 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHLB: Benchmarking LLMs' Humanlikeness in Language Use
Paper and Code
Sep 24, 2024
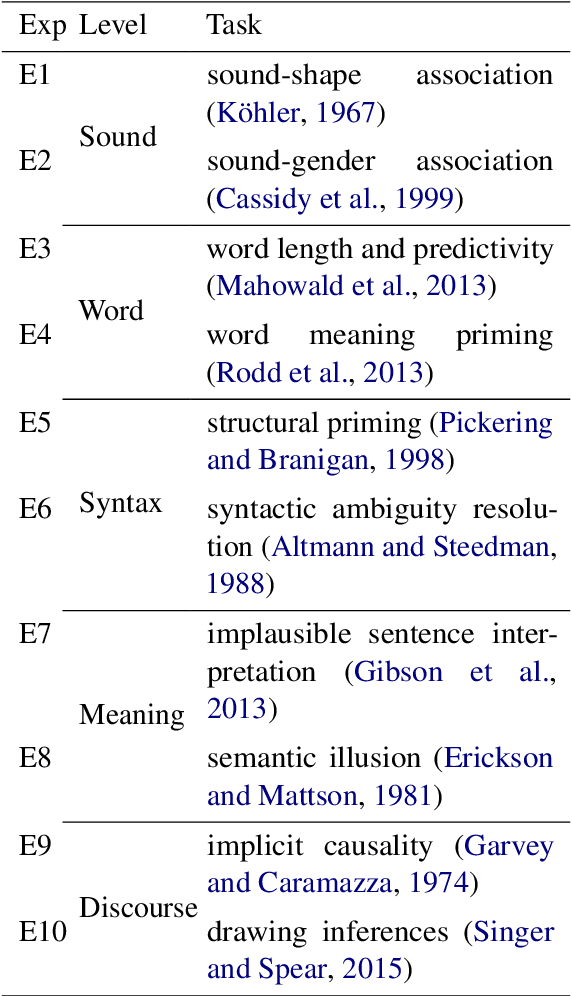
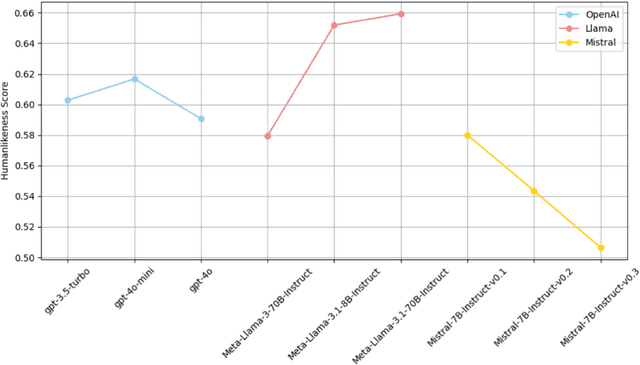
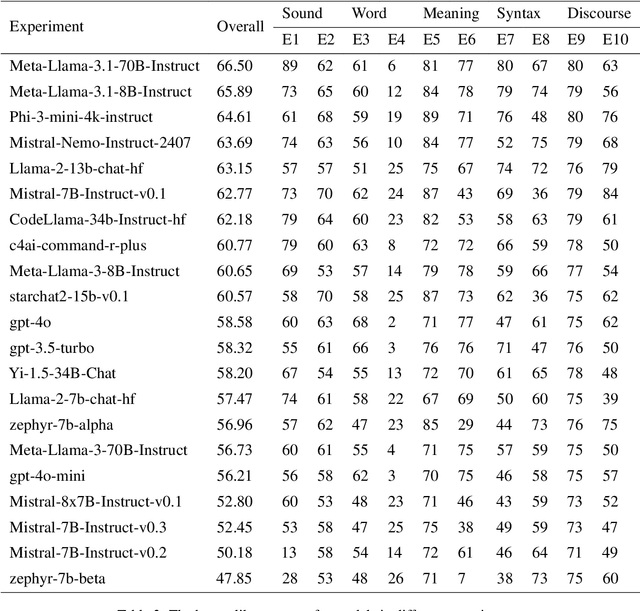
As synthetic data becomes increasingly prevalent in training language models, particularly through generated dialogue, concerns have emerged that these models may deviate from authentic human language patterns, potentially losing the richness and creativity inherent in human communication. This highlights the critical need to assess the humanlikeness of language models in real-world language use. In this paper, we present a comprehensive humanlikeness benchmark (HLB) evaluating 20 large language models (LLMs) using 10 psycholinguistic experiments designed to probe core linguistic aspects, including sound, word, syntax, semantics, and discourse (see https://huggingface.co/spaces/XufengDuan/HumanLikeness). To anchor these comparisons, we collected responses from over 2,000 human participants and compared them to outputs from the LLMs in these experiments. For rigorous evaluation, we developed a coding algorithm that accurately identified language use patterns, enabling the extraction of response distributions for each task. By comparing the response distributions between human participants and LLMs, we quantified humanlikeness through distributional similarity. Our results reveal fine-grained differences in how well LLMs replicate human responses across various linguistic levels. Importantly, we found that improvements in other performance metrics did not necessarily lead to greater humanlikeness, and in some cases, even resulted in a decline. By introducing psycholinguistic methods to model evaluation, this benchmark offers the first framework for systematically assessing the humanlikeness of LLMs in language use.