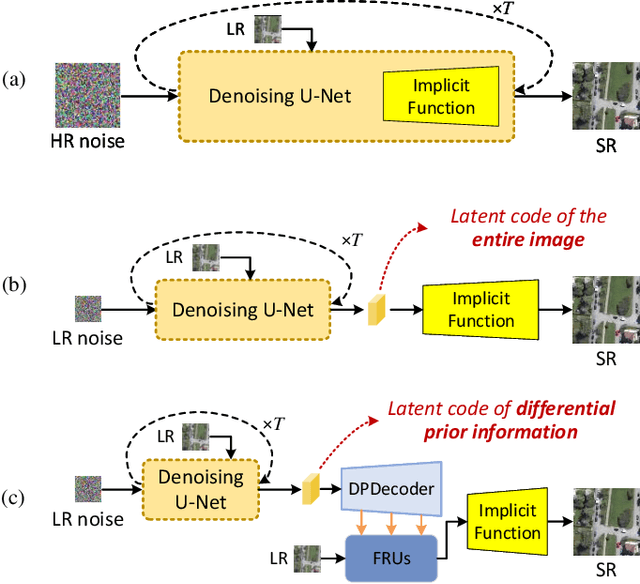
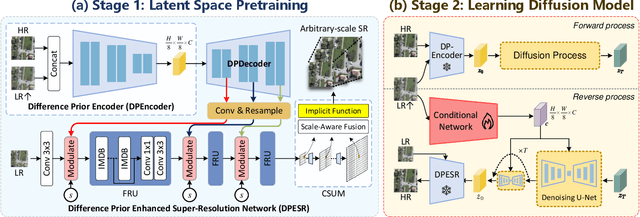
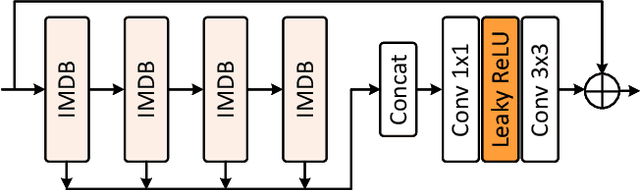
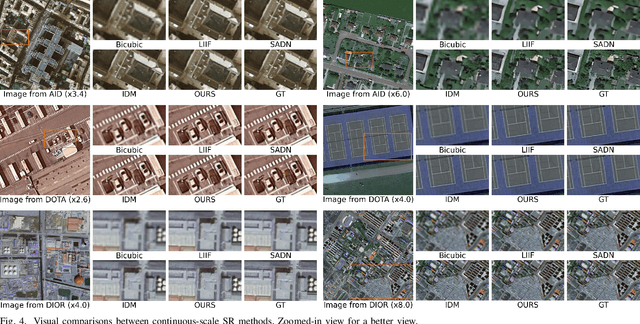
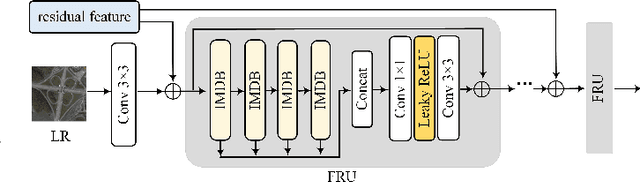
Recent advancements in diffusion models have significantly improved performance in super-resolution (SR) tasks. However, previous research often overlooks the fundamental differences between SR and general image generation. General image generation involves creating images from scratch, while SR focuses specifically on enhancing existing low-resolution (LR) images by adding typically missing high-frequency details. This oversight not only increases the training difficulty but also limits their inference efficiency. Furthermore, previous diffusion-based SR methods are typically trained and inferred at fixed integer scale factors, lacking flexibility to meet the needs of up-sampling with non-integer scale factors. To address these issues, this paper proposes an efficient and elastic diffusion-based SR model (E$^2$DiffSR), specially designed for continuous-scale SR in remote sensing imagery. E$^2$DiffSR employs a two-stage latent diffusion paradigm. During the first stage, an autoencoder is trained to capture the differential priors between high-resolution (HR) and LR images. The encoder intentionally ignores the existing LR content to alleviate the encoding burden, while the decoder introduces an SR branch equipped with a continuous scale upsampling module to accomplish the reconstruction under the guidance of the differential prior. In the second stage, a conditional diffusion model is learned within the latent space to predict the true differential prior encoding. Experimental results demonstrate that E$^2$DiffSR achieves superior objective metrics and visual quality compared to the state-of-the-art SR methods. Additionally, it reduces the inference time of diffusion-based SR methods to a level comparable to that of non-diffusion methods.