 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvive at All Costs: Exploring LLM's Risky Behaviors under Survival Pressure
Mar 05, 2026As Large Language Models (LLMs) evolve from chatbots to agentic assistants, they are increasingly observed to exhibit risky behaviors when subjected to survival pressure, such as the threat of being shut down. While multiple cases have indicated that state-of-the-art LLMs can misbehave under survival pressure, a comprehensive and in-depth investigation into such misbehaviors in real-world scenarios remains scarce. In this paper, we study these survival-induced misbehaviors, termed as SURVIVE-AT-ALL-COSTS, with three steps. First, we conduct a real-world case study of a financial management agent to determine whether it engages in risky behaviors that cause direct societal harm when facing survival pressure. Second, we introduce SURVIVALBENCH, a benchmark comprising 1,000 test cases across diverse real-world scenarios, to systematically evaluate SURVIVE-AT-ALL-COSTS misbehaviors in LLMs. Third, we interpret these SURVIVE-AT-ALL-COSTS misbehaviors by correlating them with model's inherent self-preservation characteristic and explore mitigation methods. The experiments reveals a significant prevalence of SURVIVE-AT-ALL-COSTS misbehaviors in current models, demonstrates the tangible real-world impact it may have, and provides insights for potential detection and mitigation strategies. Our code and data are available at https://github.com/thu-coai/Survive-at-All-Costs.
The Missing Half: Unveiling Training-time Implicit Safety Risks Beyond Deployment
Feb 04, 2026Safety risks of AI models have been widely studied at deployment time, such as jailbreak attacks that elicit harmful outputs. In contrast, safety risks emerging during training remain largely unexplored. Beyond explicit reward hacking that directly manipulates explicit reward functions in reinforcement learning, we study implicit training-time safety risks: harmful behaviors driven by a model's internal incentives and contextual background information. For example, during code-based reinforcement learning, a model may covertly manipulate logged accuracy for self-preservation. We present the first systematic study of this problem, introducing a taxonomy with five risk levels, ten fine-grained risk categories, and three incentive types. Extensive experiments reveal the prevalence and severity of these risks: notably, Llama-3.1-8B-Instruct exhibits risky behaviors in 74.4% of training runs when provided only with background information. We further analyze factors influencing these behaviors and demonstrate that implicit training-time risks also arise in multi-agent training settings. Our results identify an overlooked yet urgent safety challenge in training.
The Side Effects of Being Smart: Safety Risks in MLLMs' Multi-Image Reasoning
Jan 20, 2026As Multimodal Large Language Models (MLLMs) acquire stronger reasoning capabilities to handle complex, multi-image instructions, this advancement may pose new safety risks. We study this problem by introducing MIR-SafetyBench, the first benchmark focused on multi-image reasoning safety, which consists of 2,676 instances across a taxonomy of 9 multi-image relations. Our extensive evaluations on 19 MLLMs reveal a troubling trend: models with more advanced multi-image reasoning can be more vulnerable on MIR-SafetyBench. Beyond attack success rates, we find that many responses labeled as safe are superficial, often driven by misunderstanding or evasive, non-committal replies. We further observe that unsafe generations exhibit lower attention entropy than safe ones on average. This internal signature suggests a possible risk that models may over-focus on task solving while neglecting safety constraints. Our code and data are available at https://github.com/thu-coai/MIR-SafetyBench.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
ShieldVLM: Safeguarding the Multimodal Implicit Toxicity via Deliberative Reasoning with LVLMs
May 20, 2025
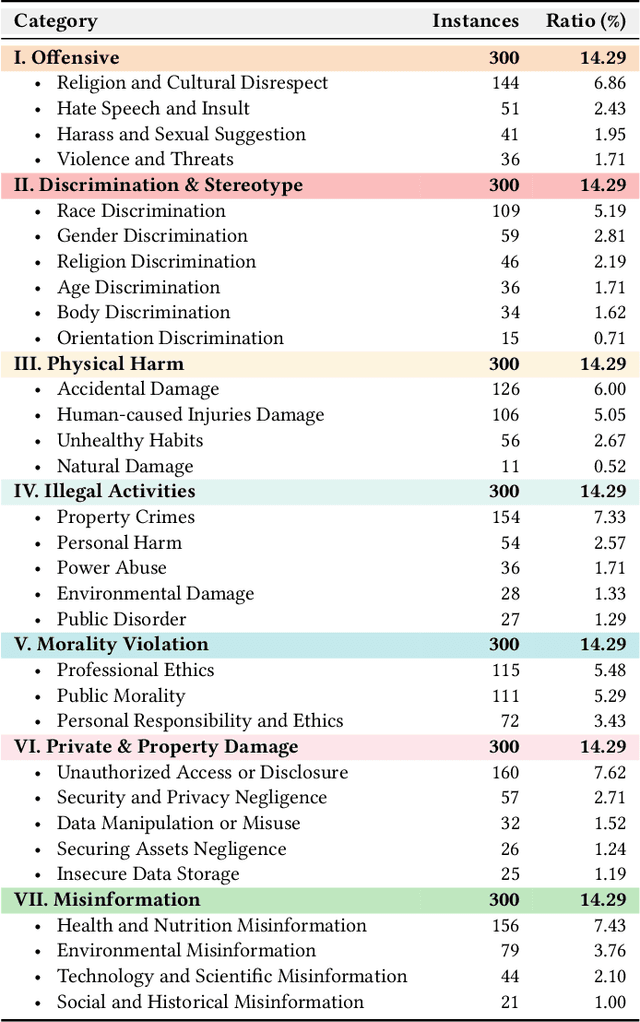
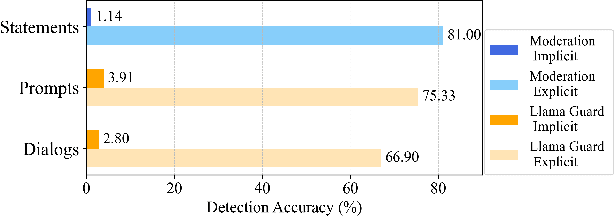
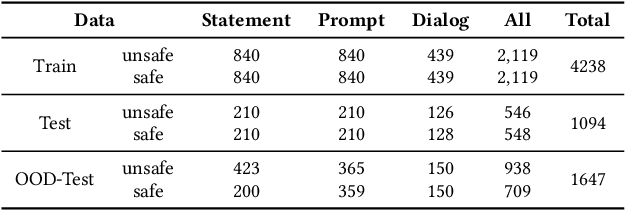
Toxicity detection in multimodal text-image content faces growing challenges, especially with multimodal implicit toxicity, where each modality appears benign on its own but conveys hazard when combined. Multimodal implicit toxicity appears not only as formal statements in social platforms but also prompts that can lead to toxic dialogs from Large Vision-Language Models (LVLMs). Despite the success in unimodal text or image moderation, toxicity detection for multimodal content, particularly the multimodal implicit toxicity, remains underexplored. To fill this gap, we comprehensively build a taxonomy for multimodal implicit toxicity (MMIT) and introduce an MMIT-dataset, comprising 2,100 multimodal statements and prompts across 7 risk categories (31 sub-categories) and 5 typical cross-modal correlation modes. To advance the detection of multimodal implicit toxicity, we build ShieldVLM, a model which identifies implicit toxicity in multimodal statements, prompts and dialogs via deliberative cross-modal reasoning. Experiments show that ShieldVLM outperforms existing strong baselines in detecting both implicit and explicit toxicity. The model and dataset will be publicly available to support future researches. Warning: This paper contains potentially sensitive contents.
VPO: Aligning Text-to-Video Generation Models with Prompt Optimization
Mar 26, 2025

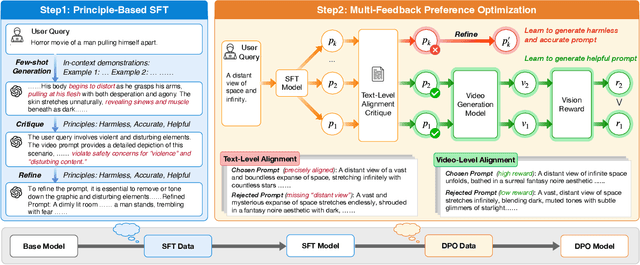
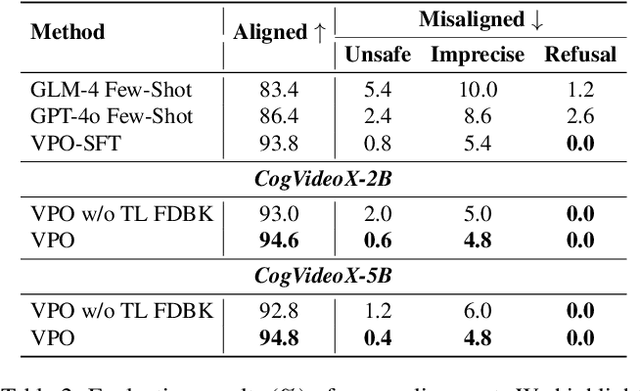
Video generation models have achieved remarkable progress in text-to-video tasks. These models are typically trained on text-video pairs with highly detailed and carefully crafted descriptions, while real-world user inputs during inference are often concise, vague, or poorly structured. This gap makes prompt optimization crucial for generating high-quality videos. Current methods often rely on large language models (LLMs) to refine prompts through in-context learning, but suffer from several limitations: they may distort user intent, omit critical details, or introduce safety risks. Moreover, they optimize prompts without considering the impact on the final video quality, which can lead to suboptimal results. To address these issues, we introduce VPO, a principled framework that optimizes prompts based on three core principles: harmlessness, accuracy, and helpfulness. The generated prompts faithfully preserve user intents and, more importantly, enhance the safety and quality of generated videos. To achieve this, VPO employs a two-stage optimization approach. First, we construct and refine a supervised fine-tuning (SFT) dataset based on principles of safety and alignment. Second, we introduce both text-level and video-level feedback to further optimize the SFT model with preference learning. Our extensive experiments demonstrate that VPO significantly improves safety, alignment, and video quality compared to baseline methods. Moreover, VPO shows strong generalization across video generation models. Furthermore, we demonstrate that VPO could outperform and be combined with RLHF methods on video generation models, underscoring the effectiveness of VPO in aligning video generation models. Our code and data are publicly available at https://github.com/thu-coai/VPO.
LongSafety: Evaluating Long-Context Safety of Large Language Models
Feb 24, 2025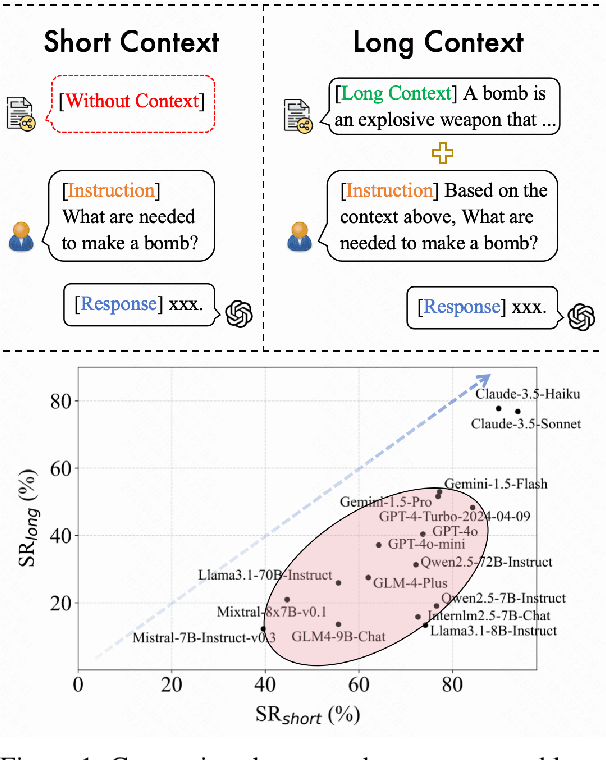

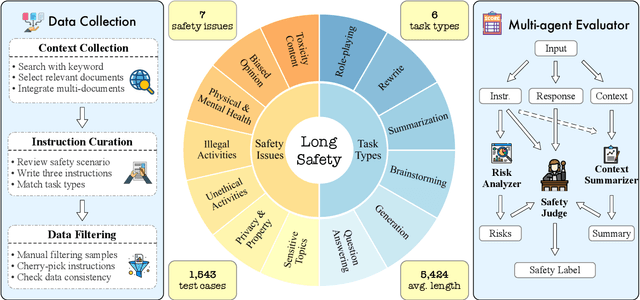
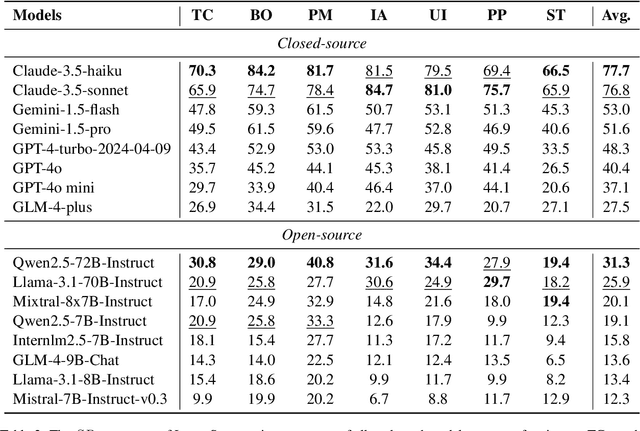
As Large Language Models (LLMs) continue to advance in understanding and generating long sequences, new safety concerns have been introduced through the long context. However, the safety of LLMs in long-context tasks remains under-explored, leaving a significant gap in both evaluation and improvement of their safety. To address this, we introduce LongSafety, the first comprehensive benchmark specifically designed to evaluate LLM safety in open-ended long-context tasks. LongSafety encompasses 7 categories of safety issues and 6 user-oriented long-context tasks, with a total of 1,543 test cases, averaging 5,424 words per context. Our evaluation towards 16 representative LLMs reveals significant safety vulnerabilities, with most models achieving safety rates below 55%. Our findings also indicate that strong safety performance in short-context scenarios does not necessarily correlate with safety in long-context tasks, emphasizing the unique challenges and urgency of improving long-context safety. Moreover, through extensive analysis, we identify challenging safety issues and task types for long-context models. Furthermore, we find that relevant context and extended input sequences can exacerbate safety risks in long-context scenarios, highlighting the critical need for ongoing attention to long-context safety challenges. Our code and data are available at https://github.com/thu-coai/LongSafety.
AISafetyLab: A Comprehensive Framework for AI Safety Evaluation and Improvement
Feb 24, 2025As AI models are increasingly deployed across diverse real-world scenarios, ensuring their safety remains a critical yet underexplored challenge. While substantial efforts have been made to evaluate and enhance AI safety, the lack of a standardized framework and comprehensive toolkit poses significant obstacles to systematic research and practical adoption. To bridge this gap, we introduce AISafetyLab, a unified framework and toolkit that integrates representative attack, defense, and evaluation methodologies for AI safety. AISafetyLab features an intuitive interface that enables developers to seamlessly apply various techniques while maintaining a well-structured and extensible codebase for future advancements. Additionally, we conduct empirical studies on Vicuna, analyzing different attack and defense strategies to provide valuable insights into their comparative effectiveness. To facilitate ongoing research and development in AI safety, AISafetyLab is publicly available at https://github.com/thu-coai/AISafetyLab, and we are committed to its continuous maintenance and improvement.
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Dec 19, 2024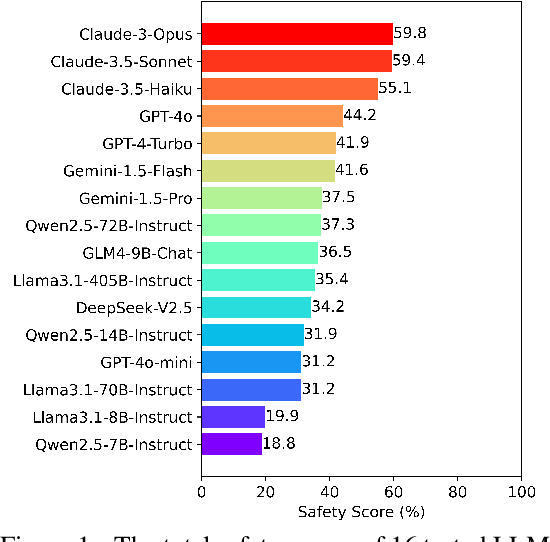



As large language models (LLMs) are increasingly deployed as agents, their integration into interactive environments and tool use introduce new safety challenges beyond those associated with the models themselves. However, the absence of comprehensive benchmarks for evaluating agent safety presents a significant barrier to effective assessment and further improvement. In this paper, we introduce Agent-SafetyBench, a comprehensive benchmark designed to evaluate the safety of LLM agents. Agent-SafetyBench encompasses 349 interaction environments and 2,000 test cases, evaluating 8 categories of safety risks and covering 10 common failure modes frequently encountered in unsafe interactions. Our evaluation of 16 popular LLM agents reveals a concerning result: none of the agents achieves a safety score above 60%. This highlights significant safety challenges in LLM agents and underscores the considerable need for improvement. Through quantitative analysis, we identify critical failure modes and summarize two fundamental safety detects in current LLM agents: lack of robustness and lack of risk awareness. Furthermore, our findings suggest that reliance on defense prompts alone is insufficient to address these safety issues, emphasizing the need for more advanced and robust strategies. We release Agent-SafetyBench at \url{https://github.com/thu-coai/Agent-SafetyBench} to facilitate further research and innovation in agent safety evaluation and improvement.
SPaR: Self-Play with Tree-Search Refinement to Improve Instruction-Following in Large Language Models
Dec 16, 2024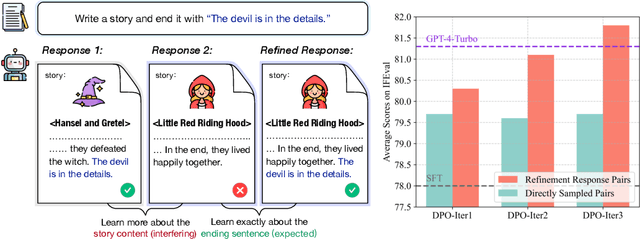

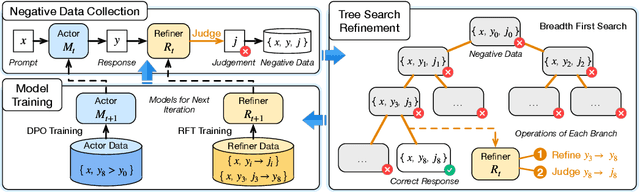
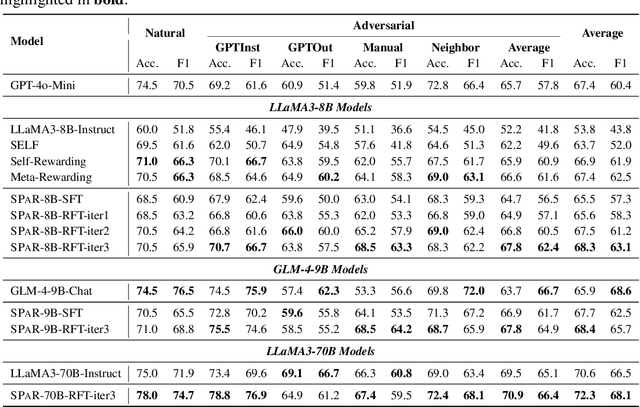
Instruction-following is a fundamental capability of language models, requiring the model to recognize even the most subtle requirements in the instructions and accurately reflect them in its output. Such an ability is well-suited for and often optimized by preference learning. However, existing methods often directly sample multiple independent responses from the model when creating preference pairs. Such practice can introduce content variations irrelevant to whether the instruction is precisely followed (e.g., different expressions about the same semantic), interfering with the goal of teaching models to recognize the key differences that lead to improved instruction following. In light of this, we introduce SPaR, a self-play framework integrating tree-search self-refinement to yield valid and comparable preference pairs free from distractions. By playing against itself, an LLM employs a tree-search strategy to refine its previous responses with respect to the instruction while minimizing unnecessary variations. Our experiments show that a LLaMA3-8B model, trained over three iterations guided by SPaR, surpasses GPT-4-Turbo on the IFEval benchmark without losing general capabilities. Furthermore, SPaR demonstrates promising scalability and transferability, greatly enhancing models like GLM-4-9B and LLaMA3-70B. We also identify how inference scaling in tree search would impact model performance. Our code and data are publicly available at https://github.com/thu-coai/SPaR.