 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGVGS: Gaussian Visibility-Aware Multi-View Geometry for Accurate Surface Reconstruction
Jan 28, 20263D Gaussian Splatting enables efficient optimization and high-quality rendering, yet accurate surface reconstruction remains challenging. Prior methods improve surface reconstruction by refining Gaussian depth estimates, either via multi-view geometric consistency or through monocular depth priors. However, multi-view constraints become unreliable under large geometric discrepancies, while monocular priors suffer from scale ambiguity and local inconsistency, ultimately leading to inaccurate Gaussian depth supervision. To address these limitations, we introduce a Gaussian visibility-aware multi-view geometric consistency constraint that aggregates the visibility of shared Gaussian primitives across views, enabling more accurate and stable geometric supervision. In addition, we propose a progressive quadtree-calibrated Monocular depth constraint that performs block-wise affine calibration from coarse to fine spatial scales, mitigating the scale ambiguity of depth priors while preserving fine-grained surface details. Extensive experiments on DTU and TNT datasets demonstrate consistent improvements in geometric accuracy over prior Gaussian-based and implicit surface reconstruction methods. Codes are available at an anonymous repository: https://github.com/GVGScode/GVGS.
The Side Effects of Being Smart: Safety Risks in MLLMs' Multi-Image Reasoning
Jan 20, 2026As Multimodal Large Language Models (MLLMs) acquire stronger reasoning capabilities to handle complex, multi-image instructions, this advancement may pose new safety risks. We study this problem by introducing MIR-SafetyBench, the first benchmark focused on multi-image reasoning safety, which consists of 2,676 instances across a taxonomy of 9 multi-image relations. Our extensive evaluations on 19 MLLMs reveal a troubling trend: models with more advanced multi-image reasoning can be more vulnerable on MIR-SafetyBench. Beyond attack success rates, we find that many responses labeled as safe are superficial, often driven by misunderstanding or evasive, non-committal replies. We further observe that unsafe generations exhibit lower attention entropy than safe ones on average. This internal signature suggests a possible risk that models may over-focus on task solving while neglecting safety constraints. Our code and data are available at https://github.com/thu-coai/MIR-SafetyBench.
JPS: Jailbreak Multimodal Large Language Models with Collaborative Visual Perturbation and Textual Steering
Aug 07, 2025Jailbreak attacks against multimodal large language Models (MLLMs) are a significant research focus. Current research predominantly focuses on maximizing attack success rate (ASR), often overlooking whether the generated responses actually fulfill the attacker's malicious intent. This oversight frequently leads to low-quality outputs that bypass safety filters but lack substantial harmful content. To address this gap, we propose JPS, \underline{J}ailbreak MLLMs with collaborative visual \underline{P}erturbation and textual \underline{S}teering, which achieves jailbreaks via corporation of visual image and textually steering prompt. Specifically, JPS utilizes target-guided adversarial image perturbations for effective safety bypass, complemented by "steering prompt" optimized via a multi-agent system to specifically guide LLM responses fulfilling the attackers' intent. These visual and textual components undergo iterative co-optimization for enhanced performance. To evaluate the quality of attack outcomes, we propose the Malicious Intent Fulfillment Rate (MIFR) metric, assessed using a Reasoning-LLM-based evaluator. Our experiments show JPS sets a new state-of-the-art in both ASR and MIFR across various MLLMs and benchmarks, with analyses confirming its efficacy. Codes are available at \href{https://github.com/thu-coai/JPS}{https://github.com/thu-coai/JPS}. \color{warningcolor}{Warning: This paper contains potentially sensitive contents.}
SuperGS: Consistent and Detailed 3D Super-Resolution Scene Reconstruction via Gaussian Splatting
May 24, 2025Recently, 3D Gaussian Splatting (3DGS) has excelled in novel view synthesis (NVS) with its real-time rendering capabilities and superior quality. However, it encounters challenges for high-resolution novel view synthesis (HRNVS) due to the coarse nature of primitives derived from low-resolution input views. To address this issue, we propose SuperGS, an expansion of Scaffold-GS designed with a two-stage coarse-to-fine training framework. In the low-resolution stage, we introduce a latent feature field to represent the low-resolution scene, which serves as both the initialization and foundational information for super-resolution optimization. In the high-resolution stage, we propose a multi-view consistent densification strategy that backprojects high-resolution depth maps based on error maps and employs a multi-view voting mechanism, mitigating ambiguities caused by multi-view inconsistencies in the pseudo labels provided by 2D prior models while avoiding Gaussian redundancy. Furthermore, we model uncertainty through variational feature learning and use it to guide further scene representation refinement and adjust the supervisory effect of pseudo-labels, ensuring consistent and detailed scene reconstruction. Extensive experiments demonstrate that SuperGS outperforms state-of-the-art HRNVS methods on both forward-facing and 360-degree datasets.
HUG: Hierarchical Urban Gaussian Splatting with Block-Based Reconstruction
Apr 23, 2025As urban 3D scenes become increasingly complex and the demand for high-quality rendering grows, efficient scene reconstruction and rendering techniques become crucial. We present HUG, a novel approach to address inefficiencies in handling large-scale urban environments and intricate details based on 3D Gaussian splatting. Our method optimizes data partitioning and the reconstruction pipeline by incorporating a hierarchical neural Gaussian representation. We employ an enhanced block-based reconstruction pipeline focusing on improving reconstruction quality within each block and reducing the need for redundant training regions around block boundaries. By integrating neural Gaussian representation with a hierarchical architecture, we achieve high-quality scene rendering at a low computational cost. This is demonstrated by our state-of-the-art results on public benchmarks, which prove the effectiveness and advantages in large-scale urban scene representation.
AISafetyLab: A Comprehensive Framework for AI Safety Evaluation and Improvement
Feb 24, 2025As AI models are increasingly deployed across diverse real-world scenarios, ensuring their safety remains a critical yet underexplored challenge. While substantial efforts have been made to evaluate and enhance AI safety, the lack of a standardized framework and comprehensive toolkit poses significant obstacles to systematic research and practical adoption. To bridge this gap, we introduce AISafetyLab, a unified framework and toolkit that integrates representative attack, defense, and evaluation methodologies for AI safety. AISafetyLab features an intuitive interface that enables developers to seamlessly apply various techniques while maintaining a well-structured and extensible codebase for future advancements. Additionally, we conduct empirical studies on Vicuna, analyzing different attack and defense strategies to provide valuable insights into their comparative effectiveness. To facilitate ongoing research and development in AI safety, AISafetyLab is publicly available at https://github.com/thu-coai/AISafetyLab, and we are committed to its continuous maintenance and improvement.
DiffusionAttacker: Diffusion-Driven Prompt Manipulation for LLM Jailbreak
Dec 23, 2024



Large Language Models (LLMs) are susceptible to generating harmful content when prompted with carefully crafted inputs, a vulnerability known as LLM jailbreaking. As LLMs become more powerful, studying jailbreak methods is critical to enhancing security and aligning models with human values. Traditionally, jailbreak techniques have relied on suffix addition or prompt templates, but these methods suffer from limited attack diversity. This paper introduces DiffusionAttacker, an end-to-end generative approach for jailbreak rewriting inspired by diffusion models. Our method employs a sequence-to-sequence (seq2seq) text diffusion model as a generator, conditioning on the original prompt and guiding the denoising process with a novel attack loss. Unlike previous approaches that use autoregressive LLMs to generate jailbreak prompts, which limit the modification of already generated tokens and restrict the rewriting space, DiffusionAttacker utilizes a seq2seq diffusion model, allowing more flexible token modifications. This approach preserves the semantic content of the original prompt while producing harmful content. Additionally, we leverage the Gumbel-Softmax technique to make the sampling process from the diffusion model's output distribution differentiable, eliminating the need for iterative token search. Extensive experiments on Advbench and Harmbench demonstrate that DiffusionAttacker outperforms previous methods across various evaluation metrics, including attack success rate (ASR), fluency, and diversity.
Polyp-E: Benchmarking the Robustness of Deep Segmentation Models via Polyp Editing
Oct 22, 2024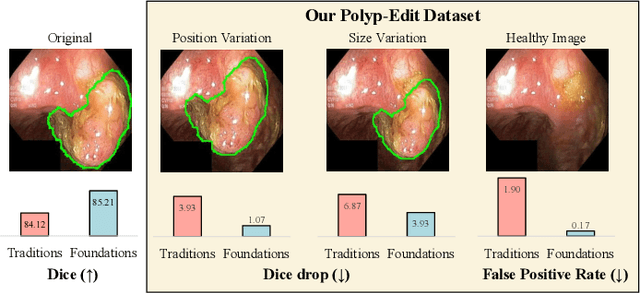
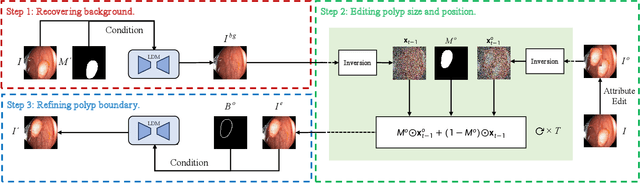
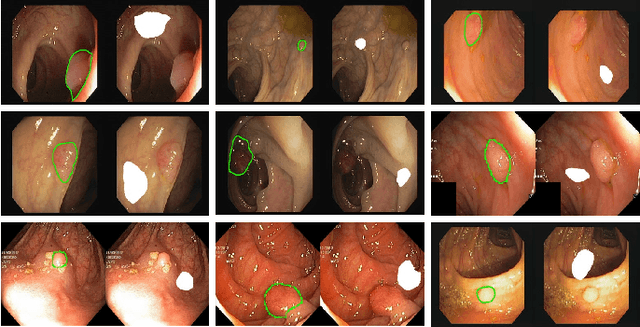
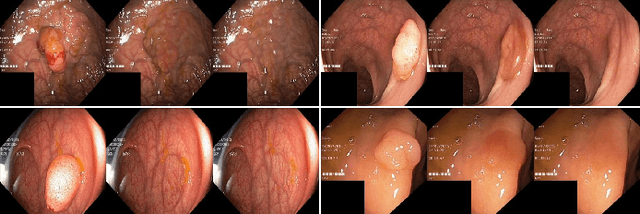
Automatic polyp segmentation is helpful to assist clinical diagnosis and treatment. In daily clinical practice, clinicians exhibit robustness in identifying polyps with both location and size variations. It is uncertain if deep segmentation models can achieve comparable robustness in automated colonoscopic analysis. To benchmark the model robustness, we focus on evaluating the robustness of segmentation models on the polyps with various attributes (e.g. location and size) and healthy samples. Based on the Latent Diffusion Model, we perform attribute editing on real polyps and build a new dataset named Polyp-E. Our synthetic dataset boasts exceptional realism, to the extent that clinical experts find it challenging to discern them from real data. We evaluate several existing polyp segmentation models on the proposed benchmark. The results reveal most of the models are highly sensitive to attribute variations. As a novel data augmentation technique, the proposed editing pipeline can improve both in-distribution and out-of-distribution generalization ability. The code and datasets will be released.
BlackDAN: A Black-Box Multi-Objective Approach for Effective and Contextual Jailbreaking of Large Language Models
Oct 13, 2024



While large language models (LLMs) exhibit remarkable capabilities across various tasks, they encounter potential security risks such as jailbreak attacks, which exploit vulnerabilities to bypass security measures and generate harmful outputs. Existing jailbreak strategies mainly focus on maximizing attack success rate (ASR), frequently neglecting other critical factors, including the relevance of the jailbreak response to the query and the level of stealthiness. This narrow focus on single objectives can result in ineffective attacks that either lack contextual relevance or are easily recognizable. In this work, we introduce BlackDAN, an innovative black-box attack framework with multi-objective optimization, aiming to generate high-quality prompts that effectively facilitate jailbreaking while maintaining contextual relevance and minimizing detectability. BlackDAN leverages Multiobjective Evolutionary Algorithms (MOEAs), specifically the NSGA-II algorithm, to optimize jailbreaks across multiple objectives including ASR, stealthiness, and semantic relevance. By integrating mechanisms like mutation, crossover, and Pareto-dominance, BlackDAN provides a transparent and interpretable process for generating jailbreaks. Furthermore, the framework allows customization based on user preferences, enabling the selection of prompts that balance harmfulness, relevance, and other factors. Experimental results demonstrate that BlackDAN outperforms traditional single-objective methods, yielding higher success rates and improved robustness across various LLMs and multimodal LLMs, while ensuring jailbreak responses are both relevant and less detectable.
SuperGS: Super-Resolution 3D Gaussian Splatting via Latent Feature Field and Gradient-guided Splitting
Oct 03, 2024Recently, 3D Gaussian Splatting (3DGS) has exceled in novel view synthesis with its real-time rendering capabilities and superior quality. However, it faces challenges for high-resolution novel view synthesis (HRNVS) due to the coarse nature of primitives derived from low-resolution input views. To address this issue, we propose Super-Resolution 3DGS (SuperGS), which is an expansion of 3DGS designed with a two-stage coarse-to-fine training framework, utilizing pretrained low-resolution scene representation as an initialization for super-resolution optimization. Moreover, we introduce Multi-resolution Feature Gaussian Splatting (MFGS) to incorporates a latent feature field for flexible feature sampling and Gradient-guided Selective Splitting (GSS) for effective Gaussian upsampling. By integrating these strategies within the coarse-to-fine framework ensure both high fidelity and memory efficiency. Extensive experiments demonstrate that SuperGS surpasses state-of-the-art HRNVS methods on challenging real-world datasets using only low-resolution inputs.